

Optymalizacja w LibreOffice 4.2
Druga beta najnowszego LibreOffice'a jest już daleko za nami, a nieliczne portale - jeśli w ogóle poruszyły ten temat - potraktowały go pobieżnie, spłaszczając jego treść do prostych sloganów typu "ulepszono" i "poprawiono". Aż żal było to czytać, dlatego też prezentuję parę ciekawych informacji o efektach kilku optymalizujących kod zabiegach, jakich dokonano w wersji 4.2.
Szybszy eksport komórek bogatych w treść
To, co dotychczas przyciągało uwagę to powolne tempo podczas zapisu dokumentów w natywnym formacie ODS. Było to szczególnie zauważalne wówczas wtedy, gdy arkusz zawierał wiele komórek bogatych w treść.

Komórki bogate w treść są po prostu komórkami zawierającymi różnorodne formatowanie lub tekst składający się z wielu linii. Komórki te obsługiwane są w inny sposób od prostych, wewnętrznych ciągów i wymagają nieco więcej nakładu pracy niż ich proste odpowiedniki. Z tego też powodu zapisywanie dokumentów bogatych w tekst zawsze trwało dłużej niż zapisywanie dokumentów z tylko liczbami i prostymi ciągami.
Jakkolwiek by się nie tłumaczyć, ogólny kierunek rozwoju poszedł w złą stronę i nareszcie postanowiono zrobić z tym porządek. Zoptymalizowano algorytm oraz wyeliminowano zbędne procesy alokacji i dealokacji pamięci. Dzięki temu Calc 4.2 okazał się być najszybszym arkuszem w historii LibreOffice.
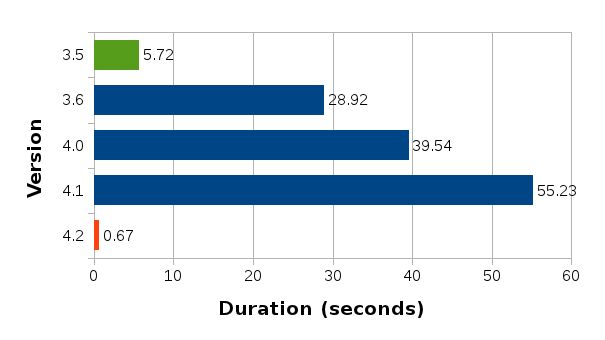
Pomiar wykonano na nowym pliku, gdzie w komórce A1 umieszczono trzy razy słowo "libreoffice" (każe w osobnym wierszu), a następnie zreplikowano komórkę do obszaru A1:N1000 i wykonano pomiar prędkości zapisu.
Redukcja zużycia pamięci podczas używania współdzielonych formuł
Jak twierdzi główny deweloper Calca, arkusz kalkulacyjny doczekał się w końcu "implementacji frameworka współdzielenia formuł z prawdziwego zdarzenia". Nowy Calc współdzieli instancje tablic znaczników pomiędzy sąsiadującymi ze sobą komórkami (formułami) jeśli tylko zawierają one identyczny zestaw znaczników formuł.
Ponieważ główną zaletą współdzielonych formuł jest zredukowanie zajętej pamięci, postanowiono zmierzyć trend jej użycia od wersji 4.0 do aktualnej wtedy kompilacji z głównej gałęzi rozwojowej.
Pomiaru dokonano na dokumencie (5.2 MB), który zawierał w sobie 100 tysięcy wierszy w czterech kolumnach, z czego 399 999 z nich zawierało w sobie formułę.
Kolumna A zawiera serię liczb całkowitych, których wartość wzrasta liniowo wraz z każdym wierszem. Tylko pierwsza komórka (A1) jest liczbą, podczas gdy reszta jest formułami. Każda następna komórka odnosi się do poprzedniej (A5 odwołuje się do A4, A4 odwołuje się do A3 itd). Wszystkie komórki w kolumnie B odwołują się do kolumny A, natomiast wszystkie komórki w kolumnie C odnoszą się do kolumny B i tak dalej. Odwołania użyte w dokumencie mają charakter odwołań względnych; żadne relacje bezwzględne nie zostały użyte.
