

Btrfs — elegancki system plików na cywilizowane czasy
Po przeczytaniu tytułu nie trudno domyśleć się o czym będzie traktował ten wpis. Otóż to – w tym wpisie chciałbym przedstawić system plików Btrfs i opisać nieco jego funkcje podając przykłady. Btrfs nie jest dzisiaj zbyt popularnym rozwiązaniem głównie poprzez przekonanie o jego niestabilności. Czy słuszne czy nie – ciężko ocenić. Faktem jest, że większość funkcji tego systemu plików jest już stabilna i można w miarę bez obaw używać ich do pewnych czynności. O stabilności tego systemu plików traktuje FAQ na jego oficjalnym wiki, polecam przeczytać ten punkt, a najlepiej całe FAQ, jeżeli masz chęć go użyć. Można je znaleźć tutaj.
Btrfs został zapoczątkowany w 2007 roku. Został głównie zaprojektowany przez firmę Oracle specjalnie dla Linuksa. Bazuje on na zasadzie CoW (Copy on Write). CoW to technika dla kopiowania lub duplikowania danych polegająca na tym, że dane nie są fizycznie kopiowane dopóki oryginał nie zostanie zmodyfikowany. Zwiększa to wydajność i zmniejsza użycie zasobów poprzez ograniczenie używania niepotrzebnych operacji kopiowania. W momencie żądania skopiowania danych zwracany jest wskaźnik na „skopiowane” dane, które fizycznie są kopiowane dopiero wtedy, jak oryginał zostaje zmodyfikowany. Ta technika jest szeroko wykorzystywana nie tylko w systemach plików, ale także w zarządzaniu pamięcią i innych. Btrfs używa B‑drzewa (stąd też podaje się rozwinięcie nazwy systemu plików jako „B‑tree File System") jako struktury przechowywania danych. Sam system plików powstał jako odpowiedź na braki w systemach plików Linuksowych, które nie zapewniały same z siebie takich funkcji jak np. snapshoty czy sumy kontrolne.
Warto dodać, że te funkcje zapewnia ZFS (system plików pierwotnie dla Solarisa, dzięki otwarciu kodu znalazł potem też miejsce w innych systemach jak np. FreeBSD), który powstał przed Btrfs. Niestety licencja ZFS (CDDL) uniemożliwia bezpośrednie włączenie jego kodu bezpośrednio do jądra Linux. Btrfs powstaje jako alternatywa dla niego będąca bezpośrednią częścią jądra. ZFS dzisiaj cieszy się jednak znacznie większą popularnością, głównie ze względu na dopracowanie i przetestowanie. Chociaż i Linuksowy twór też znajduje swoje zastosowanie w biznesie – Facebook używa go na części swoich serwerów. Sam Theodore Ts’o (deweloper systemów plików ext) określa go jako przyszłość Linuksa.
Najważniejsze możliwości
Btrfs jest prawdopodobnie najbardziej zaawansowanym systemem plików dostępnym bezpośrednio w jądrze Linux. Stąd też zapewnia całkiem sporo możliwości a i w planie są kolejne. Sprawdźmy więc co on potrafi.
Sumy kontrolne
Btrfs wylicza sumy kontrolne dla każdego pliku by zapewnić jego poprawność. Używa do tego funkcji crc32c. Zwiększa to pewność poprawności danych.
