

Kopia zapasowa — cóż to takiego? cz. II — backup w systemie Linux
Kopia zapasowa jest bardzo ważnym elementem dzisiejszej informatyki. Trwałość obecnych nośników danych jest dość wysoka, ale zawsze istnieje ryzyko awarii. Niedawno opublikowałem pierwszą część mojej serii o kopiach zapasowych. W pierwszym epizodzie skupialiśmy się głównie na macierzach dysków. Jakie zadanie mają macierze? Przypomnijmy - mają służyć do szybkiego wznowienia pracy po awarii sprzętowej jednego lub więcej nośników danych. W tym wpisie zajmiemy się naszym głównym celem - backupami plików, kopiami zapasowymi. Poznamy metody ich szybkiego i łatwego wykonywania. W tej części zajmiemy się systemem operacyjnym Linux. Dowiemy się też co nieco o kolejnych nośnikach przechowywania danych.
Gdzie mogę przechowywać kopie zapasowe?
W poprzednim epizodzie zajmowaliśmy się nośnikami optycznymi i dyskami twardymi - wszak to jedne ze starszych i bardziej popularnych mediów, na których możemy przechowywać dane. Warto także zwrócić uwagę na inną parę nośników. Jeden z rodzajów, usługą chmurową zwany, zdobył dość sporą popularność. „Chmura” jest zintegrowana zarówno z najnowszymi produktami ze stajni Redmond, jak i Mountain View. Drugi nośnik stanowi natomiast lokalną, stojącą w domu, całkowicie darmową wariację dysków sieciowych.

O czym mowa?

Onedrive, Dropbox, Google Drive, Mega - te popularnie zwane “chmury” są ostatnimi czasy niezwykle popularnym tematem. Możemy za darmo przechowywać w nich określoną ilość danych. Do tych plików, dzięki przechowywaniu ich na dyskach internetowych gigantów, mamy dostęp z każdego miejsca na świecie. Wierzymy, że nasze dane w usługach chmurowych są dobrze zabezpieczone. Wszak, podobno wszystkie docierające tam pliki są szyfrowane w locie i ludzie obsługujący ten system nawet jeśli by chcieli, to nie mogą ich odczytać. Microsoft dwa lata temu poinformował, że do swoich usług Onedrive oraz Outlook wprowadza szyfrowanie TLS oraz mechanizm PFS, który ma utrudnić ewentualne odszyfrowanie danych przez napastnika, który dysponuje większą mocą obliczeniową. Na ile możemy wierzyć słowom prezesów wielkich firm z Redmond czy Mountain View? To już należy ocenić samemu.

Dla wszystkich, którzy mają wątpliwości, o których wspominałem powyżej, przeznaczone jest drugie rozwiązanie. Mowa o domowym serwerze NAS. Network Access Storage jest to mini-serwer z zamontowanym dyskiem twardym o dużej pojemności, który umożliwia przechowywanie naszych plików. Powstaje pytanie - czy również w tym wypadku do zapisanych plików będziemy mieli dostęp z dowolnego miejsca? Najprawdopodobniej tak - dla niedoświadczonych użytkowników producenci domowych dysków NAS udostępniają aplikacje - dla komputerów i telefonów. Konfiguracja urządzenia, aby współpracowały z takimi programami jest banalnie prosta i sprowadza się do kilku kliknięć. Większość serwerów NAS, nawet tanich, bazuje na Linuksie. Oznacza to całkowitą swobodę w konfiguracji. Jeśli nie chcemy korzystać z aplikacji producentów, możemy sami wyprowadzić odpowiedni ruch na zewnątrz. Przez odpowiednie przekierowania portów na routerze możemy umożliwić dostęp do naszych danych przez Internet. Przykładem taniego NASa jest WD My Cloud. Jeśli mamy trochę więcej pieniędzy, zawsze możemy się skusić na rozwiązania Synology.
