

Jak Blue Systems zmienia oblicze KDE: Nepomuk
W dzisiejszym hałaśliwym i pełnym sensacyjnych newsów świecie, mało kto zwraca uwagę na firmy/projekty, które nie budują wokół siebie atmosfery "marketingowego jazgotu". Trudno się wszakże dziwić, albowiem współczesny rynek rządzi się swoimi twardymi prawami. Jeśli cię nie widać, ani nie słychać to nie istniejesz. [img=blue] Blue Systems pokazuje jednak, że nie trzeba tworzyć nowych środowisk graficznych, serwera wyświetlania czy balansować na krawędzi absurdu, aby wnieść swój wkład w rozwój open source. Mam nadzieję, iż ten wpis zapoczątkuje nową serię, w której postaram się pokazać jak Blue Systems zmienia oblicze KDE.
Idea semantycznego pulpitu

Nepomuk jest próbą realizacji idei semantycznego pulpitu, chociaż wiele osób nadal postrzega go tylko jako proste narzędzie do indeksowania plików. Nepomuk pozwala nie tylko na wyszukiwanie potrzebnych nam informacji, ale także próbuje ustalić jakie związki pomiędzy nimi zachodzą. Koncepcja bardzo ambitna, niestety jej realizacja we wcześniejszych wersjach KDE pozostawiała wiele do życzenia. To właśnie był jeden z powodów dlaczego Nepomuk był domyślnie wyłączony w niektórych dystrybucjach z KDE.
Lawina zmian z Blue Systems
Programistą pracującym nad Nepomukiem z ramienia Blue Systems jest Vishesh Handa. Przez półtora roku dokonał prawdziwej rewolucji, decydując się na kilka radykalnych, ale jakże potrzebnych zmian.
Nowy moduł indeksowania
