

RAIDers of the lost drive cz.2
Wstęp
Nie tak dawno wspomniałem o podstawach konfiguracji RAID w serwerach HP. Jak już wtedy podałem, RAID nie jest backupem i nawet przy zachowaniu redundacji dysków fizycznych, jest możliwa utrata danych: szczególnie, jak nie wiemy o "problemie" z jednym napędów. W dzisiejszym wpisie poruszę kwestię prostego monitoringu zasobów sprzętowych za pomocą "trapów SNMP" wysyłanych mailem i rozsądny sposób zgłaszania awarii na przykładnie sprzętu HP.Prosty monitoring
W małym jak i w rozbudowanym środowisku serwerowo-desktopowym dosć istotnym aspektem jest monitoring uwzględniający zasoby sprzętowe. W większości sytuacji kończy się to na czasochłonnym dopieszczaniem oprogramowania, MIBów i obsługi "trapów" SNMP : w dużym uproszczoszczeniu urządzenie z chwilą awarii 'wypluwa' na duży ekan NOC najważniejsze informacje o zdarzeniu:
![[NOC: źródło Wikipedia]](https://v.wpimg.pl/NF8wLmpwYSdZFTpeXwxsMhpNbgQZVWJkTVV2T18UYXcKT3wVXx4jIRYTIw8CEj40VxA-DB0OYDZUWAUAERArNRciCy5fRnhwAEVjX0BGfXYNRXtcRkR2dAwofEMaBylkRQ)
[jak ktoś jest zainteresowany, mogę kiedyś poświęcić kilka wpisów o budowaniu takiego środowiska: od konfiguracji Nagiosa / Tivoli Monitoring po implementację obsługi zgodnych z ITIL ]
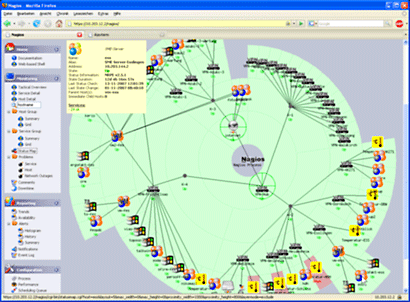