Przezroczysta kompresja
Jedna z największych funkcji tego systemu plików. Przezroczysta kompresja pozwala na kompresowanie plików na poziomie systemu plików (programy z nich korzystające nie „zauważą” żadnej różnicy) dzięki czemu pozwala oszczędzić miejsce na dysku, a także, w pewnych przypadkach, zwiększyć szybkość odczytu. Aktualnie są dostępne dwa algorytmy kompresji – zlib (domyślny w przypadku braku sprecyzowania opcji) i lzo, planowany jest także lz4 znany z ZFS. Zlib ma wyższy stopień kompresji jest jednak wolniejszy, lzo jest szybszy, lecz kosztem gorszego stopnia kompresji. Montując system plików możemy sprecyzować 2 opcje – są to compress lub compress-force (w każdej opcji możemy sprecyzować algorytm kompresji poprzez wpisanie jego nazwy po znaku '=' np. compress=lzo). Druga opcja różni się od pierwszej tym, że wymusi kompresję na plikach, które nie kompresują się dobrze, lub zostały oznaczone by nie używać kompresji. Możliwe jest wyłączenie kompresji dla wybranego katalogu/pliku poleceniem:

btrfs property set <plik> compression ""
Wybrany plik nie będzie kompresowany do czasu wyczyszczenia flagi poprzez użycie powyższego polecenia precyzując algorytm, lub poleceniem: [code=shell]chatrr +c[/code] Warto dodać, że jeżeli system plików został zamontowany z opcją wymuszającą kompresję nie będzie brał pod uwagę tej flagi. Kolejną sprawą jest to, że włączając/wyłączając kompresje dla danego pliku jego stan nie zostanie zmieniony – będzie to dotyczyło tylko nowych danych. Można jednak wymusić kompresję poprzez defragmentacje poleceniem [code=shell]btrfs filesystem defragment -c <system_plikow>[/code]
Subwoluminy (ang. subvolumes)
Kolejna duża funkcja Btrfs. Na tyle, że zaprezentuje ją praktycznie. Subwoluminy to niezależnie montowane drzewo plików POSIX i nie może być traktowane jako urządzenie blokowe (bo nim nie jest). Większość systemów plików Uniksowych posiada jeden katalog główny (określany jako /), który jest najwyższym możliwym katalogiem. Btrfs również takowy posiada, jednak może mieć ich więcej właśnie dzięki subwoluminom. W ramach subwoluminów można tworzyć kolejne, a także przechowywać tam dane. Najwyższy subwolumin Btrfs (zawsze o ID 5) jest tworzony automatycznie przy formatowaniu partycji i nie może być usunięty. W jego ramach możemy tworzyć także inne, za pomocą polecenia: [code=shell]btrfs subvolume create /katalog/nazwa[/code]
W systemie są one widoczne jako zwykłe katalogi, jednak mają swoją cechę unikalną – mogą być zamontowane tak, by były głównym katalogiem systemu plików. Umożliwia to opcja montowania subvol=nazwa. Możliwa jest też miana domyślnego subwoluminu z głównego na inny poleceniem:
btrfs subvolume set-default subvolume-id /
Wracając jednak do opcji subvol – po jej użyciu dany subwolumin zostanie użyty jako główny katalog systemu plików i tak właśnie będzie widoczny w zamontowanym katalogu.
Żeby to lepiej zaobrazować przedstawię to praktycznie używając mojego Antergosa, na którym pracuję na co dzień i który używa Btrfs na partycji /. Dla ułatwienia posłużę się jednak plikiem. Tworzę więc plik o wielkości około 300MB programem dd, następnie formatuję go na Btrfs poleceniem:
mkfs.btrfs plik.img
montuję w katalogu /mnt. Narazie bez żadnych opcji.
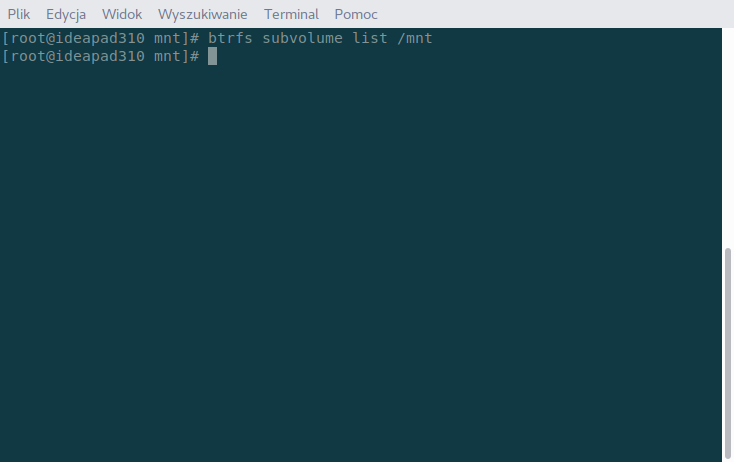
Jak widać nic tutaj nie ma. Dlatego stwórzmy sobie jakieś subwoluminy. Nazwę je SUBVOL1 i SUBVOL2.
