

Amerykańscy naukowcy: Zobacz co z czytelnikami robią nagłówki serwisów technicznych
Szokujące, niesamowite, a jednak - prawie że - prawdziwe. Z pomocą amerykańskich naukowców udało nam się ustalić niesłychane fakty odnośnie tego, jaki wpływ na czytelników mają nagłówki trzech popularnych w Polsce serwisów technicznych.
Cel – dokąd podąża to Metro
Zbadanie, jaka jest relacja między nagłówkami trzech popularnych serwisów technicznych, a faktyczną treścią artykułów i jaki ma to wpływ na czytelników.
Zacznijmy jednak od Faktów
Nagłówek w przyjętej przez nas nomenklaturze to coś więcej niż tylko tytuł artykułu. W języku polskim stosuje się te sformułowania zamiennie, ale na nasze potrzeby rozszerzyliśmy znaczenie nagłówka. Dlaczego?

Sam tytuł to zdecydowanie za mało, aby traktować go jako wyrocznię samej treści. Może być on w końcu przewrotny, zastanawiający, pytający, a nawet posiadać specjalne niedomówienia w celu zachęcenia do dalszego czytania. Rządzi się on tez swoimi prawami jeśli chodzi o składnię i gramatykę. W tytule – który przypominam, nigdy nie kończymy kropką, chyba że to wielokropek – można dowolnie przestawiać szyk, aby uzyskać ciekawy efekt. Celowo też - i jest to praktyka nagminna, korzystamy z równoważników zdań i zdań pojedynczych nierozwiniętych (nie mylić z niedorozwiniętymi autorami niektórych tytułów). Przypominam też, iż pytanie zawarte w tytule nie musi mieć odpowiedzi dosłownej w dalszej części artykułu – w końcu może być tylko hipotezą, której obalenie wynika z głębszej analizy treści.

Podsumowując: według zasad dziennikarskich i dobrego smaku, tytuł nie musi wcale oddawać treści, a ma zachęcać do jej przeczytania.
Co innego lead. Ten powinien zawierać skróconą (max. 4 zdania) informację o tym, co znajdziemy w reszcie artykułu i powinno być to podane właściwie jak przysłowiowa kawa na ławę. W zwykłej gazecie/redakcji/reportażu jest to absolutnie przestrzegane, trochę inaczej ma się to w luźnej publicystyce, gdzie lead ma wciąż zadanie zachęcić i wyjaśnić, ale nie musi on rygorystycznie przestrzegać zasad pełnej informacji. W takim leadzie można postawić pewien problem, który dalsza cześć artykułu/felietonu rozwinie. Może to też być obserwacja, która zostanie przeanalizowana… chodzi ponownie o zachęcenie czytelnika do kliknięcia w „czytaj więcej”.
No i Internet – globalna sieć stron WWW i nie tylko. Obserwując trendy tworzenia stron informacyjnych oraz blogów dziennikarskich, można zauważyć tendencję do zbijania tytułu oraz leadu w jeden byt, który ma zachęcić do dalszego czytania i wyświetla się go z zasady na pierwszej stronie. Powody takiego zachowania pominę (hajs się musi zgadzać!) – chodzi o to, że tak jest i trzeba wziąć to pod uwagę.
Dlatego właśnie w przyjętej na potrzeby tego wpisu nomenklaturze nagłówek to coś więcej niż tytuł.
Korpus – hasło, na pierwszy rzut oka, banalne. W językoznawstwie jest to jednak zbiór tekstów poddawany badaniom lingwistycznym, które w pewien sposób właśnie zamierzamy przeprowadzić. Stąd tez pojęcie korpusu w przyjętej przez nas nomenklaturze jest zbiorem wpisów z popularnych serwisów blogersko/informacyjnych z kategorii informatyczno/techniczno/gadżeciarskiej.
Przejdźmy Ekspresowo do konkretów – metoda badania
A więc, wykorzystując niezwykle zaawansowane technologie wprost z za oceanu – czyli szwagra, który przyleciał z Ameryki – usiadłem i zbadałem korpus składający się z trzech setek nagłówków z trzech różnych portali o tematyce technicznej (AW, SW, DP).