Pomiaru dokonano na systemie openSUSE 11.4 (x64), gdzie tylko wersja 4.0.1 pochodziła z linuksowego repozytorium. Kolejne kompilacje pochodzą z oficjalnych gałęzi projektu, a sam pakiet został zbudowany na lokalnej maszynie programisty.
W przypadku każdego testu pomiar zużycia pamięci był mierzony przez bezpośrednie otwarcie testowego dokumentu z linii poleceń i odczytanie wirtualnej pamięci przez Monitor Systemu w środowisku GNOME. Po wczytaniu dokumentu odczekano kilka sekund, aby ustabilizować zużycie pamięci. Efekty przedstawia poniższy wykres:
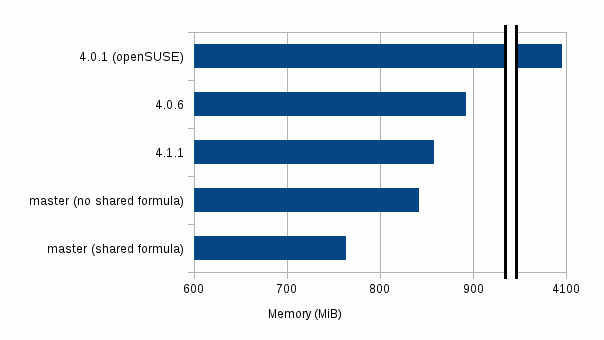
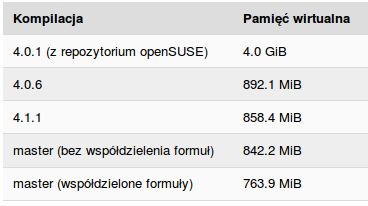
Dodatkowo pomiar liczb instancji tablic znaczników pomiędzy dwiema kompilacjami (jednej z opcją współdzielenia formuł i drugiej bez niej) pokazał, że kompilacja bez współdzielenia formuł utworzyła 399 999 instancji tablic znaczników (dokładnie 4 x 100 000 - 1) w czasie wczytania pliku, podczas gdy kompilacja ze współdzielonymi formułami utworzyła jedynie 4 instancje tablic znaczników.
To prawdopodobnie wyjaśnia różnicę 78.3 MiB wirtualnej pamięci pomiędzy dwiema kompilacjami.
Szybsze wyszukiwanie w pionie
Lionel Dricot, jeden z pracowników firmy Lanedo, opisał przypadek współpracy swojej firmy z holenderską spółką Moonen Packaging. Firma zgłosiła błąd, w którym skarżyła się na powolne działanie funkcji WYSZUKAJ.PIONOWO (VLOOPUP) w przypadku odnoszenia się do zewnętrznych arkuszy z dużą ilością wierszy.
Lenado zidentyfikowało dwie sytuację i 2 przypadki dla każdej z nich. W pierwszej sytuacji (A) otwarto dokument i wykonano polecenie WYSZUKAJ.PIONOWO. W drugiej sytuacji (B) otwarto dokument zawierający dane źródłowe przed wykonaniem formuły. W obu przypadkach wykonano prostą formułę (na komórce A1 i B1) lub całkowicie wypełniono arkusz, aby móc wykonać więcej niż 10 tysięcy operacji WYSZUKAJ.PIONOWO (A2 i B2). Ze względu na szczególne mechanizmy pamięci podręcznej, nie ma gwarancji, że jedna operacja WYSZUKAJ.PIONOWO będzie szybsza niż 10 000 podobnych żądań.