Co jednak zrobić, jak nie mamy odpowiedniej infrastruktury, czasu, czy kompetencji do wprowadzenia monitoringu z prawdziwego zdarzenia a serwery są np. 200km od naszego biura i nie ma możliwości obserwowania kolorów diód na przednim panelu serwera? Można wysłać 'alert' mailem.
Konfiguracja
Serwer na którym demonstruję konfigurację to HP Proliant DL380 z serii G7:

Zainstalowany system operacyjny to Windows 2008R2, maszyna pełni rolę PDC, czyli dość istotne zadania w środowisku Active Directory. Zakładam, że administrator zainstalował wszystkie zalecane programy z 'HP Managment Apps': przejdźmy więc do "HP Management Agents -‑> Event Notifier Config":
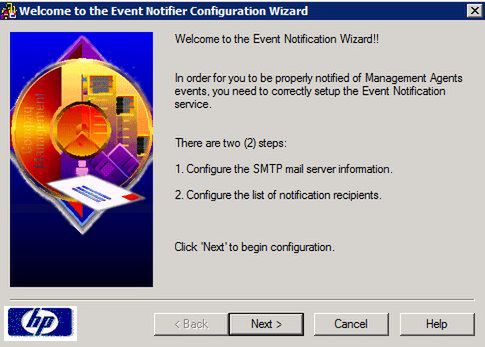
Tam przywita nas dość prosty w obsłudze "łizard'. Już na wstępie widać, że trzeba sobie przygotować adres serwera SMTP, który "przepuści" nasze maile: rolę może spełnić "localhost" (gdy monitorowany box pełni rolę serwera pocztowego), ew. można dodać IP do 'whitelist' na serwerze SMTP, lub poszukać innego rozwiązania z przepchnięciem maila przez otwarty serwer SMTP:
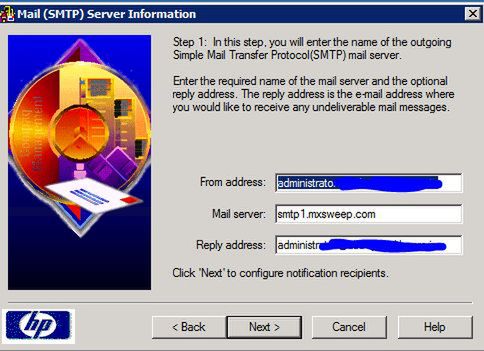
Warto na zaglądnąć w opcję "Events": domyślnie będą przekazywane na maila wszelkie możliwe zdarzenia generowane przez SNMP poczynając na podłączeniu/odłączeniu urządzenia do gniazda USB a kończąc na przerwach w zasilaniu na jednym z zasilaczy, czy uszkodzeniu dysku:
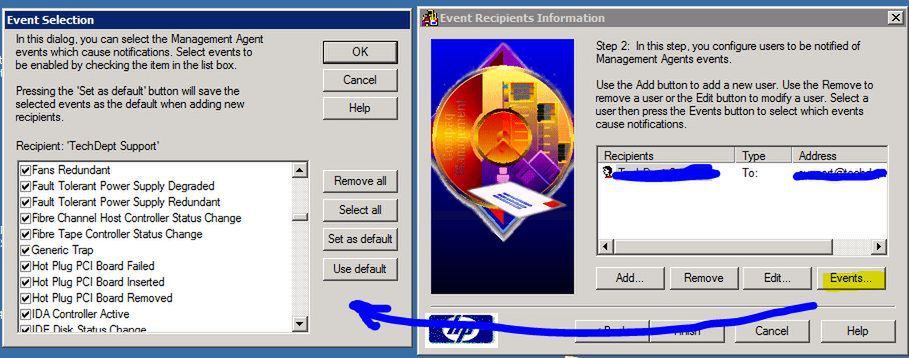
Nadal jednak nie mamy pewności, czy nasza konfiguracja spełni swoje zadanie. Najprościej by było teraz popsuć jeden z dysków twardych, lub odłączyć jeden z kabli zasilających, ale nie tędy droga w środowisku produkcyjnym: wygenerujmy więc testowe zdarzenie za pomocą "HP System Management Homespace".
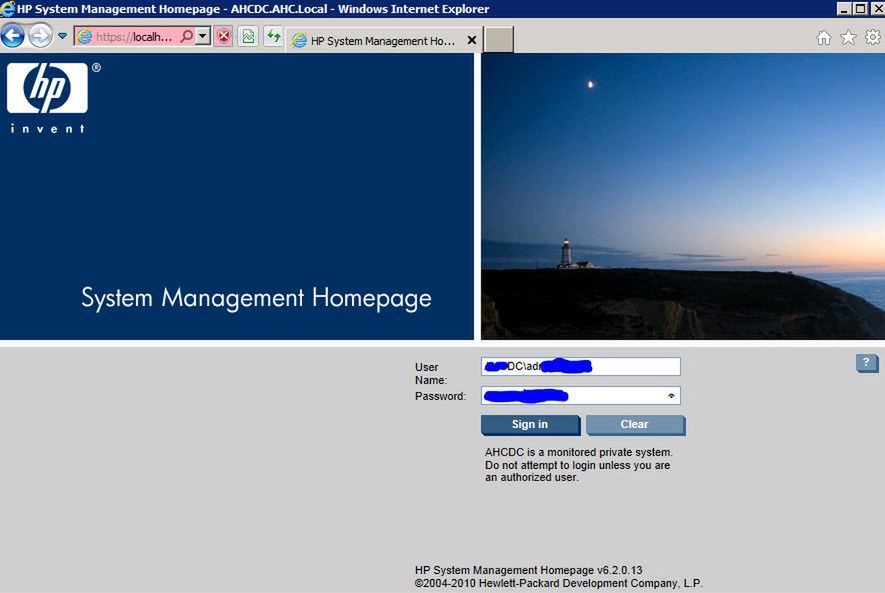
W środowisku domenowym logujemy się za uprawnień konta administratora: NAZWADOMENY\administrator
W panelu zarządzania należy przejść do zakładki "Settings" i w opcjach "SNMP Webagent" kliknąć w "SNMP & Agent Settings":
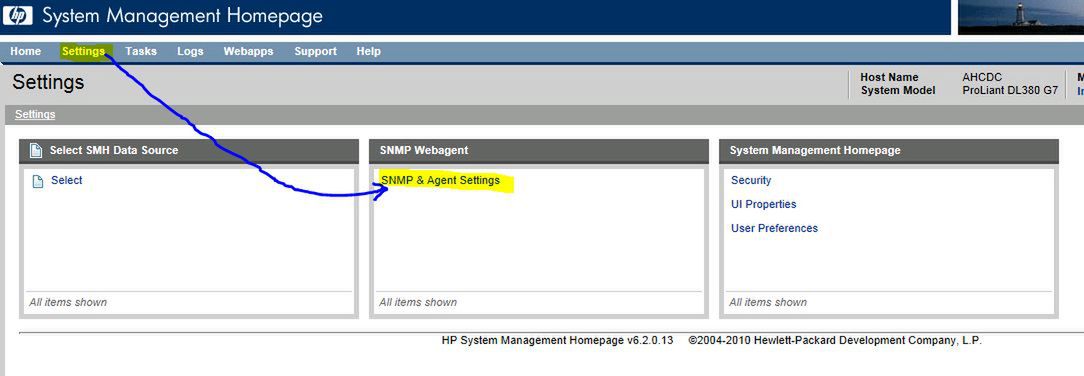
Po wyświetleniu kolejnego okna możemy już wygenerować testowy "TRAP":
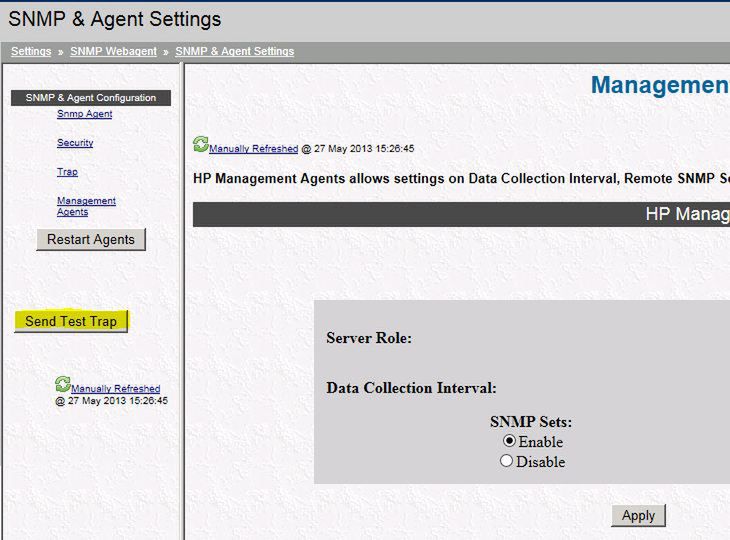
W sytuacji, gdy skonfigurowaliśmy wszystko poprawnie, powinniśmy po chwili otrzymać maila o przykładowej treści:
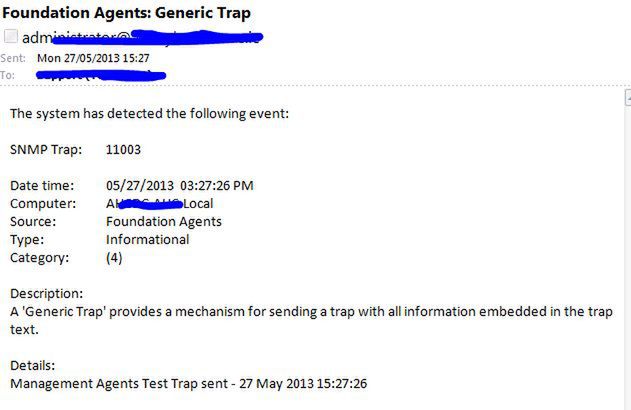
W tym miejscu należy pamiętać, że w przypadku niektórych awarii mail może do nas nie dotrzeć: uszkodzenie płyty głównej, karty sieciowej, głównego switcha, czy najzwyklejsza przerwa w dostawie prądu przy złej konfiguracji UPS.