Szwagier czytał nagłówek, następnie czytał treść i zaznaczał:
- haczyk, jeśli teza, pytanie lub informacja w nagłówku pokrywała się z faktyczną treścią artykułu i czytający czuł, iż uzyskał satysfakcjonującą odpowiedź lub informację;
- kreskę, jeśli tylko częściowo można było zestawić ze sobą informacje z nagłówka i treści lub było to bardzo trudne;
- kółko, jeśli nagłówek kompletnie nie odpowiadał informacji jaka została dostarczona przez treść;
Dodatkowo dokonano subiektywnej oceny treści i stylu, która nie miała wpływu na pozostałe oceny.
Ostatnim elementem badania była kategoryzacja artykułów do jednej lub większej ilości kategorii z listy:
- informacja prasowa
- recenzja
- felieton/artykuł
- wywoływanie dyskusji
- hejt dla hejtu
Wykresy i Pudelki
Wyniki – szokujące – zostały następnie przepuszczone przez specjalistów z Polski – szwagra numer dwa – który tylko potwierdził, to co widać na załączonych grafikach.
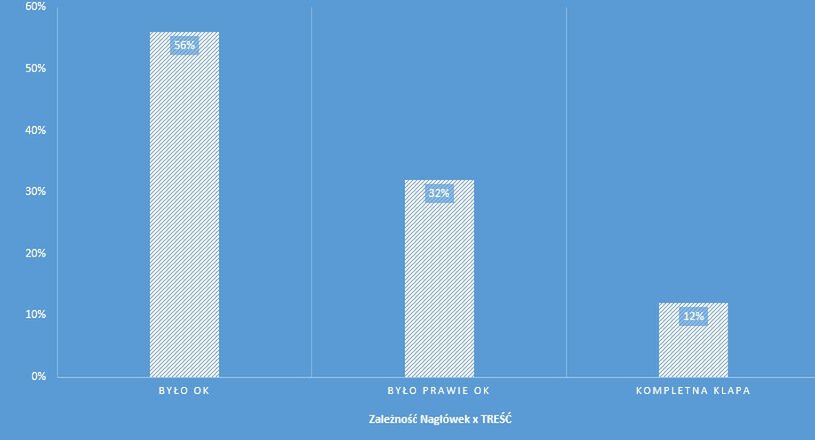
Przeanalizujmy pierwszy wykres – widać na nim jak na dłoni, iż ponad 10% nagłówków rozmijała się kompletnie z treścią – oznacza to, że tezy, pytania lub informacje przedstawione w nagłówkach nie były prawdziwe lub wprowadzały w błąd celowo (lub nie). Nie jest to szokująca liczba – przynajmniej nie jak ta druga – czyli informacja o tym, że 1/3 nagłówków wprowadzała częściowo w błąd, zadawała pytanie, na które nie było jasnej odpowiedzi lub informacja z nagłówka była bardzo mocno ukryta.
Jako przykład tego ostatniego zachowania można przywołać AW:
Tytuł: INSTAGRAM WYCENIANY NA MILIARDY DOLARÓW. GRUBE MILIARDY
Lead: Instagram ostatnio przywoływany był w branżowych mediach m.in. za sprawą przeskoczenia Twittera pod względem liczby użytkowników. Już 300 mln osób korzysta z serwisu, który jakiś czas temu został przejęty przez Facebooka. Imperium Zuckerberga wyłożyło wtedy na stół okrągły miliard dolarów i mogło się wydawać, że to przesada, że trwonią pieniądze. Te komentarze schodzą na dalszy plan, gdy przywoła się dzisiejsze wycena Instagrama.
Informacja o tym na ile wyceniany jest naprawdę Instagram można znaleźć dopiero w trzecim akapicie, wrzuconą w środek zdania jakby od niechcenia i zapamiętanie jej wymaga koncentracji przy czytaniu, gdyż może umknąć… Zamiast tego możemy poznać starą cenę serwisu a także poczytać o tym, dlaczego wydaje się tyle pieniędzy na startupy. Sama treść nie jest zła – chodzi tylko o relacje do nagłówka.
Ostatni słupek na wykresie to wynikająca z poprzednich dwóch informacja, iż ponad połowa nagłówków jest adekwatnych. Są to zarówno nagłówki, które same sprawują się świetnie i nie potrzebują treści by przekazać informacje, jak i nagłówki, które stawiają pytania/tezy, na które uzyskujemy odpowiedzi.
