
Jak napisać kompaktowego CMS - runda druga, czyli Sobieski z Plusem Milestone 1
Plusy ostatnio robią zawrotną karierę - mamy kolejne odsłony procesu technologicznego Intela, ale również program 500+, Opieka 75+ czy Mieszkanie+.
Jakiś czas miałem potrzebę usunięcia pewnej instalacji Drupal ze swojego życia - wyszło, jak wyszło (czyli całkiem nieźle, aczkolwiek nie bardzo dobrze, gdyż moje plany zostały zrealizowane tylko częściowo).

Jako że teraz znalazłem trochę wolnego czasu, odkurzyłem stare plany i zacząłem się zastanawiać, jak możnaby napisać prosto plikowego CMS, który pozwalałby na robienie całości z WWW (tj. zakładanie kont użytkownikom, edycję treści, dodawanie komentarzy, itp.).

Zacząłem od użycia PHP, który wydawał mi się niezłym kandydatem - wiele firm hostingowych nie oferuje nic innego, język jest dosyć dojrzały i z wersji na wersję coraz szybszy (więcej).
Cała najbardziej podstawowa idea została przeze mnie zaimplementowana w kilka dni (czytanie danych z plików, cachowanie najczęściej używanych danych w bazie danych)... i wtedy pojawiły się pewne wątpliwości.
Funkcjonalność push
PHP jest rzeczywiście wystarczający do wielu zastosowań, ale jego idea w skrócie i uproszczeniu polega na tworzeniu nowego oddzielnego wątku czy procesu przy każdym requeście, interpretowaniu plików PHP i zwróceniu treści (to zajmuje czas).
Załóżmy, że chcemy poinformować użytkownika o zmianie w już otwartej i wyświetlonej przez niego stronie - gdy jeden wątek serwera uaktualnia treść (użytkownik np. wysłał dane z formularza i skrypt zapisał je właśnie po stronie serwera), to jak powiadomić inny wątek obsługujący wysyłanie informacji do przeglądarki o zmianie treści?
Pozostało mi użyć tutaj takich metod jak regularne odpytywanie bazy danych (czyli okropny pooling) albo sprawdzanie, czy data pliku z danymi się nie zmieniła.
Mogłem to rozwiązać również tworząc jednowątkowy serwer w PHP uruchamiany w tle z linii komend (na to jednak nie pozwalają wszyscy dostawcy), albo pójść krok dalej... i rozejrzeć się za alternatywą.
I tak właśnie zacząłem się skłaniać ku Node.js - jest popularny i zbudowany na V8, używa znanego przez wielu JavaScript, działa w uproszczeniu na jednym wątku (obsługa któregoś request może "przytkać" całość i usterka kodu od razu wyłącza całą funkcjonalność serwera, ale równocześnie zyskujemy możliwość współdzielenia danych w RAM) i opiera się na wykonywaniu określonego kodu, gdy zaszło jakieś wydarzenie (ustawiamy callback, który jest wywoływany w odpowiednim momencie).
Po wstępnym wyborze technologii zacząłem się rozglądać za sposobami sprawdzania, czy jakaś treść się zmieniła:
- short pooling - przeglądarka regularnie wysyła request do serwera z odpowiednim pytaniem (co wymaga przesyłania danych, zwiększa zużycie energii, itp.)
- long pooling - jak wyżej, ale serwer odpowiada po długim czasie, gdy nie nastąpiło uaktualnienie
- Server-Side Events - rejestrujemy chęć pobierania danych o zmianach i serwer wysyła nam to, co chce
- WebSockets - bardziej skomplikowane niż poprzednie, ale zyskujemy pełną komunikację w obie strony
Wybrałem SSE (zdecydowała prostota i brak możliwości narobienia szkód po stronie serwera, gdyż dane mogą być przesyłane tylko w stronę przeglądarki) i w Milestone 1 z jego pomocą zaimplementowałem obsługę sprawdzania, czy dodano komentarze na stronie.
Założenia
Dużym problemem node.JS okazał się swoisty urodzaj - większość samouczków rozpoczyna się od słów "żeby zrobić (tu wstawiamy co chcemy) należy pobrać rewelacyjny framework...".
Wielokrotnie to przerabiałem przy okazji różnych technologii - ludzie zamiast pisać w danym języku, często i gęsto idą na skróty i korzystają z wrapperów do standardowych bibliotek/klas/funkcji.
Tutaj miało to uzasadnienie w czasach, gdy HTML raczkował i gdy Microsoft, i inne firmy raczyły nas swoimi rozwiązaniami (wtedy biblioteki takie jak jQuery naprawdę miały rację bytu), obecnie jednak w dobie dwóch czy trzech w trzymających się standardów silników spokojnie wiele rzeczy można zrobić bez sterydów.