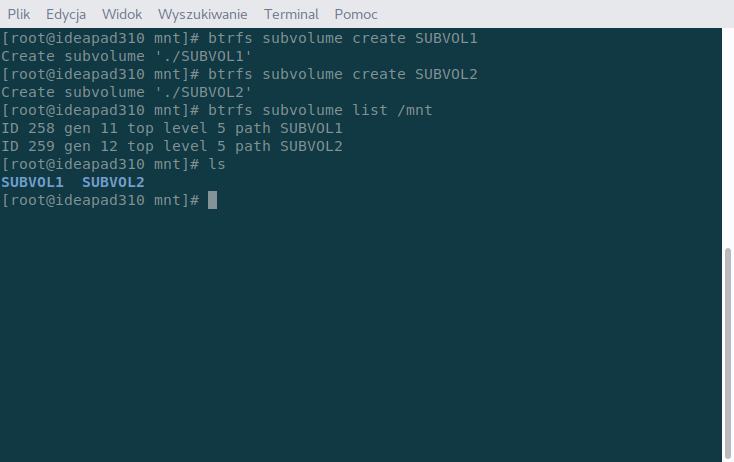
Subwoluminy zostały stworzone. Jak widać, są widoczne jako zwykłe katalogi. Teraz odmontujemy obraz partycji i zamontujemy go precyzując subwolumin za pomocą polecenia (zamiast opcji subvol można też użyć opcji subvolid i podać ID odczytane podanym wyżej poleceniem) :
mount -t btrfs -o subvol=SUBVOL1 /plik.img /mnt
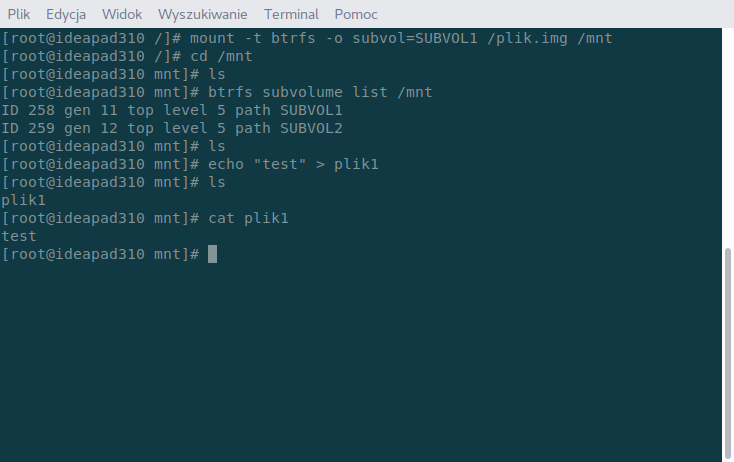
Jak widać teraz SUBVOL1 jest głównym katalogiem i obecnie nie możemy przeczytać zawartości SUBVOL2 za pomocą ls, gdyż nie mamy do niego już dostępu. Na zamontowanym subwoluminie możemy robić wszystko to, co na normalnej partycji z tą różnicą, że wszelkie dane są zapisywane właśnie w sprecyzowanym subwoluminie, a reszta jest nieruszana. Odmontujmy teraz obraz, zamontujmy go ponownie bez precyzowania opcji.