Nowy moduł indeksowania jest jednym z najważniejszych usprawnień, który w zauważalny sposób udoskonalił pracę Nepomuka i odczucia użytkownika z nim związane. Nie wiem jak co poniektórych, ale mnie strasznie denerwowała ikona indeksowania, która tkwiła w zasobniku systemowym i miała tendencję do nagłego pojawiania się i znikania w najmniej spodziewanych momentach. Takich atrakcji już nie uświadczymy, bowiem wraz nowym modułem zmienił się również sposób indeksowania plików, który został podzielony na 2 etapy:

- pierwszy (bardzo szybki) w którym indeksowane są tylko nazwa, rodzaj pliku oraz jego położenie
- drugi w którym indeksowana jest zawartość pliku oraz wszelkie metadane z nim związane (uruchamiana jest podczas bezczynności procesora)
Filtracja plików po typie identyfikatora
Dzięki wprowadzeniu nowego modułu indeksowania stała się możliwa filtracja plików po typie identyfikatora. Domyślnie zostały one podzielone na 5 grup (dokumenty, dźwięk, obrazy, filmy, kod źródłowy)
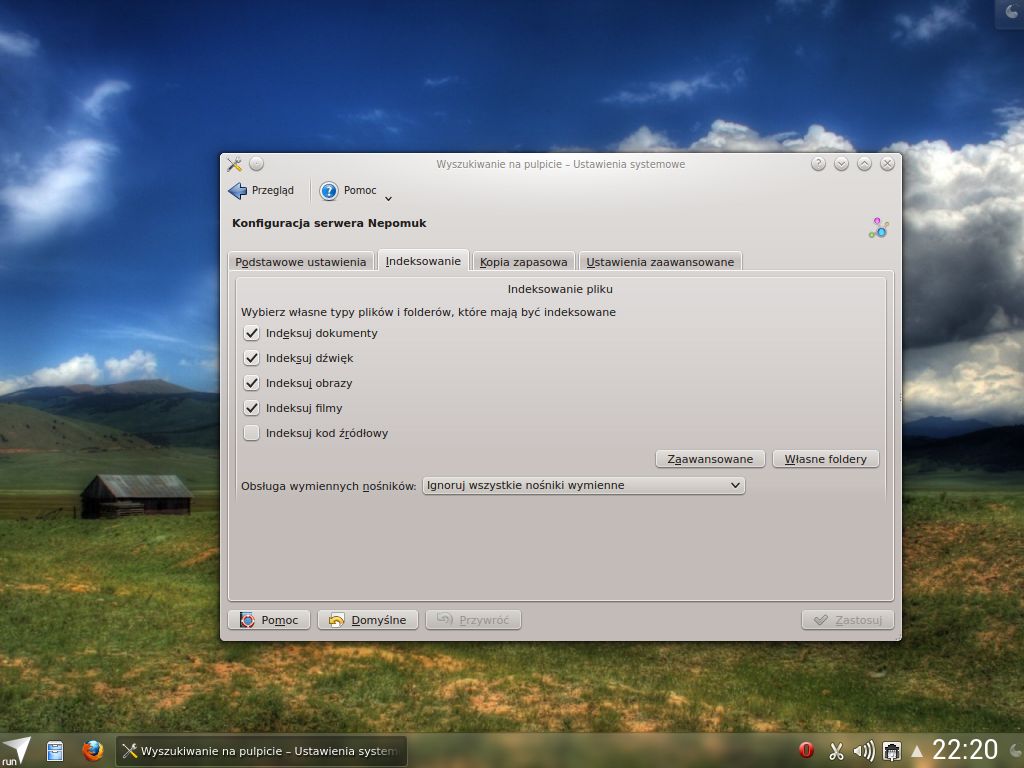
Dostępna jest również zaawansowana konfiguracja pozwalająca wybrać pojedynczy typ danego pliku, który ma zostać wyłączony z indeksowania.
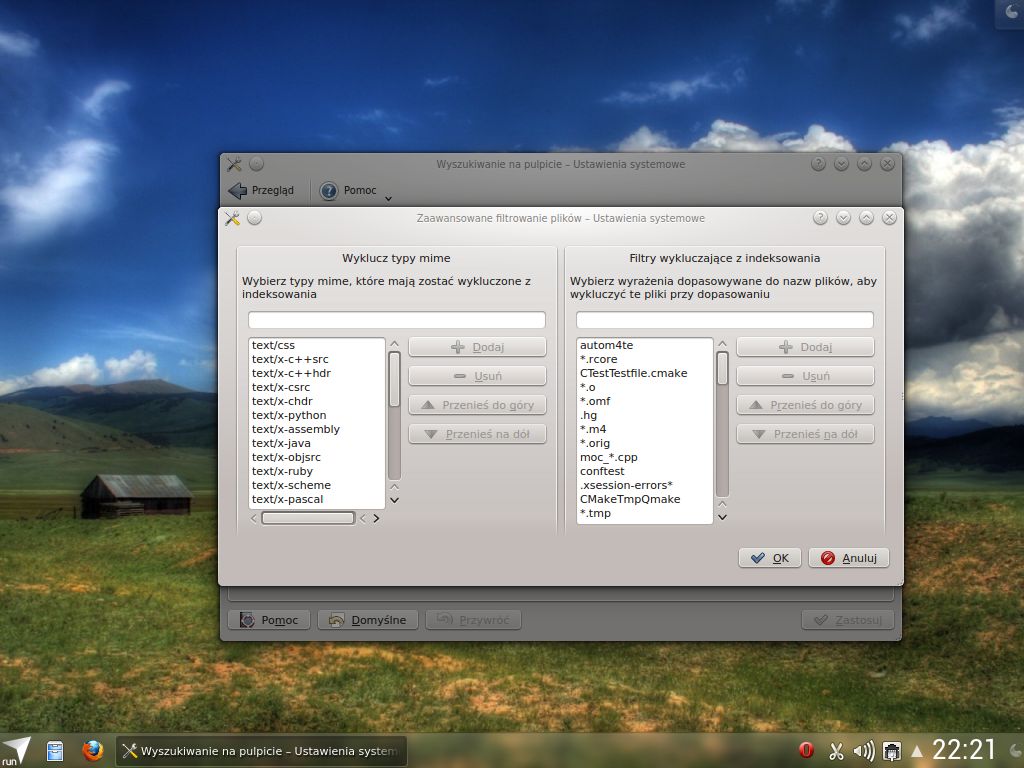
Liczne zmiany w Nepomuk KIO Slaves
Chyba najczęściej używana przez mnie funkcja Nepomuka czyli możliwość wyświetlania poszczególnych rodzajów plików, tagów itp w dolphinie. Polega to na tym, ze jeśli mamy włączone indeksowanie, po uruchomieniu dolphina pokazują nam się dodatkowe miejsca w panelu bocznym dolphina (ostatnio przeglądane i szukaj). Załóżmy, że mamy dużo fajnych tapet porozrzucanych w różnych folderach po całym katalogu domowym. Klikamy na obrazy i pokazują nam się wszystkie tapety w jednym miejscu.