Z tej obserwacji pojawiło się moje podstawowe założenie do projektu - chciałem napisać kod prosto, ale bez wspomagaczy.
Dodatkowo postanowiłem, że całość ma być łatwo modyfikowalna, dawać się używać z dużą ilością danych i być jak najłatwiejsza w użyciu.
Struktura katalogów
Możliwie dużą część HTML / CSS / JS przeniosłem do plików zewnętrznych.
Engine w głównej mierze opiera się na ładowaniu tych "template" i zamienianiu odpowiednich znaczników konkretną treścią.
Wspomniane pliki do przetwarzania (+ certyfikaty do HTTPS) zamieściłem w katalogu "internal", gotowe komponenty (w tym zewnętrzny framework Quill do tworzenia kodu HTML w ładnie wyglądającym edytorze "ala Word" i biblioteka do generacji SHA256) poszły do katalogu "external".
Pliki z treścią dodałem do katalogu "teksty", a pliki tekstowe opisujące użytkowników do katalogu "uzytkownicy".
Do tego doszedł plik index.js... i to wszystko.
Format plików
W przypadku treści są to delikatnie zmodyfikowane pliki z Sobieskiego - dodałem m.in. wersjonowanie treści.
Podobny format został użyty do zapisywania informacji o kontach użytkowników - przy czym na razie nie wszystko zostało zdefiniowane, bo engine w wersji Milestone 1 nie ma np. obsługi wiadomości prywatnych.
Te rozwiązania powodują, że wskazane może być przechowywanie odpowiednich katalogów w systemie plików, który posiada kompresję plików w locie (ewentualnie będę musiał zastanowić się nad implementacją kompresji).
Uruchomienie
W przypadku Windows pobieramy nodeJS i uruchamiany serwer komendą "nodejs index.js".
A co jest w index.js?
Przy pisaniu kodu korzystałem z bibliotek dostępnych w standardowym pakiecie (stąd nie trzeba nic doinstalowywać).
Obecny kod:
- renderuje listy z treścią i strony z poszczególnymi tekstami,
- pozwala na tworzenie nowych stron i dodawanie komentarzy (te ostatnie wysyłane są użytkownikom bez przeładowywania stron),
- umożliwia logowanie i wylogowywanie.
Zaimplementowałem kilka flow:
- wszędzie mamy kopie robocze (są widoczne tylko dla autora)
- w Hydepark każdy autor może sam przenieść je do biblioteki (wtedy są widoczne dla wszystkich), w pozostałych sekcjach widzimy listy poczekalni, bety i bibliotekę (dwie pierwsze są publiczne i autor może przenosić tam swoje utwory, ostatnia jest również publiczna, ale przeniesienie tam utworu wymaga akcji admina).
- mamy przyklejanie tekstów na szczycie list i dodawanie ich na główną stronę (może to robić admin)
Początkowo całość oparta była na HTTP/1.1, ale tam ograniczeniem okazała się liczba sesji do serwera (mówiąc inaczej: przy otwartych wielu zakładkach tylko sześć z nich dostawało informacje zwrotne od serwera o uaktualnieniu treści) i przeniosłem mój serwer do HTTP/2.
Serwer dodaje "aż" trzy cookies - jedno dotyczy zalogowanej sesji (nie ma terminu ważności, wygasa po restarcie serwera), drugie trybu dark, a trzecie trybu mobilnego.
Mamy też kompresję gzip/deflate treści i ich minifikację, używanie "preload" z HTTP/2.0, wykorzystywanie parametru "async" w kodzie, jak również cachowanie całości w RAM.
Wygląd
Milestone 1 miał dobrze działać, a nie wyglądać idealnie.
Tak obecnie wygląda strona główna z kilkoma postami (jeden przyklejony, reszta "zwyczajnie" dodana).