Rodzaje kopii zapasowych
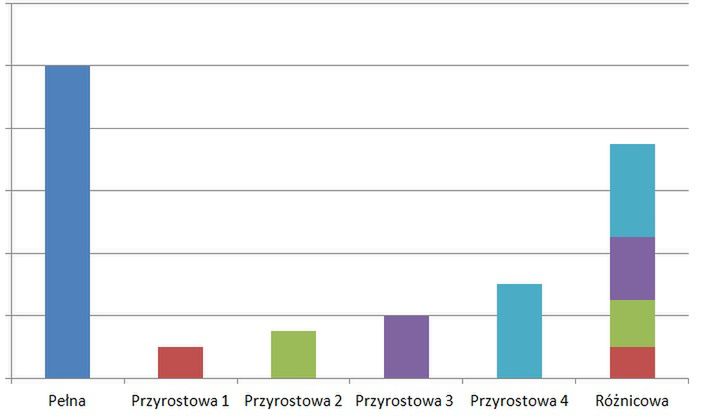
Istnieją trzy rodzaje kopii zapasowych: pełna, różnicowa oraz przyrostowa. Czym one się różnią? Zobaczmy: Kopia pełna, jak sama nazwa wskazuje, zapisuje wszystkie dane. Na przykład, jeśli nasza praca magisterska, mająca 10 megabajtów, zostanie skopiowana z jednego dysku na drugi to będzie to pełna kopia zapasowa. W obydwu miejscach będzie przecież zapisany cały plik. Tzw. full backup ma kilka wad - wykonuje się długo, a jeśli wykonywany jest często, to zajmuje sporą ilość miejsca. Jednakże podstawowa zasada mówi, że abyśmy mogli skorzystać z dwóch pozostałych rodzajów backupu, to najpierw musimy wykonać pełną kopię zapasową.
Kopia różnicowa - Załóżmy, że wcześniej przekopiowaliśmy naszą pracę magisterską na drugi dysk. Następnego dnia wprowadziliśmy w niej szereg zmian. Jeśli następną kopią będzie kopia różnicowa, to zapisany zostanie nie cały plik - a jedynie poczynione przez nas zmiany od momentu wykonania ostatniego pełnego backupu. Kopia różnicowa wykonuje się dość szybko, przywraca się również prędko. Istnieje jednak pewna wada. Przypuśćmy, że następnego dnia w naszej pracy zmieniliśmy tylko jeden wyraz. Nie mniej, w kopii zapasowej z tego dnia będzie odnotowana zmiana tego jednego wyrazu, a także wszystkie inne zmiany dokonane od czasu wykonania ostatniego pełnego backupu. Kopia zapasowa zajmuje więc więcej miejsca, niż faktycznie powinna.
Jako lekarstwo na bolączki kopii różnicowej możemy zastosować kopię przyrostową. Na czym ona polega? Pierwszy incremental backup zapisuje różnice (podobnie jak kopia różnicowa) między wprowadzonymi zmianami a ostatnią pełną kopią zapasową. Różnica w działaniu tych dwóch rodzajów backupu ujawnia się w momencie, kiedy chcemy wykonać drugą kopię przyrostową. Wtedy brane są pod uwagę zmiany wprowadzone nie od momentu pełnego backupu, a od momentu wykonania ostatniej kopii przyrostowej. Dzięki temu miejsce jest bardzo optymalnie wykorzystywane, a czas wykonywania kopii jest bardzo krótki. Podobnie jak każde rozwiązanie, także i to posiada wady. Jest nią długie przywracanie danych i konieczność trzymania wszystkich backupów przyrostowych. Jeśli utracimy jeden z plików - nie przywrócimy danych. (W przypadku kopii różnicowej do przywrócenia danych potrzebujemy jedynie ostatniego backupu różnicowego oraz backup pełny).
Wykonujemy kopię zapasową w Linuksie
Niestandardowo nasze rozważania rozpoczniemy od systemu operacyjnego Linuks. Mamy tutaj do dyspozycji głównie rozwiązania konsolowe. Jednakże, wystarczy je raz dobrze skonfigurować, aby mieć spokój na długi czas. Najpierw nauczymy się wykonywać kopie zapasowe na innym dysku, który posiada linuksowy system plików. Zresztą, jak dobrze wiemy, systemy plików takie jak ext4 czy btrfs są o lata świetlne przed microsoftowym NTFS-em. Zaczniemy od znanego pewnie tutejszej społeczności programu rsync.
Rsync - podstawowa kopia zapasowa
Rsync jest jednym z niewielu darmowych narzędzi posiadających tak ogromne możliwości w zakresie synchronizacji plików. Możemy za jego pomocą robić proste kopie, polegające po prostu na skopiowaniu danych z jedno miejsca na drugie. Dostępna jest możliwość robienia kopii różnicowych czy przyrostowych. Jeśli chcemy, możemy przeglądać także historię zmian. Niestety, narzędzie to jest dostępne jedynie z poziomu wiersza poleceń, co pewnie odstraszy większość osób mniej zaznajomionych z komputerem od jego używania. Jest to błędem, gdyż rsync jest niezwykle prosty w obsłudze.