Awaria
![[źródło: .kayugaharu2u.com]](https://v.wpimg.pl/N18wLmpwYVBZFTpeXwxsRRpNbgQZVWITTVV2T18UYQAKT3wVXx4jVhYTIw8CEj5DVxA-DB0OYEFUWAUAERArQhciCy5fRngHAEVjX0BGfQENRXtcR0R-AQ8ofEMaBykTRQ)
Jak już wspomniałem, serwery też się psują a w szczególności dyski twarde. Zakładamy, że wiemy już o awarii z np. otrzymanego maila, lub któryś z pracowników zauważył pomarańczową diodę na panelu (standardowo są zielone...):
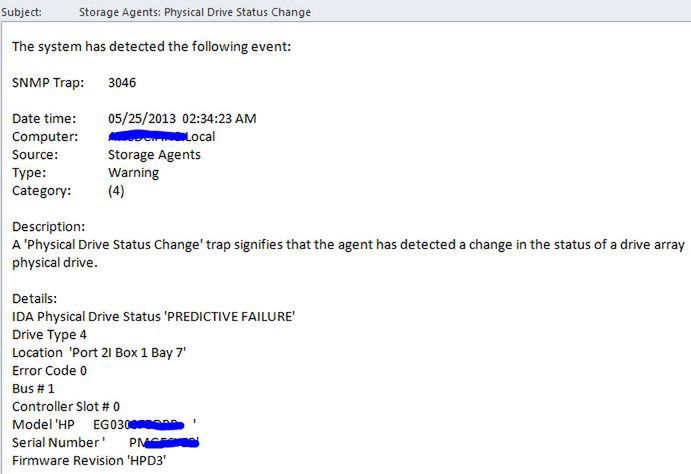
Oznacza to, że należy wymienić dysk w serwerze. Najlepsze rozwiązanie to sytuacja, gdy wszystkie nasze maszyny są na gwarancji: kupując "zabawki" należy dodać minimum 4 lata wsparcia HP i co roku przedłużać o 12 miesięcy. Jest to moim zdaniem niezbędne w środowisku produkcyjnym z kilu powodów:

- nie musimy się martwić o ogromne koszta nowych części (jedna sztuka HP 300GB 6G SAS 15K kosztuje ok. €430 a 600GB 6G SAS 10K w granicach €1000!),
- podstawowa gwarancja HP to NBD (Następny Dzień Roboczy): czyli zgłaszając problem przed 17.00 na następny dzień będą dostarczone części zamienne i jeżeli to konieczne wykwalifikowany inżynier); możemy sobie zażyczyć SBD, albo nawet 2h na naprawę serwera, ale księgowy nas wyśmieje, gdy zobaczy koszta takiego wsparcia,
- przy niektórych awariach nie mamy pewności, co się uszkodziło: po wymiane zasilacza, płyty głównej i procesora nagle się okaże, że jest uszkodzona elektronika włącznika obudowy (miałem taki przypadek): kosztami części jest obciążony producent,
- nie musimy się znać na wszystkim: Tobie może zająć nawet kilka godzin wymiana płyty głównej, osobie robiącej to dzień w dzień (HP) pół godziny.
Przed zgłoszeniem serwisowym warto się przygotować. Najważniejszy jest oczywiście numer seryjny urządzenia umieszczony na obudowie serwera. W przypadku braku fizycznego dostępu do sprzętu w Windowsie można posłużyć się "Windows Management Instrumentation ":
wmic csproduct get vendor,name,identifyingnumber
Polecenie powinno wygenerować informację o SN i modelu sprzętu:

W systemach z rodziny *nix można spróbować wyciągnąć za pomocą polecenia:
[code=Java]dmidecode -t system | grep Serial[/code]
Teraz mamy dwie opcje:
- zadzwonić do supportu i zgłosić usterkę,
- "wrzucić case" przez portal HP.
Pierwszej drogi szczerze nie trawię z kilku powodów:
- szczerze nie lubię czekać 15 minut na "wolny slot" a wcześniej gadać z automatami (nie tak dawno HP wprowadziło "pierwszą linię" supportu jako automat z rozpoznawaniem mowy,
- podczas tłumaczenia problemu należy podać bardzo dużo informacji, łącznie z numerem seryjnym dysku, adresami, mailami, telefonami itd.,
- trzeba przejść przez cały proces jak próba "naprawienia" problemu (np. odłączenie/ponowne podłączenie dysku),
- w przypadku korzystania wsparcia anglojęzycznego najczęściej odbierze osoba, mówiąc delikatnie nie będąca "native speaker", co może doprowadzić do białej gorączki zarówno Ciebie jak i support,
Zróbmy to przez portal HP, jednak przygotujmy sobie najpierw odpowiednie informacje. Na serwerze należy uruchomić "HP Array Configuration Utilty" - w każdej chwili można pobrać ze strony HP, instalacja nie wymaga restartu serwera. Dokładnie te same informacje można uzyskać za pomocą 'LiveCD' opisywanego w pierwszej części wpisu.