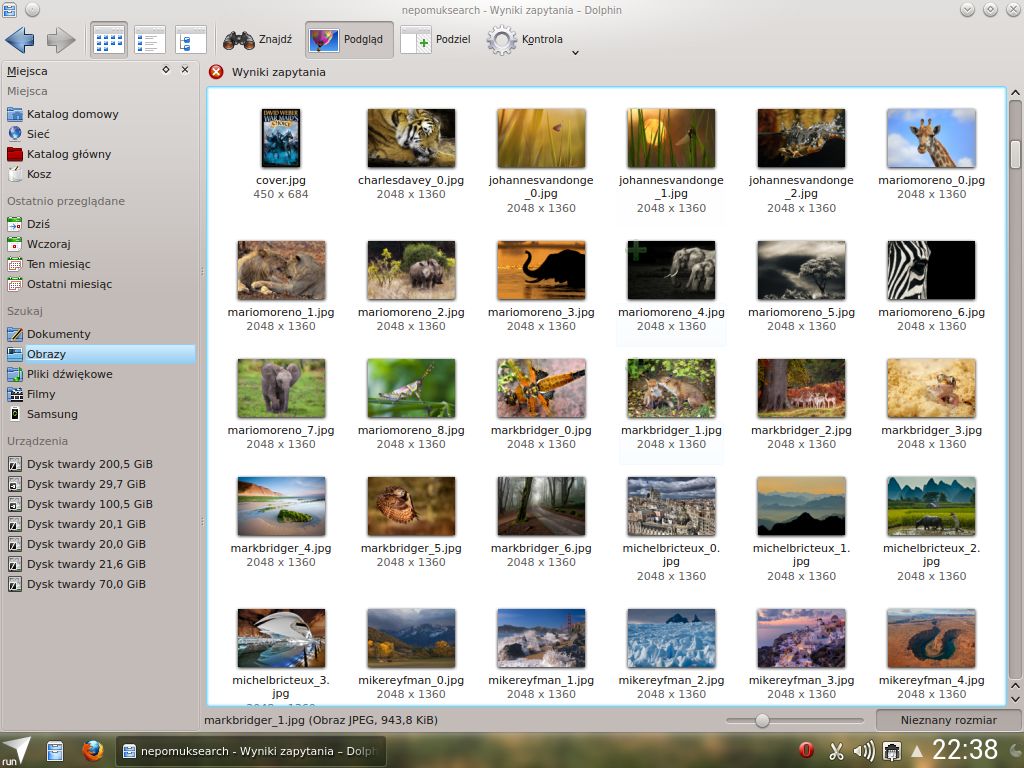
Podobnie jest z muzyką, filmami i dokumentami. Co jednak najlepsze możemy dodawać własne "miejsca" i filtrować np. po tagu. Swego czasu miałem do testów pewną kamerę od samsunga i wszystkie zdjęcia/filmy, które nią zrobiłem otagowałem znacznikiem Samsung. Następnie wystarczyło tylko dodać nowe "miejsce" w panelu bocznym jako położenie wpisując nepomuksearch:/hasTag:Samsung i Voila.