Załóżmy, że będziemy synchronizowali katalog domowy użytkownika z dyskiem zamontowanym w katalogu /media/dysk_na_kopie.
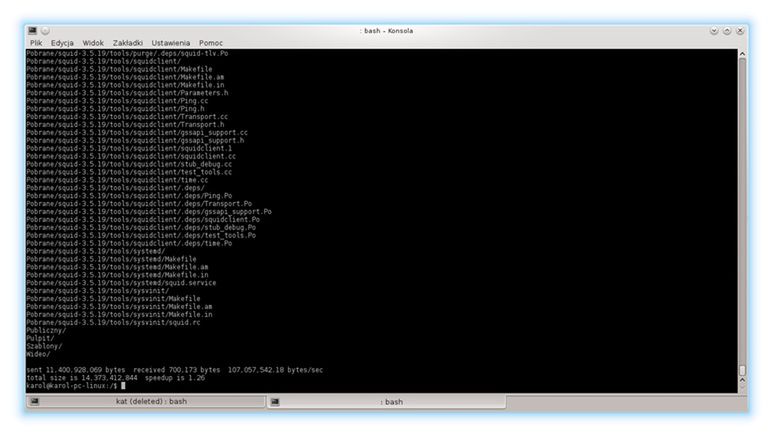
Zacznijmy od prostej synchronizacji plików między dwoma katalogami (utworzenia pełnej kopii zapasowej). Będziemy musieli użyć polecenia rsync z przełącznikiem -a. Możemy dodać opcję v aby widzieć, co się dzieje podczas tworzenia backupu. Następujące polecenie zrobi pełną kopię zapasową katalogu domowego użytkownika do folderu full_backup na partycji docelowej.
sudo rsync -av /home/karol/ /media/dysk_na_kopie/full_backup
Przyjrzyj się zrzutowi ekranu, który znajduje się nieco wyżej. Zastanówmy się teraz, czy wykonywanie kopii zapasowej folderu Pobrane ma sens? Raczej nie. Wykluczmy niechciane foldery z procesu synchronizacji.
sudo rsync -av --exclude ‘Pobrane’ --exclude ‘Publiczny’ --exclude ‘Pulpit’ /home/karol/ /media/dysk_na_kopie/full_backup
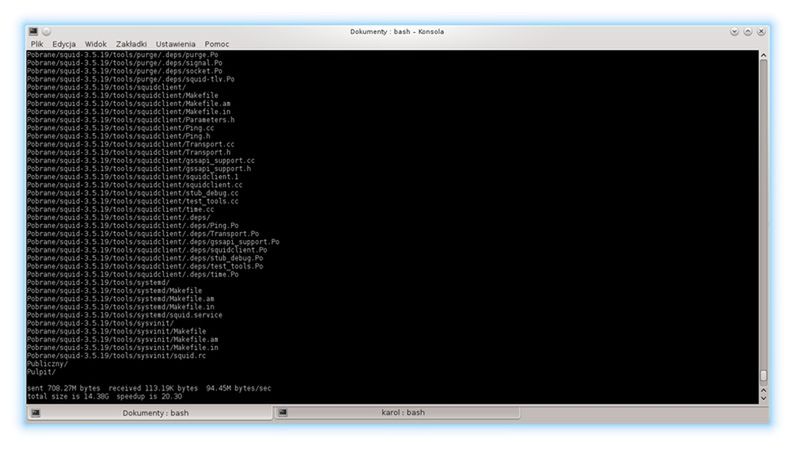
Wynik polecenia widać na screenie powyżej. Tym razem niepotrzebne katalogi nie zostały wzięte pod uwagę podczas procesu synchronzacji.