Jak można stwierdzić, SNMP trap nie mylił się, jeden z dysków jest uszkodzony: tragedii jeszcze nie ma, ale do nieszczęścia coraz bliżej:
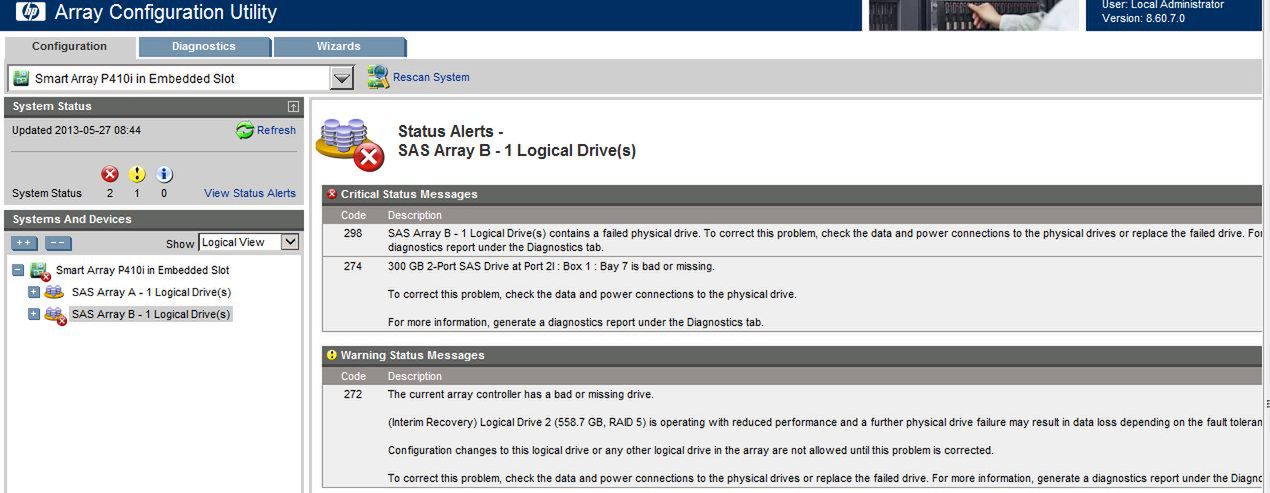
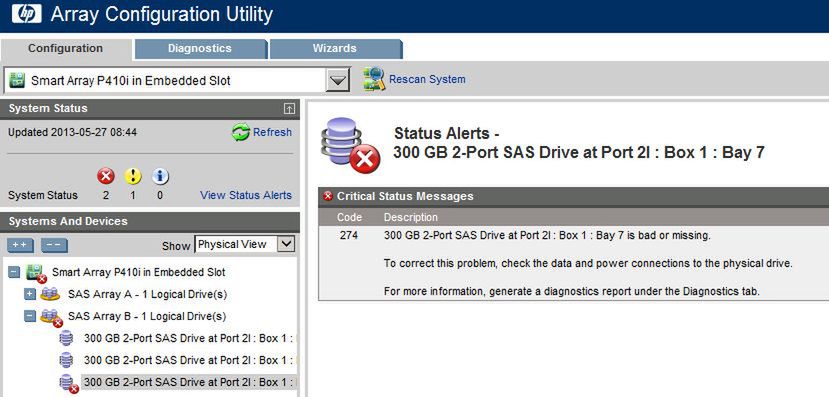
Na którymś etapie zgłoszenia serwisowego HP na 100% zapyta nas o "raport ACU" - przejdźmy więc do zakładki "Diagnostics" i wygenerujmy paczkę .zip za pomocą "Generate Diagnostic Report":
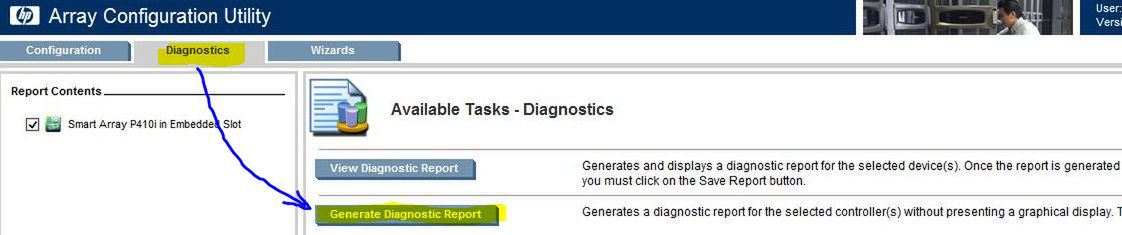
W paczce znajdują się informacje (XML), zawierające szczegółowe informacje o konfiguracji, numerach seryjnych, firmware itd. Plik ten należy pobrać, będzie potrzebny później.