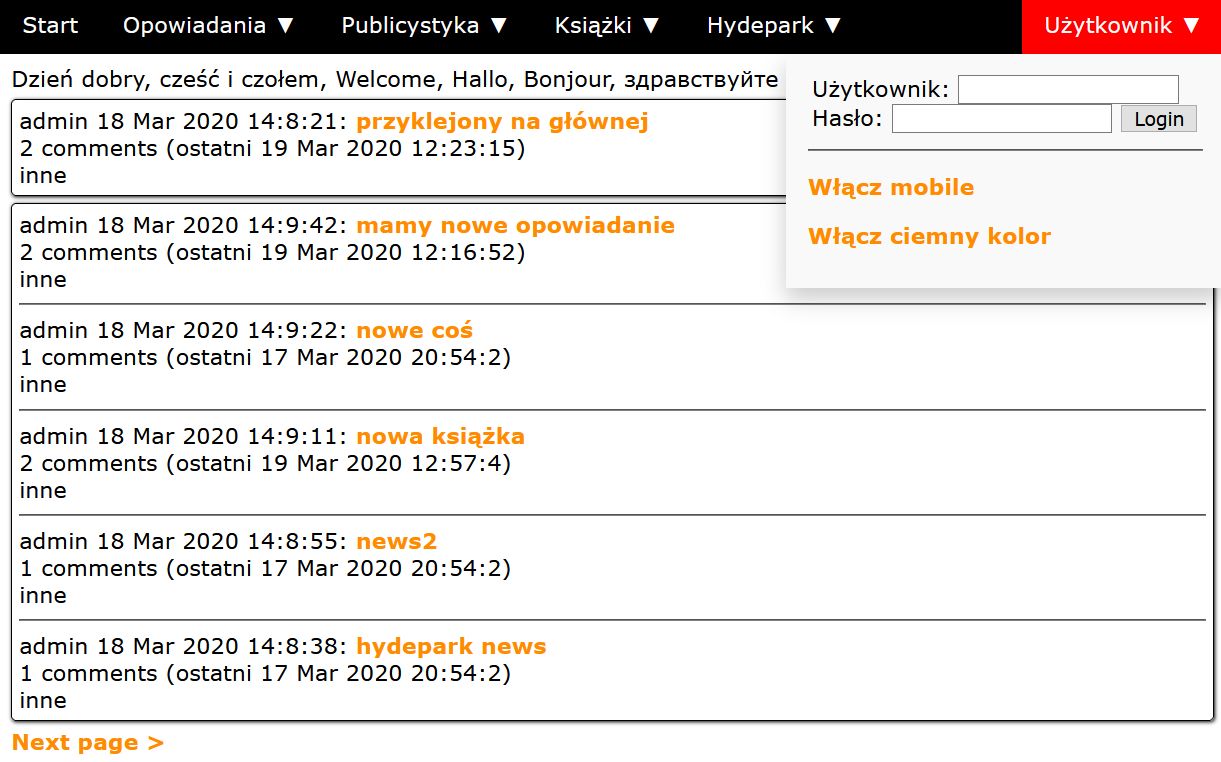
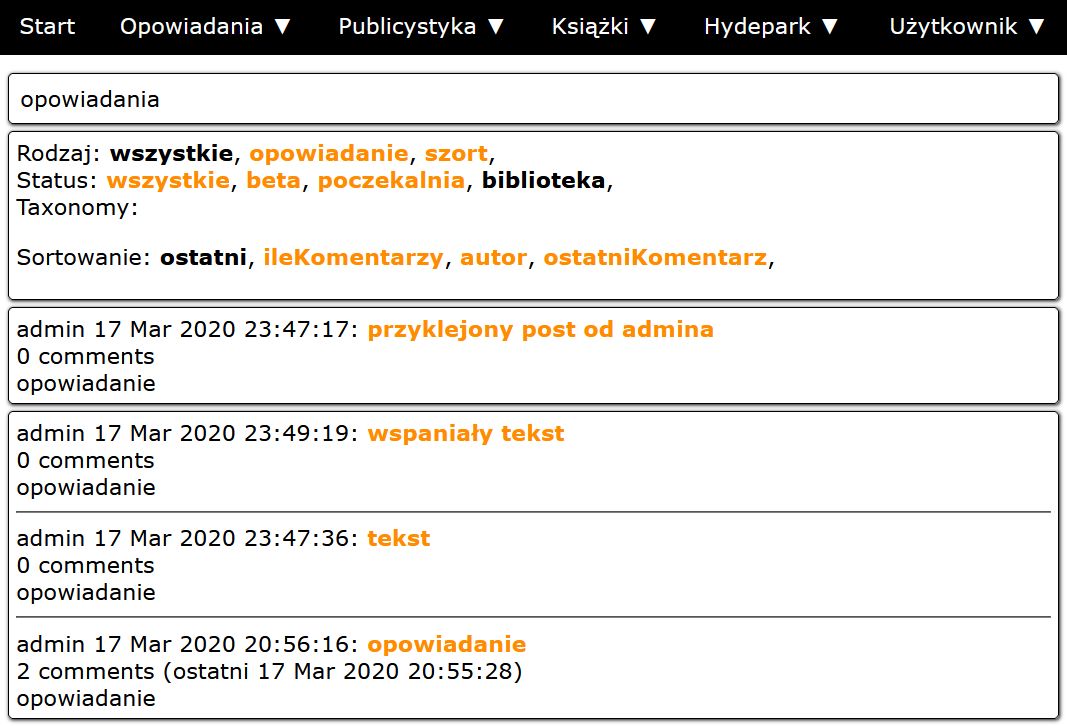
Przy listach mamy jeszcze kryteria wyświetlania
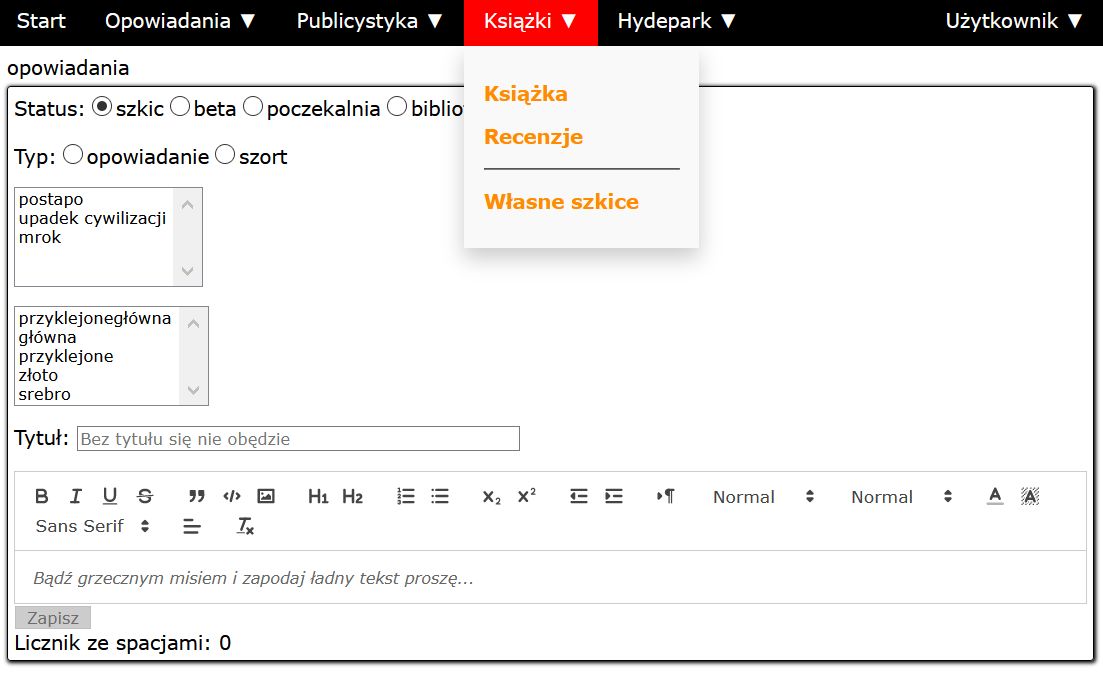
Edycja strony robiona jest bez pisania kodu HTML
...podobnie jest z pisaniem komentarzy (te można dodawać też tylko po zalogowaniu)
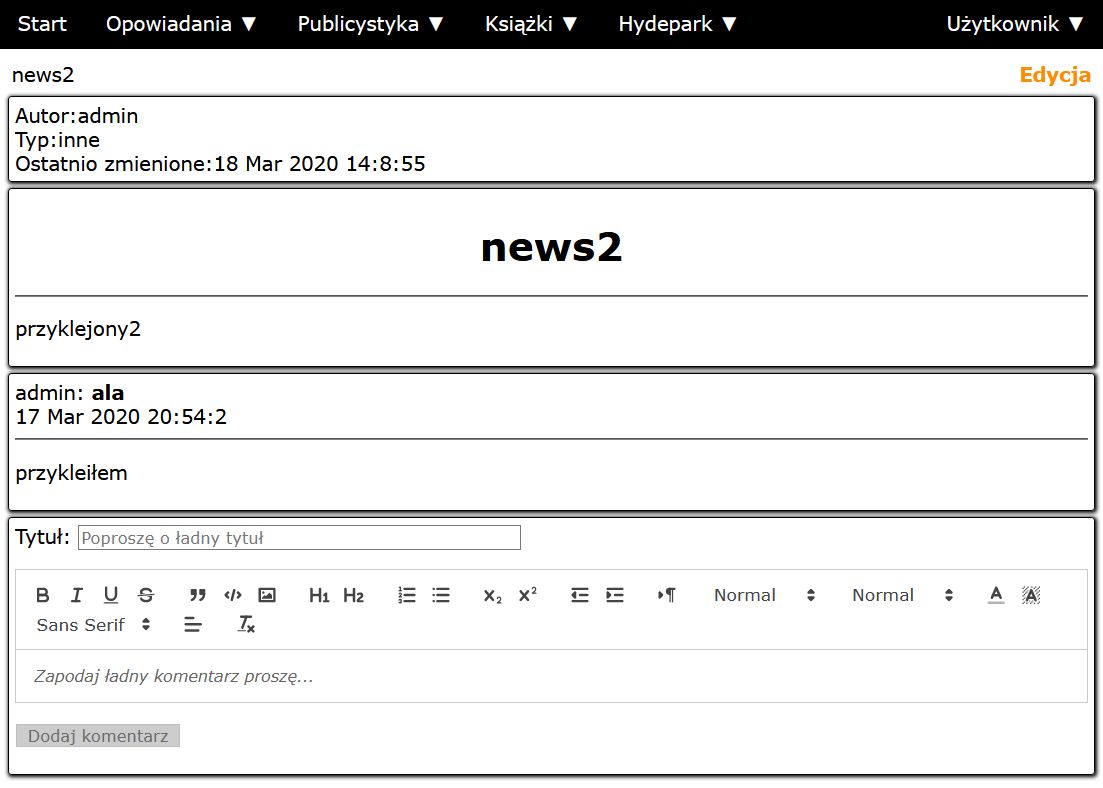
Wzorowałem się trochę na pewnej stronie, którą ostatnio często odwiedzam...
Na ile to jest stabilne i dojrzałe?
Projekt jest w fazie Milestone 1 - kod będzie rozwijany przy zainteresowaniu, wtedy też stanie się bardziej kompaktowy i wyczyszczony (trzeba też dokończyć kilka funkcji, takich jak cachowanie wyłącznie nagłówków plików z treścią zamiast całych plików).
Na dzień dzisiejszy katalog "internal" to ok. 20kB, "external" 251kB (Quill jest jednak duży), a index.js to około 44kB - myślę, że można całość napisać jeszcze znacznie lepiej.