Wiemy już, jak w najprostszy sposób wykonać pełną kopię zapasową. Co z innymi rodzajami - różnicowymi i przyrostowymi? Za pomocą rsync możemy wykorzystać mechanizm tzw. “twardych powiązań” - hard links. Jeśli dany plik nie został zmodyfikowany od czasu wykonania ostatniego backupu, w najnowszej kopii zostaje powiązany za pomocą twardego powiązania z plikiem z wcześniejszego backupu. Dzięki temu ten sam plik jest zapisywany tylko raz na dysku twardym. Składnia rsync będzie następująca:
sudo rsync -avh --delete --exclude ‘Pobrane’ --exclude ‘Pulpit’ --exclude ‘Publiczny’ --link-dest=/media/dysk_na_kopie/full_backup /home/karol/ /media/dysk_na_kopie/przyrostowa1
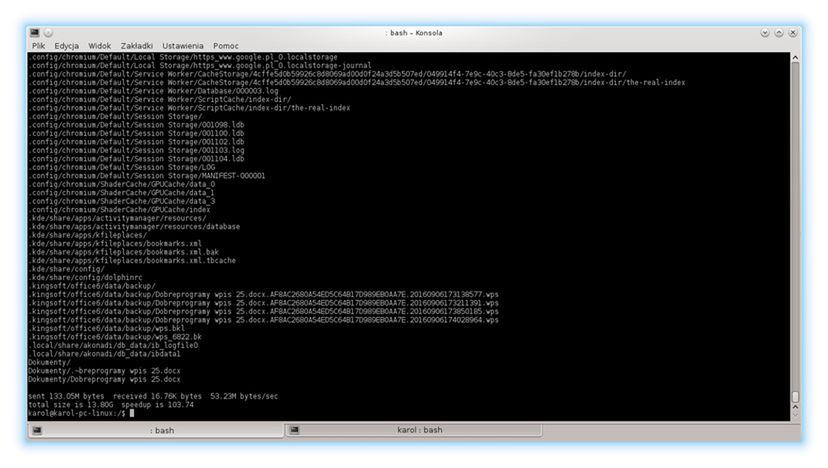
Widzimy, że zamiast blisko 14GB zostało przegrane jedynie trochę ponad 100MB. Można byłoby osiągnąć jeszcze lepszy wynik, gdyby z synchronizacji usunąć katalog pamięci cache Chromium. Zerknijmy teraz, jak działa mechanizm “twardych linków”. Przyjrzyj się zrzutowi ekranu, który przedstawia numery inode (węzłów) plików w pełnej kopii zapasowej oraz w przyrostowej
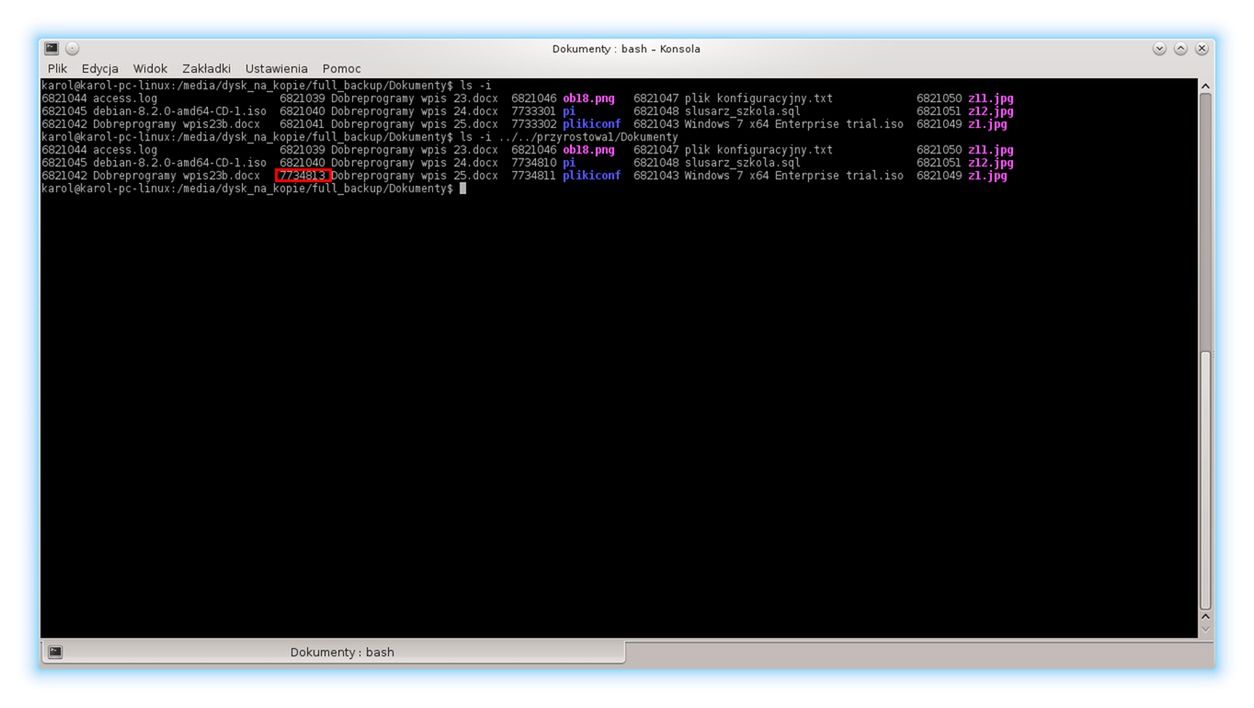
Zauważ, że wszystkie pliki (nie zwracaj uwagi na foldery) mają taki sam numer i‑węzła. Różni się on tylko przy pliku: “Dobreprogramy wpis 25.docx”, czyli tym, nad którym aktualnie pracuję (i który zarazem się zmienia). Jaki wniosek można wyciągnąć? Spośród przedstawionych na screenie plików zmienił się tylko jeden, gdyż tylko jeden zapisany jest w innym miejscu systemu plików. Pozostałe pliki w kopii przyrostowej to jedynie “nawiązania” do ich odpowiedników z pełnej kopii zapasowej.
Automatyzujemy wykonywanie kopii zapasowej za pomocą rsync
Jedna z zasad kopii zapasowych mówi o tym, że powinna ona być wykonywana co jakiś czas. Możemy ręcznie wydawać odpowiednie polecenia, ale nie jest to zbyt wygodne. W takim wypadku musimy przecież pamiętać, aby zrobić backup np.: zawsze po wylogowaniu. Nie jest to optymalne rozwiązanie. Właśnie w takim celu można wykorzystać potęgę tkwiącą w skryptach Bash. Za chwilę stworzymy prosty skrypt, który automatycznie raz na dzień wykonuje przyrostową kopię zapasową.