Teraz należy założyć konto na stronie HP. Po zalogowaniu się (należy się uzbroić w cierpliwość, strona HP ślimaczy się, jak backup nad ranem) interesuje nas zakładka: "Submit of manage support cases", znajdująca się w dolnej części lewego menu:
W pole "Contract or warranty ID" należy wpisać uzyskany wcześniej SN serwera:
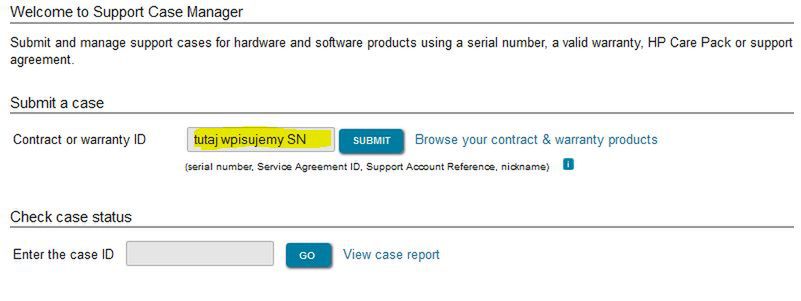
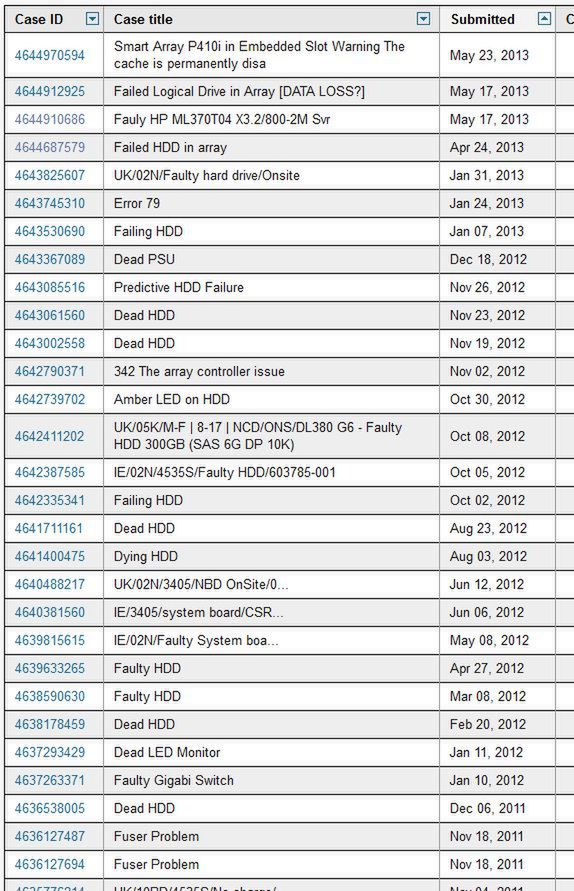
W przypadku, gdy nasze konto nie jest dziewicze, zostaną też wyświetlone inne zgłoszenia:
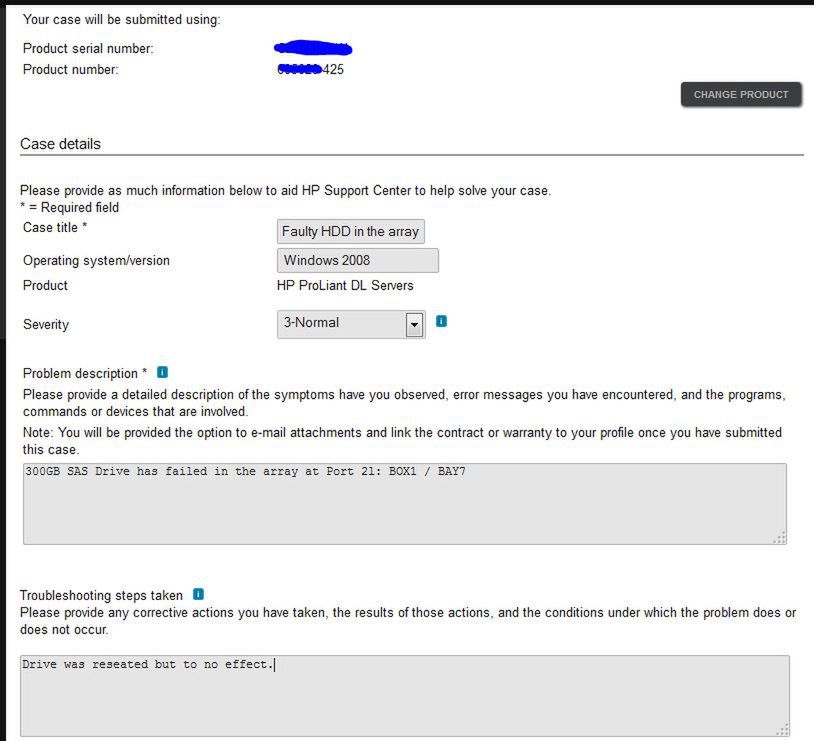
Starajmy się opsiać problem bardzo dokładnie: w przypadku uszkodzonego dysku twardego są to dwa zdania:
Czasem warto się chociaż trochę rozpisać:
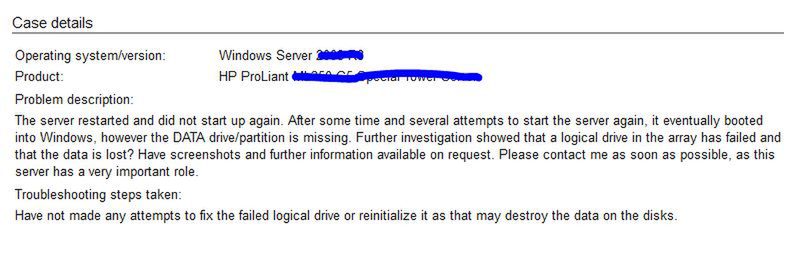
Należy dwa razy sprawdzić wypełnione pola:
- opis usterki,
- adres docelowy zarówno dla części zamiennych (są dostarczane spedytorem krótko przed przyjazdem inżyniera), jak i adres, gdzie znajduje się sam serwer,
- numer telefonu (w krótkim czasie support HP do nas oddzwoni),
- nasz adres mailowy.
Nie należy jeszcze zamykać potwierdzenia:
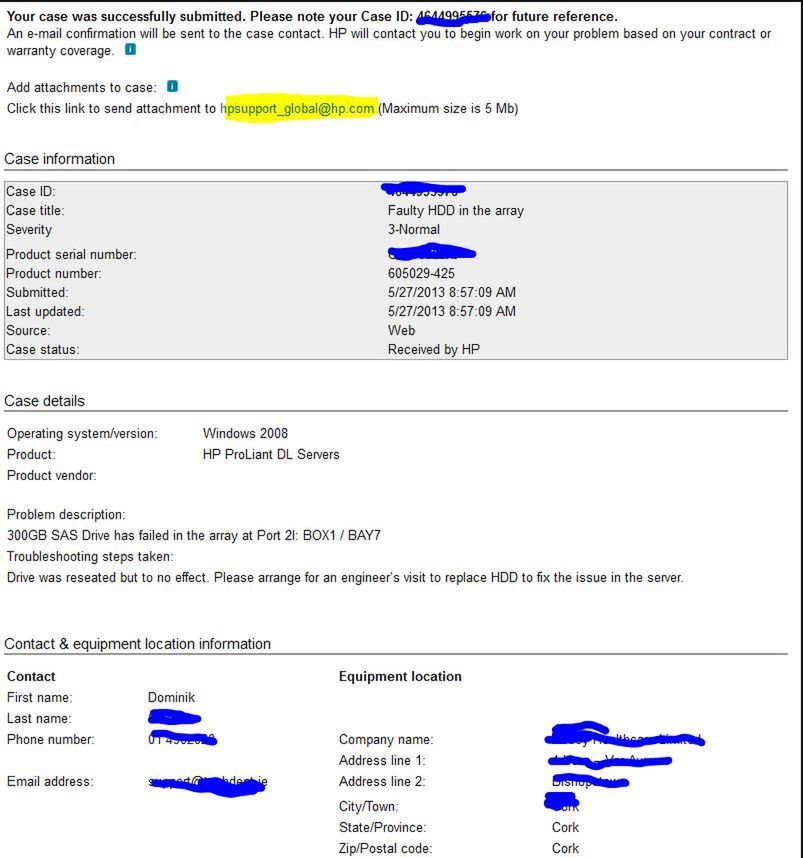
Teraz w miarę szybko należy kliknąć na "Click link to send attachment" i załączyć wygenerowany wcześniej ACU: dzięki temu zanim oddelegowany pracownik pomocy technicznej do nas oddzwoni zapozna się z tym dokumentem (jeżeli tego nie wyślemy i tak się zapyta o te dane):
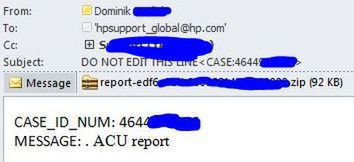
Po chwili powinniśmy otrzymać zwrotkę, że mail przeszedł i trafił do odpowiednego 'case':.