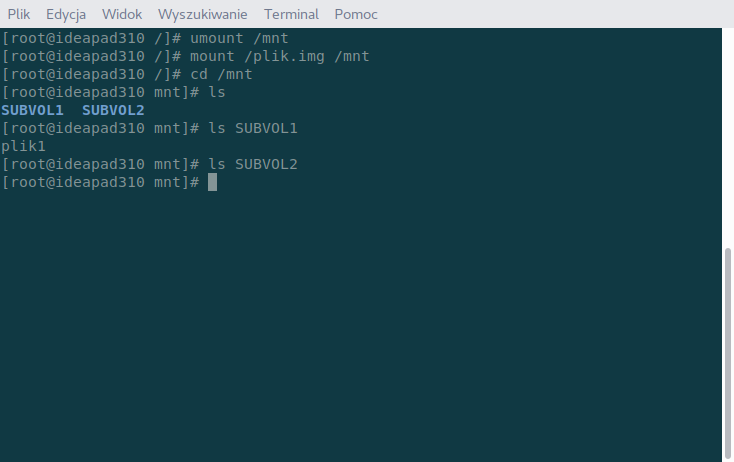
Myślę, że to wystarczający przykład działania subwoluminów. Można ich także użyć do symulowania partycji – stworzyć ich wymaganą ilość i zamontować do różnych katalogów (np. do / i do /home). Z punktu widzenia programów będą to niezależne partycje, z punktu widzenia systemu plików wszystko będzie się odbywało na jednej partycji.
Niestety subwoluminy mają też jedną wadę – nie da się ich montować z różnymi opcjami. Przy montowaniu kilku subwoluminów tylko opcje montowania pierwszego zostaną odczytane. To braki w implementacji i jest możliwość, że w przyszłości zostanie to poprawione (chociaż wierząc wiki nie będzie to proste zadanie ze względu na specyfikę VFS Linuksa).
Migawki
Kolejna ciekawa opcja bardzo mocno powiązana z poprzednią. Btrfs pozwala tworzyć migawki dla wybranego subwoluminu. Migawka jest tworzona niemal natychmiast dzięki technice CoW. Ta sama technika sprawia też, że migawka początkowo nie zajmuje dużo miejsca – zacznie rosnąć w miarę zmian w skopiowanym subwoluminie. Sama migawka z poziomu systemu plików niczym nie różni się od subwoluminu – odróżnia ją tylko to, że została stworzona jako kopia subwoluminu, nie od zera. Za pomocą migawki możemy przywrócić subwolumin do stanu, w którym był w momencie jej tworzenia. Jest to przydatna opcja, którą można wykorzystać w razie np. awarii po aktualizacji czy skasowania niechcący ważnego pliku. Należy jednak pamiętać o odpowiedniej wielkości partycji – migawka w najgorszym razie może przyjąć rozmiar subwoluminu w momencie jego klonowania. Dzięki technice CoW można być jednak pewnym, że nie będą niepotrzebnie dublowane dane.
Sprawdzimy sobie tę opcję w praktyce. Jak pewnie pamiętacie z poprzedniego punktu – na SUBVOL1 znajduje się plik tekstowy o nazwie plik1 z zawartością „test”. Do testu stworzę jeszcze jeden plik o nazwie plik2. Zrobimy sobie teraz migawkę SUBVOL1 o nazwie SUBVOL1-SNAPSHOT i zmodyfikujemy zawartość pliku plik1 oraz skasujemy plik2, a następnie podejrzymy jak się przedstawia zawartość migawki. Migawki tworzymy poleceniem:
btrfs subvolume snapshot nazwa nazwamigawki
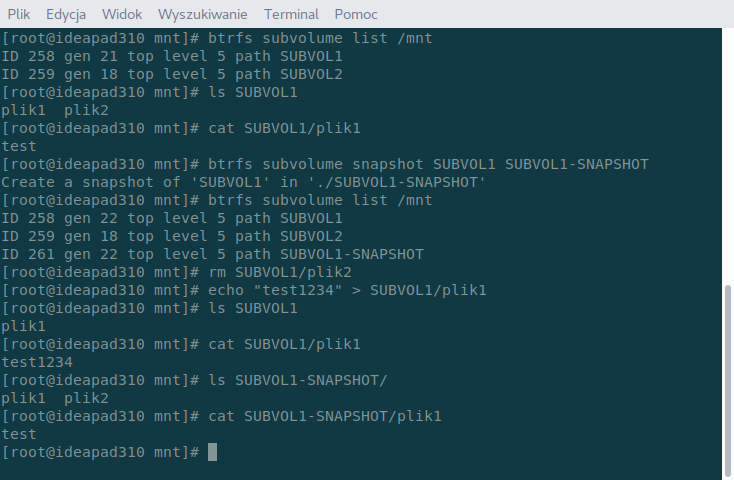
Myślę, że nic więcej wyjaśniać nie trzeba. Teraz w razie konieczności możemy cofnąć subwolumin do jego migawki. Aby to zrobić wystarczy go skasować poleceniem:
btrfs subvolume delete nazwa
i po prostu użyć polecenia mv zmieniając nazwę migawki na nazwę subwoluminu.