#!/bin/bash #Pobranie obecnego dnia (nazwa katalogu) DZIEN0=`date -I` #Pobranie wcześniejszego dnia (nazwa katalogu): DZIEN1=`date -I -d "1 day ago"` #Źródłowy katalog: ZRODLO="/home/karol/" #Docelowy katalog CEL="/media/dysk_na_kopie/$DZIEN0" KATALOG_LOGOW="/var/log/backup.log" #Link do katalogu docelowego (twardy link) LNK="/media/dysk_na_kopie/$DZIEN1" EXCLUDE="--exclude 'Pobrane' --exclude 'Pulpit' --exclude 'Publiczny'" #Opcje rsync: OPT="-avh --delete $EXCLUDE --link-dest=$LNK --log-file=$KATALOG_LOGOW" #Uruchamiamy backup rsync $OPT $ZRODLO $CEL #Ustalamy nazwę katalogu kopii starszej niż 14 dni DZIEN14=`date -I -d "14 days ago"` #Kasujemy backup starszy niż 14 dni if [ -d /media/dysk_na_kopie/$DZIEN14 ] then rm -rf /media/dysk_na_kopie/$DZIEN14 fi
Przeanalizujmy pokrótce, co się dzieje w powyższym skrypcie. Najpierw tworzymy kilka zmiennych, które będą naszymi nazwami katalogów. Kolejne zmienne definiują odpowiednio: co będziemy backupowali oraz gdzie. W katalogu logów zapisujemy wyniki działania polecenia - przydatne, jeśli będziemy chcieli znaleźć przyczynę ewentualnych błędów. Zmienna OPT przechowuje parametry, z którymi zostanie wywołane polecenie rsync. Po wykonaniu odpowiednich definicji możemy w końcu uruchomić backup.
Ostatnie 6 linijek odpowiada za kasowanie kopii zapasowych starszych niż 14 dni. Stanowi to zabezpieczenie przed zbytnim zużyciem miejsca na dysku przez bardzo stare wersje plików.
Pozostaje nam ostatnia rzecz - musimy poinformować system, kiedy nasz skrypt ma być uruchamiany. Dostępnych jest wiele opcji. My zapiszemy nasz skrypt w katalogu /etc/cron.daily. Dzięki temu kopia zapasowa będzie wykonywana raz dziennie.