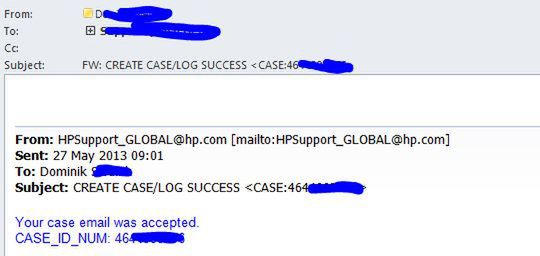
Teraz już możemy oczekiwać telefonu od serwisu: przy wrzuceniu zadania rano (~9AM GMT) telefon odezwie się po kilku minutach. Zostaną zadane nam podstawowe pytania i należy powtórzyć to, co zostało podane w zgłoszeniu, oraz czego oczekuje się od serwisu: potwierdzić dane do wysyłki części zamiennych, oraz czy jest niezbędna wizyta inżyniera (w większości sytuacji nawet mało rozgarnięty "informatyk" wymieni dysk SAS w serwerze, czy uszkodzony zasilacz).
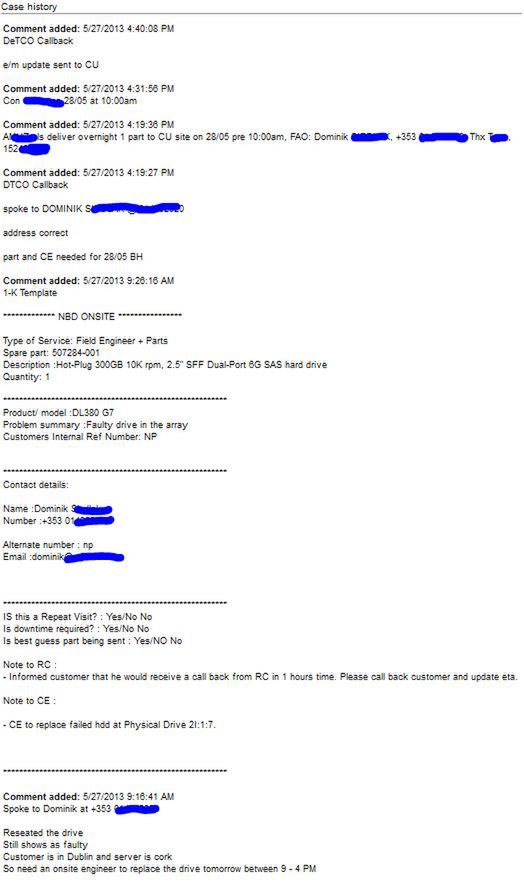
Plusem serwisu "NBD z wizytą inżyniera" jest dodatkowo fakt... redukcji własnych kosztów: w przypadku tego samego miasta nie mam sumienia targać serwisantów do 2‑minutowej roboty. Są oni jednak rozsiani po całym kraju. Dla mnie by to był dzień z głowy i spore koszta(ponad 5h w samochodzie, bak paliwa i kilka razy opłaty autostradowe).
Podsumowanie
Jedno z przysłów informatycznych głosi, że "z próżnego i recover nie odzyska" RAID z dyskami nadmiarowymi nadal nie zapewnia 100% bezpieczeństwa i należy dbać o kopie bezpieczeństwa.
![[źródło: http://lolgod.blogspot.ie/2010/06/jesus-saves-and-makes-incremental.html]](https://v.wpimg.pl/M18wLmpwYlBZFTpeXwxvRRpNbgQZVWETTVV2T18UYgAKT3wVXx4gVhYTIw8CEj1DVxA-DB0OY0FUWAUAERAoQhciCy5fRnsHAEVjX0BGfgENRXRcQkd8AAsofEMaByoTRQ)

![𝕊𝕝𝕖𝕕𝕦𝕛𝕥𝕖]] Avatar 2: The Way of Water (2022) — celý film Online CZ DABIN](https://v.wpimg.pl/YTU3LmpwdjU0UTpeXwx7IHcJbgQZVXV2IBF2T19CYGMtAH1bXwM8Nz0dOx0TEzd6JV9jBB0Qdm02BXtZRRFoeWZWel9dQz9jbB4tD0hCdDdlUHgIQxJsZjQGe0MaBz52KA)