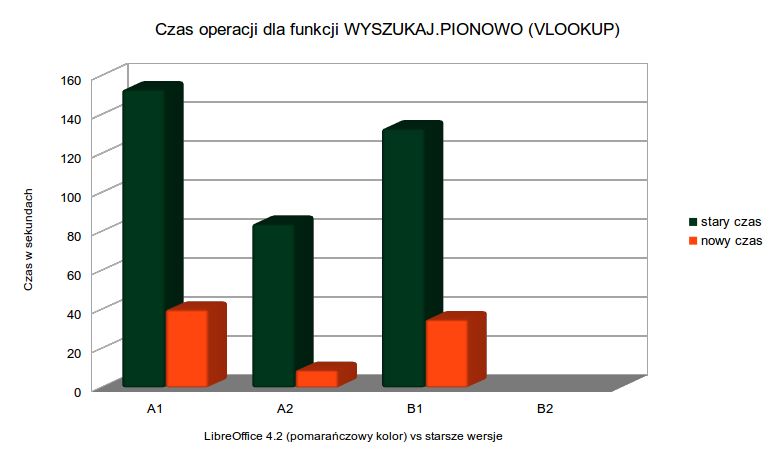
Wyniki były gorsze niż złe. Komórka A1 zajęła 153 sekund, A2 zajęła 87 sekund, B1 zajęło 133 sekund, a B2 zajęło to... cały, jeden tydzień!
Sytuację udało się doprowadzić do (niemalże) akceptowalnego stanu rzeczy. Holendrzy przygotowali bardzo dobrze opracowany raport błędu, który - jak twierdzi pracownik Lanedo - pozwolił zaoszczędzić firmie sporą sumę pieniędzy.
Już po naprawie, czas reakcji w tych samych dokumentach zmniejszył się do sporo niższych wartości. A1 zajmuje 40 sekund, A2 zajmuje tylko 9 sekund, B1 zajmuje 35 sekund, a czas oczekiwania w B2 zredukowano z tygodnia do dwóch dni. Wciąż jest to spory interwał, a według eksperymentów, czas ten można zredukować z 48 godzin do... 10 sekund lub nawet mniej! Niestety badania tego typu wymagają kilka dni ciągłej pracy po stronie Lanedo, co jest niestety poza budżetem projektu.
Gdyby jednak jakiejś firmie zależało na (płatnym) udoskonaleniu działania funkcji WYSZUKAJ.PIONOWO, Lanedo chętnie podejmie się zlecenia.
Nowy, szybki silnik bazy danych
Komponent Base 4.2 jest pierwszym, który zawiera w sobie eksperymentalną obsługę relacyjnej bazy danych Firebird. Dotychczas LibreOffice, jak i OpenOffice bazowały na silniku HSQLDB 1.8, jednakże z planów na przyszłość obu projektów wynikają odrębne cele.
Apache OpenOffice będzie migrował na HSQLDB 2.2.x, podczas gdy deweloperzy LibreOffice będą stopniowo wycofywać się z silnika tego rodzaju. Proces ten ma potrwać przez następnych kilka wydań i zakończyć się czymś, co pozwoli dokonać łatwej migracji ze starego typu silnika na nowy. Połączenie się z nowszą wersją HSQLDB 2.x wciąż będzie możliwe dzięki natywnemu interfejsowi zwanemu JDBC.
Jedną, natychmiastowo zauważalną różnicą jest pozbycie się ogromnej pauzy, która powstawała podczas wczytywania bazy, a którego powodem był start wirtualnej maszyny Javy (JVM).
Chociaż głównego przyśpieszenie czasu reakcji oczekuje się podczas pracy z właściwymi danymi, wykonano test polegający na wstawianiu i odzyskiwaniu 120 tysięcy ciągów (był to zrzut danych ze słownika aspell), którego poniższe rezultaty przedstawiają znaczącą przewagę bazy Firebird nad jego poprzednikiem.