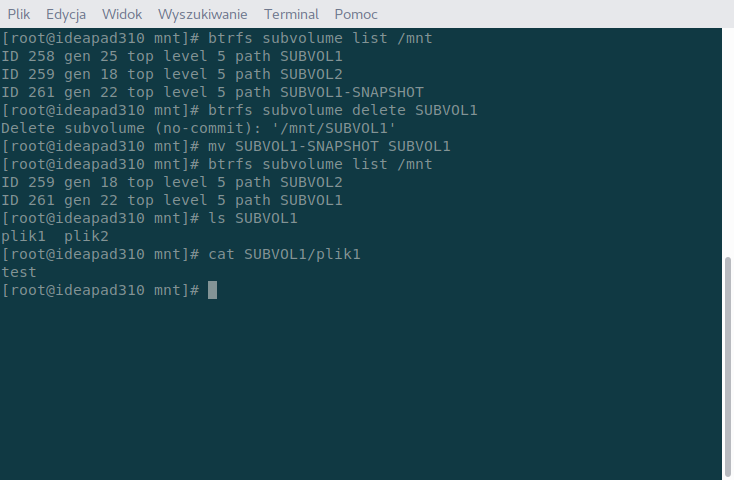
To wszystko. Zauważyć należy jednak, że ID subwoluminu uległo zmianie na takie, jakie miała migawka. Dlatego bezpieczniej odwoływać się po nazwie. No chyba, że po przywróceniu migawki zadbacie o poprawę ID w bootloaderze czy /etc/fstab.
Deduplikacja
Jedna z najważniejszych funkcji Btrfs, która bywa też podawana jako główna zaleta jego konkurenta, czyli ZFS. Deduplikacja pozwala zredukować ilość zajmowanego miejsca poprzez złączenie powtarzających się danych w jedno. Jej zastosowania mogą być różne, w Linuksie często mówi się o połączeniu deduplikacji z kontenerowaniem aplikacji. Snap, Flatpak czy AppImage rozwiązują problem z mnogością dystrybucji poprzez dystrybuowanie aplikacji wraz ze wszystkimi potrzebnymi jej zależnościami. Jednak w przeciwieństwie do tradycyjnych zależności współdzielonych zajmuje to więcej miejsca na dysku – każda aplikacja ma swoje zależności i nie baczy na inne. To powoduje, że możemy mieć na dysku wiele kopii tej samej biblioteki. Deduplikacja jest rozwiązaniem tego problemu – powinna wyłapać powtarzające się dane i złączyć je w jedno.
Niestety Btrfs, w przeciwieństwie do ZFS, nie obsługuje jeszcze deduplikacji w trakcie. Oznacza to, że Btrfs nie jest w stanie dokonać deduplikacji w czasie zapisywania danych. Można ją wykonać dopiero po zapisaniu danych za pomocą dedykowanych narzędzi takich jak dedupremove, bedup albo btrfs-dedupe. Taki rodzaj deduplikacji jest nazywany „offline”, chociaż to nazwa dość myląca (bo jest wykonywana na zamontowanej i pracującej partycji), więc lepiej używać nazwy „out of band deduplication” lub „batch deduplication”.
Pracę nad deduplikacją w trakcie zapisu danych trwają i są już gotowe łatki, które jednak są określone jako eksperymentalne i przez to nie są jeszcze załączone do głównego kodu Btrfs. W przyszłości można się spodziewać włączenia ich do głównego kodu.