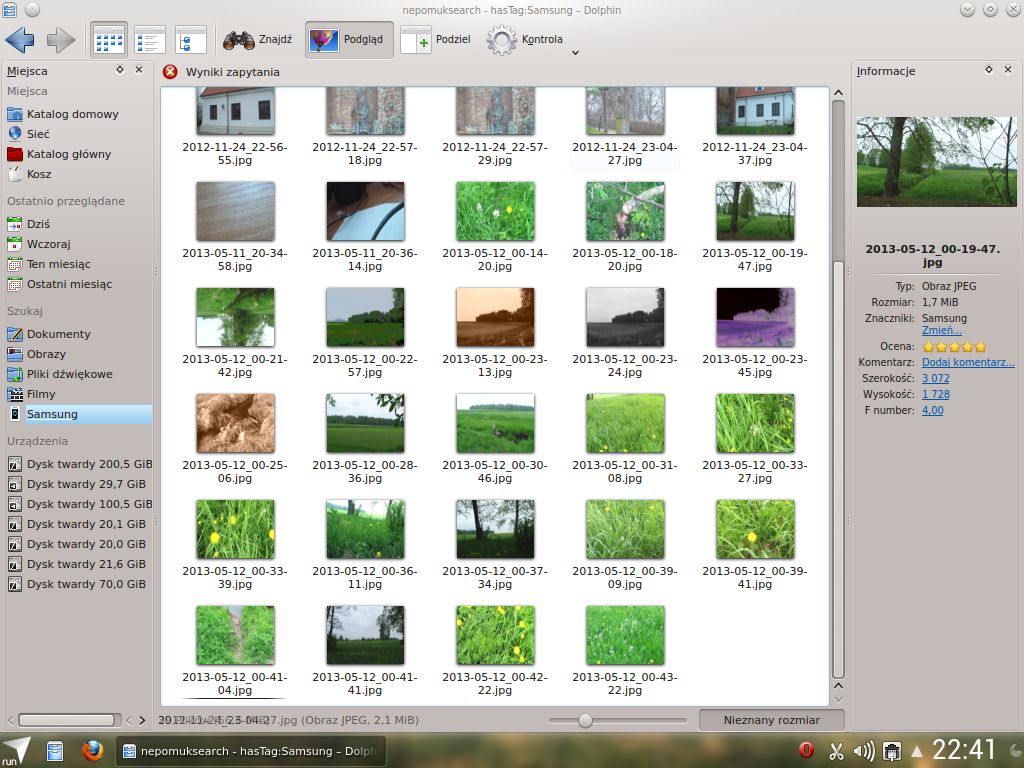
To co uległo zmianie dzięki pracy Visheha, to dramatyczne przyspieszenie wczytywania plików w dolphinie, które pokazują się teraz w ułamku sekundy. A wszystko dzięki optymalizacjom w Nepomuk KIO Slaves. Przed KDE 4.10 ta funkcja była praktycznie nieużywalna, obecnie korzystam z niej niemal bez przerwy.
Kopia zapasowa
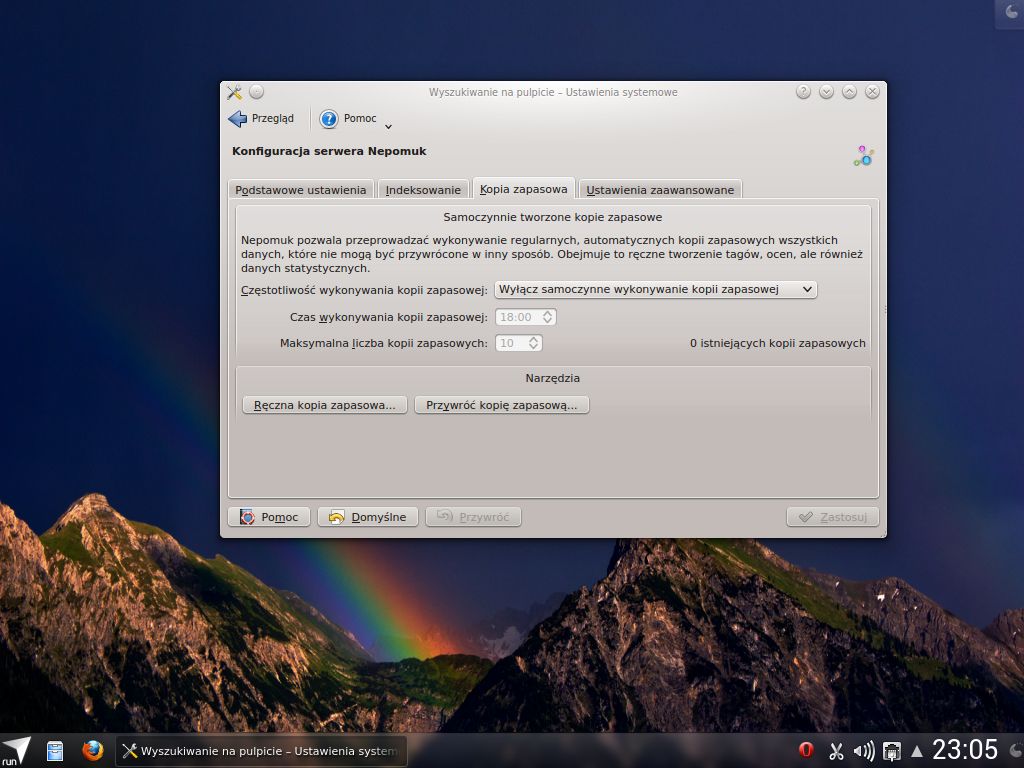
Sporych zmian doczekał się również moduł kopi zapasowej Nepomuka, a wszystko dzięki uproszczeniu kodu oraz dodaniu zestawu testów, które mają sprawdzać poprawność przywróconych danych. Niestety nie korzystam z tego modułu dlatego nie pozostaje mi nic innego jak wierzyć deweloperom na słowo.
Więcej informacji:
http://vhanda.in/blog/2013/01/what-new-with-nepomuk-4-10/
Optymalizacje w odczytywaniu danych z bazy Nepomuka
Jedną z największych zmian w KDE 4.11 jest dramatyczne zwiększenie prędkości odczytywania danych z bazy Nepomuka. Jest to szczególnie istotne dla