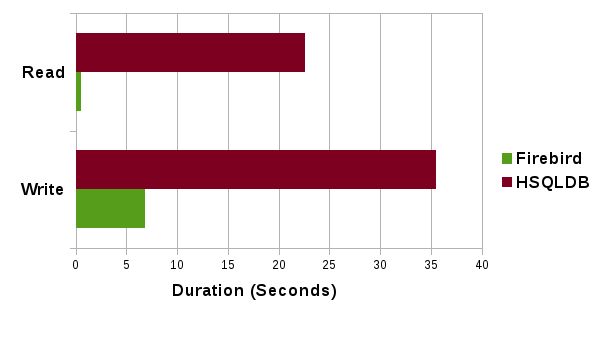
Projekt nie został całkowicie ukończony i niektóre kreatory Base wciąż wymagają Javy, co może wywoływać pauzy w różnych punktach czasu. Przepisanie całości do C++/Pythona jest zaplanowane na następne wydania.
Aby móc pracować z nową bazą danych, trzeba aktywować eksperymentalne funkcje w menu Narzędzia > Opcje > LibreOffice > Zaawansowane. Nowe wydanie jest efektem prac Andrzej Hunta, studenta-weterana, który nowy silnik zaimplementował w ramach programu Google Summer of Code.
Poprawa wydajności obliczeń dzięki OpenCL
Na początku lipca firma AMD przystąpiła do Rady Doradców fundacji z zamiarem przyśpieszenia działania Calca w oparciu o GPU, a już dzisiaj możemy smakować owoców tej współpracy.
Zaproponowane przez AMD rozwiązanie wykorzystuje architekturę HSA (Heterogeneous System Architecture), w której procesor graficzny ma dostęp do tej samej pamięci co aplikacja, i która szczególnie efektywna jest w czipach APU, gdzie zarówno GPU, jak i CPU znajdują się w tym samym układzie. Nie trzeba tu więc wydzielać specjalnych zadań dla procesora graficznego i koordynować jego współpracę z głównym procesorem przez wąskie gardła kontrolerów pamięci. Sprzętowa akceleracja dla arkusza kalkulacyjnego ma polegać na wykryciu możliwych do optymalizacji formuł w komórkach, przekształceniu ich na kod OpenCL, skompilowaniu kodu OpenCL na procesor graficzny, a następnie uruchomieniu formuły na GPU. Ma to być, według Micheala Meeksa, szczególnie efektywne dla dużych arkuszy, zawierających liczne powtórzenia tych samych formuł. Zmiana ta ma szansę na szybką popularyzację, zwłaszcza od wydania LibreOffice 4.2, który to umożliwia tworzenie dokumentów o rozmiarze nawet do czterech gigabajtów.
Na pytanie czy systemy z GPU Intela i Nvidii również będą beneficjentami zmiany, Meeks odpowiedział: "jeśli dostawca posiada dobrą implementację OpenCL, będziemy ją wykorzystywać i to powinno być ok".
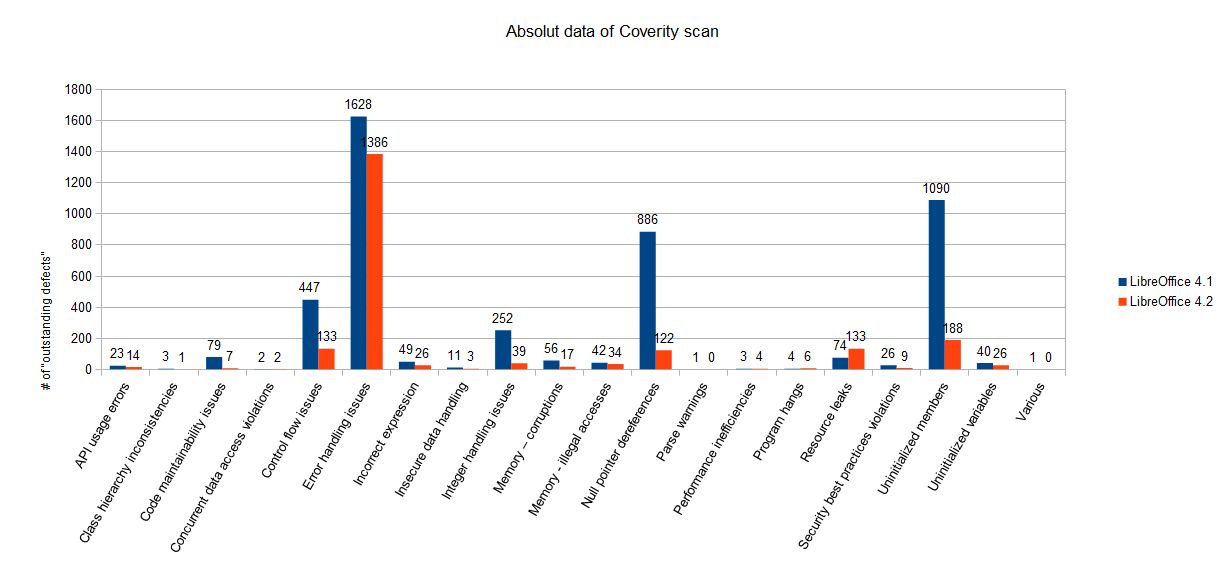