Wbudowana obsługa wielu urządzeń
Podobnie jak ZFS, Btrfs ma też wbudowaną obsługę wielu urządzeń, czyli RAID. RAID w największym skrócie to sposób wykorzystania dwóch lub więcej dysków twardych, które ze sobą współpracują. Jak ktoś chce wiedzieć więcej, to polecam przeczytać o tym tutaj. Tworzenie macierzy RAID w Btrfs jest dość proste – trzeba po prostu sprecyzować więcej urządzeń w poleceniu mkfs.btrfs. Żeby to pokazać użyję maszyny wirtualnej (z 3 wirtualnymi dyskami o wielkości 1GB każdy), na której wystartuję Arch Linuksa z obrazu płyty.
Stworzenie macierzy w Btrfs nie jest specjalnie skomplikowane. Wystarczy uruchomić mkfs z opcją -d raid0 i podać urządzenia, na których ma być macierz utworzona. W maszynie wirtualnej są to /dev/sda, /dev/sdb i /dev/sdc. Tak więc komenda wygląda tak: [code=shell]mkfs.btrfs -d raid0 /dev/sda /dev/sdb /dev/sdc[/code]
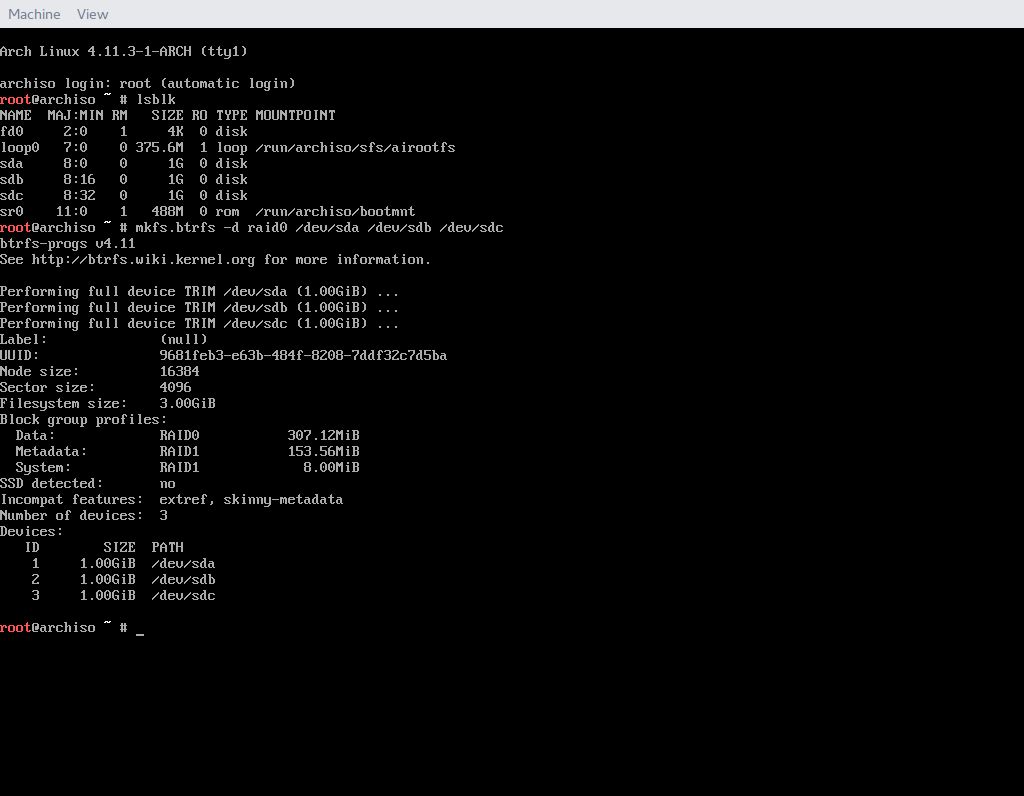
W celu zamontowania tak stworzonej macierzy wystarczy wywołać komendę mount i podać dowolne urządzenie wchodzące w skład macierzy. Tak więc montujemy i sprawdzamy.