programów, które używają modułu semantycznego pulpitu w KDE. Osoby pragnące poznać szczegóły techniczne owych usprawnień mogą zasięgnąć stosownych informacji na blogu autora. Ja ze swej strony ograniczę się do efektów końcowych.
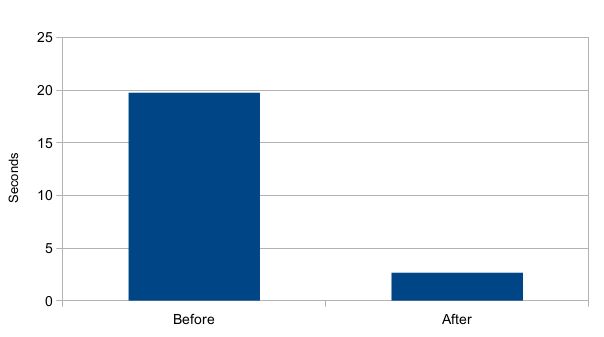
To co widać powyżej to wykres porównujący czas odczytu 50000 rezultatów z bazy danych Nepomuka. Mamy tu 6‑7x wzrost w wydajności. A to przecież tylko część z wielu usprawnień, jakie możliwe były dzięki wsparciu Blue Systems.
To be continued: KWin
![Pojemnościowy mikrofon z technologią LIGHTSYNC. Logitech Yeti Orb [Recenzja]](https://v.wpimg.pl/NTY2LmpwYTU4UDpeXwxsIHsIbgQZVWJ2LBB2T19Cd2MhAX1bXwMrNzEcOx0TEyB6KV5jBB0QYWFoAX8LRUJ7eWAKdQxdQ381ax90W0QVY2BvBHQIRxJ-MmwEekMaByl2JA)


![Dynamiczny mikrofon z technologią LIGHTSYNC. Logitech Yeti GX [Recenzja]](https://v.wpimg.pl/ZjAxLmpwdQsgGjpeXwx4HmNCbgQZVXZINFp2T19CY105S31bXwM_CSlWOx0TEzREMRRjBB0QdV1wSCoPE0A_R3RALltdQz8MIFUtDBESdw8iGS9fE0JoXSdIfUMaBz1IPA)