Chciałbym poprawić wydajność - przeciętny czas odpowiedzi to 16ms, choć zdarzają się również dłuższe czasy renderowania stron.
Całość ma kilka znanych błędów, kilka funkcji jest zaimplementowane "eksperymentalnie" (np. hasła są obecnie przechowywane otwartym tekstem w plikach użytkowników, będę je mógł "hashować" po dodaniu funkcji dodawania użytkowników z www).
Projekt nie jest może jeszcze super przygotowany do używania na produkcji (aż ciśnie mi się na usta stwierdzenie, że trzeba go "utwardzić"), ale już obecnie jego dopracowanie jest moim zdaniem całkiem niezłe, a w każdym razie bardzo dobre jak na coś zrobione w kilka dni.
A udostępniam go, bo edukacji nigdy dosyć... szczególnie, że wielu z nas ma teraz dużo wolnego czasu...
A nuż to rozwiązanie zainspiruje kogoś?
Przyszłość
Może Go? (tam kod jest kompilowany natywnie; według różnych źródeł daje to mniejsze zużycie pamięci i lepszą wydajność niż przy node.js)
Może użycie Sobieskiego+ na różnych stronach?
Może przeniesienie struktury do Sobieskiego?
Z chęcią bym nawiązał współpracę z różnymi ludźmi i firmami, kwestia licencji jest otwarta (pewnie zgodziłbym się na MIT lub GPL2 lub Apache)
PS. Zapomniałbym - oto link: https://github.com/marcinwiacek/SobieskiPlus





![Szybki i kompaktowy dysk SSD na USB-C. ADATA SC750 (2 TB) [Recenzja]](https://v.wpimg.pl/OWU5LmpwYDY0VzpeXwxtI3cPbgQZVWN1IBd2T19CdmAtBn1bXwMqND0bOx0TEyF5JVljBB0QYGJgBXhdEUYsemJXdVldQ31gNxguWENAYmIzUHQJQE4rNGxQdUMaByh1KA)
![Smukła, cicha, żywotna i nudna. Myszka Logitech Pebble Mouse 2 [Recenzja]](https://v.wpimg.pl/Njk0LmpwYQsKUjpeXwxsHkkKbgQZVWJIHhJ2T19Cd10TA31bXwMrCQMeOx0TEyBEG1xjBB0QYVxaUSoJQEF6RwhWdVtdQ3kLWx10C0lOYwlfCX1dREB9W10JeEMaBylIFg)