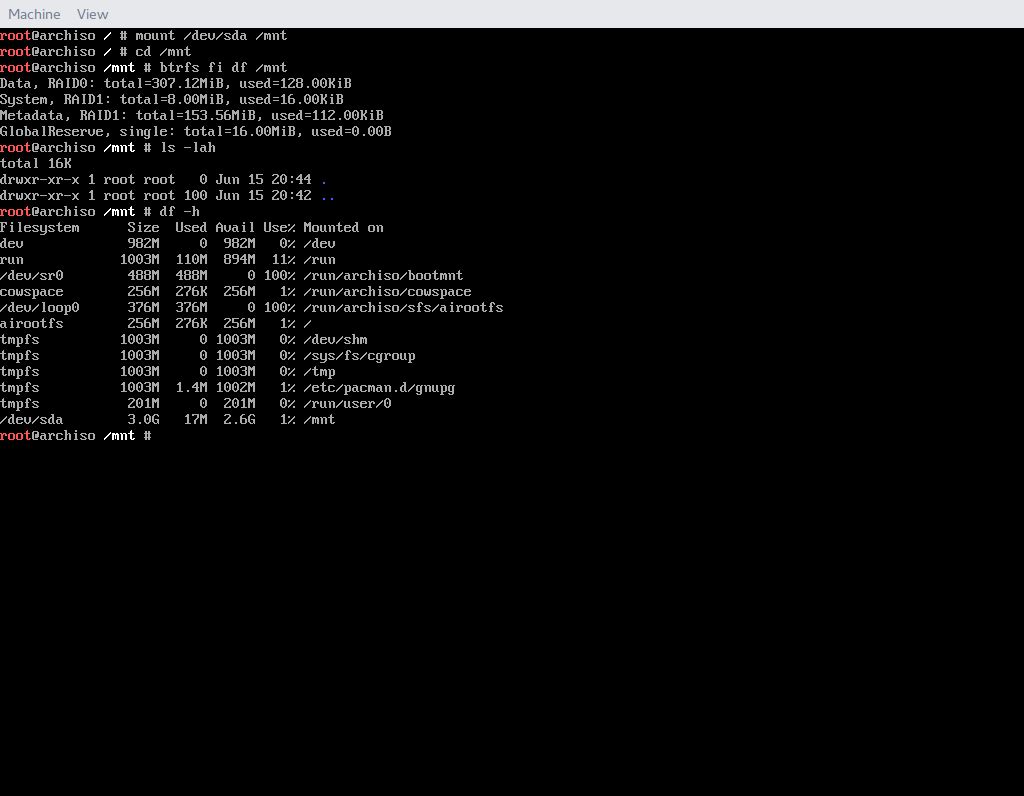
Jak widać macierz została zamontowana poprawnie i polecenia pokazują, że urządzenia zostały połączone w RAID0. Komendzie df nie ma co ufać w przypadku Btrfs (zdarza jej się pokazywać błędnie ze względu na jego specyfikę) jednak w tym przypadku pokazuje rozmiar przestrzeni na 3GB, co jest łączną przestrzenią 3 wirtualnych dysków po 1GB każdy.
Wydaje mi się, iż opisałem najważniejsze funkcje Btrfs, które wyróżniają go na tle innych systemów plików. Oczywiście to nie wszystko i zawiera ich znacznie więcej. O jego wszystkich funkcjach czy cechach można przeczytać tutaj.
Wady
Niestety Btrfs pomimo swojego zaawansowania ma też i wady. Oto część z nich (porównanie do ZFS celowe, w końcu Btrfs ma być jego odpowiednikiem): -Brak deduplikacji inline – wspominałem o tym w poprzednim punkcie. Btrfs jeszcze nie umożliwia deduplikacji w trakcie działania. Jedyna opcja to jej wykonanie po zapisaniu danych. Oczywiście ZFS nie ma z tym problemu.
-Brak wbudowanego szyfrowania – Btrfs nie posiada wbudowanego szyfrowania, podobnego jak ZFS. Nie jest w stanie szyfrować danych na poziomie systemu plików (tak jak kompresować). Można wprawdzie wykorzystać dm‑crypt/LUKS lub ecryptfs i szyfrować dane poza systemem plików, ale wbudowana funkcja znacząco by to ułatwiła. Póki co nikt nie pracuje nad tą funkcją, lecz jest możliwość pojawienia się jej w przyszłości.