Drugim wykresem jest relacja danej kategorii artykułów/wpisów względem zbadanego korpusu. Ponieważ podczas przyjętej metody badań, szwagier mógł przypisać kilka kategorii do jednego tekstu, ich suma nie składa się na sto procent.
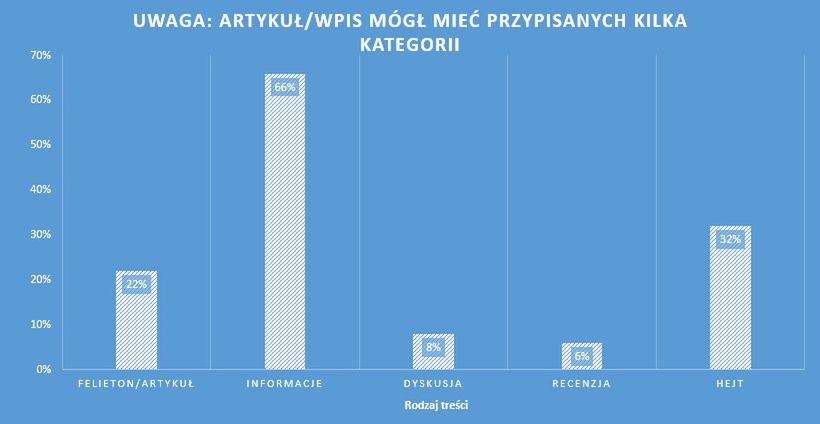
Rozkład jaki można zobaczyć w gruncie rzeczy nie powinien zaskakiwać. Zdecydowana większość tekstów to informacje prasowe podane w schludny i suchy sposób. Felietonów/artykułów można doliczyć się raptem 20% co jest i tak całkiem dobrym wynikiem biorąc pod uwagę to, iż blogi techniczne rzadko, tak naprawdę, są w dzisiejszych czasach blogami.
Liczba recenzji nie zaskakuje – w końcu ile rzeczy można opisać? A teksty angażujące luźną dyskusję, nieprzepełnioną nienawiścią i wyzwiskami wśród czytelników, to wciąż rzadkość w naszym internecie.
Hejt – tej kategorii należy się drobne wytłumaczenie. Przyznawana była ona zawsze wtedy, gdy ilość treści negatywnej wynikającej z nagłówka sugerowała, iż w komentarzach dojdzie do ostrej bitwy – i co smutne, prawie zawsze się to sprawdzało.
1/3 – zapiszę to słownie, jedna trzecia(!) nagłówków zawierała zbędne emocje, które doprowadzały do ostrej wymiany zdań w komentarzach. Oczywiście, nie mając odpowiednich danych, nie można powiązać tych tekstów z dochodami serwisów i redakcji, więc wysnuwanie wniosków o tym, że aktualny Internet zarabia na nienawiści bratniej, było by daleko idącym bezpodstawnym oskarżeniem, z drugiej jednak strony… statystyki nie kłamią*.
ONETykietę prasową pora zawalczyć
Pozostaje więc odpowiedzieć na pytanie, co z czytelnikami robią nagłówki….
… ale, sądzę moi drodzy, że na to pytanie już nie muszę odpowiadać. Bo wiedzieliście o tym w momencie kliknięcia w TEN nagłówek.
Pozdrawiam i życzę wszystkiego dobrego w nowym nadchodzącym roku.
* „Statystyka nie kłamie. Kłamią jedynie statystycy.”


![Tani soundbar z opcjonalnym RGB. Genesis Helium 312BT [Recenzja]](https://v.wpimg.pl/OWM3LmpwYDYsUTpeXwxtI28JbgQZVWN1OBF2T19CdmA1AH1bXwMqNCUdOx0TEyF5PV9jBB0QYGF5A3hcQRMuen5We1xdQ300fB4uWUlAYmAuCygLSUEuZXRQe0MaByh1MA)
![Wysoka precyzja i wydajność w II gen. Logitech Pro X Superlight 2 DEX [Recenzja]](https://v.wpimg.pl/ODUwLmpwYCU0FTpeXwxtMHdNbgQZVWNmIFV2T19CdnMtRH1bXwMqJz1ZOx0TEyFqJRtjBB0QYCJsQXRVQBR-aWVDel9dQy4gMVp1XBEVYnY3RHsLREUucW1CfEMaByhmKA)