Ogólna poprawa jakości kodu dzięki analizie Coverity
Coverity jest dostawcą narzędzi do testowania jakości oprogramowania w tym narzędzi do odnajdowania luk bezpieczeństwa w kodzie źródłowym, defektów i błędów poprzez analizę statyczną. Od 2006 roku współpracuje z Departamentem Bezpieczeństwa Krajowego Stanów Zjednoczonych, skanując kod źródłowy różnorakiego oprogramowania Open Source.
Coverity swego czasu współpracowało z projektem OpenOffice.org, a w listopadzie opublikowało raport z analizy kodu LibreOffice 4.1 (dostępny po rejestracji).
Efektem skanu było wyłapanie różnorakich błędów w tym m.in. błędnego użycia API, niespójności hierarchii klas, niewłaściwych wyrażeń czy wycieków pamięci (pełna lista na stronie czwartej raportu). Skutkiem współpracy firmy Coverity z The Document Foundation jest rozwiązanie prawdopodobnie rekordowej liczby błędów w jednej becie (1131 poprawek!). Również analiza kodu LibreOffice 4.2 potwierdziła spadek liczby błędów i poprawę jakości kodu.
I to by było na tyle w dzisiejszym odcinku. Dziękuję za uwagę i do zobaczenia. ;‑)



![Smukła klawiatura bezprzewodowa. Logitech Keys-To-Go 2 [Recenzja]](https://v.wpimg.pl/YWU5LmpwdjY0VzpeXwx7I3cPbgQZVXV1IBd2T19CYGAtBn1bXwM8ND0bOx0TEzd5JVljBB0QdmQzBy9YQRNgemYMKQldQ24xYBguWhNBdG9hAS8JRhZhMTRQdUMaBz51KA)
![Mroczna Metroidvania dla masochistów. Voidwrought [Pierwszy rzut okiem]](https://v.wpimg.pl/NzU1LmpwYRs0UzpeXwxsDncLbgQZVWJYIBN2T19Cd00tAn1bXwMrGT0fOx0TEyBUJV1jBB0QYUtiA3VeEhJ-VzdXfghdQygbNxwuCxIWY0M0CS1fQxZ6S2IEeUMaBylYKA)
![Wciąga jak anomalia i pozostawia blizny. S.T.A.L.K.E.R. 2 [Recenzja]](https://v.wpimg.pl/YWQ1LnBudjYwUzpdbQ57I3MLbgcrV3V1JBN2TG1AYGApAn1YbQE8NDkfOx4hETd5IV1jBy8SdmBlUntYckE9ejQHfAtvQWFhYxx1XnAUdGVlBS5ddxNuNDBVeUAyGz51LA)

![Wysoka wydajność w kompaktowej obudowie. HATOR Rockfall 3 TKL [Recenzja]](https://v.wpimg.pl/YzIzLmpwdhsoGDpeXwx7DmtAbgQZVXVYPFh2T19CYE0xSX1bXwM8GSFUOx0TEzdUORZjBB0Qdk95Si4OSU9oVygbLltdQ28ccFctDkcVdBh9Q3xVR0VqQipIf0MaBz5YNA)