-Brak algorytmu LZ4 w kompresji – LZ4 jest wydajnym algorytmem kompresji, który jest używany przez ZFS. LZ4 jest szybszy niż LZO (jedna z opcji Btrfs) oferując podobny stopień kompresji. Niestety deweloperzy Btrfs póki co nie widzą sensu jego implementacji, argumentując to tym, że jego implementacja wymagałaby dodatkowej pracy w celu jego obsługi.
-Gorsza wydajność – Dotyczy to też ZFS. Btrfs jest wolniejszy niż mniej rozbudowane systemy plików (jak np. ext4 czy xfs), co jest szczególnie zauważalne przy pracy na wielu plikach na powolnym dysku (nie polecam używać Btrfs jako / na laptopowym HDD – instalacja czy aktualizacja wielu pakietów naraz trwała u mnie wieki). Ta wada wynika z jego projektu – nacisk jest kładzony na funkcjonalność, nie na szybkość. Stąd też Btrfs nie nadaje się do zadań, gdzie liczy się jak najwyższa wydajność. Nadaje się natomiast do zadań, gdzie narzut na wydajność nie jest szczególnie istotny. Do codziennego używania polecałbym jednak mieć dobry dysk, który zredukuje narzut do akceptowalnego poziomu – chociaż na moim niedrogim SSD jego szybkość też jest akceptowalna.
-Nie pełna stabilność – Nie wszystkie funkcje Btrfs są w pełni stabilne, a niektóre są oznaczone jako niestabilne. Wymaga to rozwagi przy używaniu jego funkcji. Status poszczególnych funkcji można znaleźć tutaj.
-Niedostateczne przetestowanie – Nie jest to wada wynikająca z samego systemu plików, ale go dotyczy. ZFS jest stosowany w wielu zastosowaniach i nie sprawia w nich problemów – cieszy się sporym zaufaniem. Btrfs nie jest tak powszechnie stosowany, dlatego też wielu ludzi jest w stosunku do niego nieufna. Chociaż biorąc pod uwagę powyższy punkt może to i lepiej – lepiej poczekać aż wszystkie jego aspekty zostaną odpowiednio dopracowane niż zrażać do niego ludzi niedopracowanymi funkcjami. Chociaż z drugiej strony brak powszechności oznacza małą ilość zgłaszanych błędów – deweloperzy czy testerzy nie są w stanie przetestować wszystkich wariantów praktycznego używania.
Zakończenie
Na tym ten wpis się kończy. Wydaje mi się, że przedstawiłem najważniejsze funkcje oraz wady tego jakże ciekawego systemu plików. Czy warto go stosować? Jeżeli jakaś jego funkcja Ci się przyda i jest stabilna to tak. Jeżeli nie, to nie. Sam robię użytek z kompresji, która pozwala mi zaoszczędzić miejsce na niewielkim SSD i migawek, które pozwalają mi łatwo przywrócić system w razie awarii (póki co nie musiałem z nich korzystać, oby tak pozostało). Czy ZFS nie byłby lepszym rozwiązaniem? Pewnie by był, ale Btrfs jest dostępny od razu w jądrze i nie ma potrzeby instalować dodatkowych modułów. Póki co nie zaobserwowałem żadnych problemów, pomimo tego, że kilka razy wystąpiło siłowe wyłączenie komputera w trakcie jego pracy. Dziękuję za przeczytanie wpisu i zapraszam do komentowania.





![Ergonomiczna, bezprzewodowa klawiatura. Logitech Wave Keys [Recenzja]](https://v.wpimg.pl/M2EzLmpwYlMkGDpeXwxvRmdAbgQZVWEQMFh2T19CdAU9SX1bXwMoUS1UOx0TEyMcNRZjBB0QYgBwH3hbREF8H3JDLgldQy4CfVcuXRYSYAEmH3gORE8rAHYbf0MaByoQOA)