Duplicity - backup z wieloma możliwościami
Rsync jest bardzo prostym programem. Niestety, za jego pomocą nie wykonamy kopii przyrostowych na zasobach udostępnionych przez protokół CIFS (dla niewtajemniczonych – pliki udostępnione przez Sambę lub Windowsa). Dodatkowo, omawiany wcześniej program nie wspiera ani automatycznej kompresji danych ani szyfrowania. Powstaje pytanie, co zrobić w przypadku, kiedy chcemy wykonać kopię zapasową poufnych danych na niepewny nośnik? Taki backup powinniśmy zawsze wykonywać w miejscu, do którego jedynie my mamy dostęp. Jednakże, nie zawsze istnieje taka możliwość. W takim wypadku musimy polegać na sile kryptografii. Możemy ręcznie szyfrować każdy plik, ale byłoby to niezwykle czasochłonne zajęcie. Programiści opracowali dla nas odpowiednie oprogramowanie. Jedną z darmowych opcji jest zastosowanie programiku działającego podobnie jak rsync, a noszącego nazwę Duplicity.
Instalacja oprogramowania jest bardzo prosta i możemy to zrobić za pomocą standardowego wywołania apt‑get.
Naszym pierwszym zadaniem będzie osiągnięcie efektu podobnego jaki uzyskaliśmy przy pomocy rsync. Będziemy synchronizowali nasz katalog domowy z folderem /media/katalog_na_kopie/kopia. Polecenie służące do tego celu będzie wyglądało następująco:
duplicity --no-encryption /home/karol file:///media/dysk_na_kopie/kopia
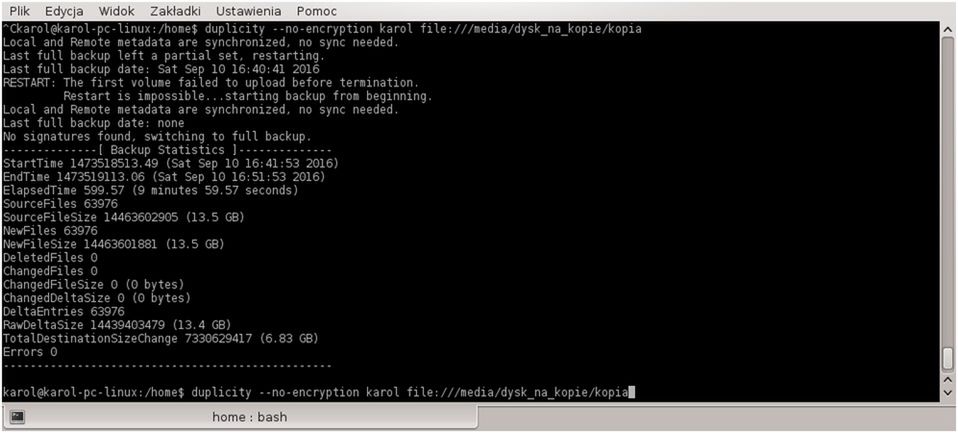
Wynik działania programu został przedstawiony na screenie. W przeciwieństwie do rsync, otrzymujemy o wiele więcej informacji na temat przeprowadzonych przez program działań. Wiemy m.in. ile plików zostało zmienionych od czasu wykonania ostatniej pełnej kopii zapasowej, ile zajmują dane przed i po kompresji, a także wiele innych rzeczy. Przykładowe polecenie także doskonale pokazuje podstawową składnię duplicity. Najpierw podajemy przełączniki, których zamierzamy użyć. Wyłączyliśmy szyfrowanie za pomocą opcji –no‑encryption. Dlaczego? Nie możemy w tej chwili użyć szyfrowania, gdyż jeszcze nie wygenerowaliśmy odpowiednich kluczy.
Duplicity współpracuje z wieloma protokołami. My, w przykładzie powyżej użyliśmy protokołu file://. Służy on po prostu do wykonania kopii zapasowej zapisanej w jakimś miejscu w naszym drzewie katalogów. Możemy skorzystać z innych protokołów, np.: ftp czy scp. Nie stanowi to żadnego problemu.
Analizujemy kopię zapasową duplicity i przywracamy dane
Rsync to w założeniach narzędzie do synchronizacji dwóch katalogów. Rolę programu do wykonywania kopii zapasowych nadaliśmy mu my, używając odpowiednich przełączników i sztuczek. W przeciwieństwie do rsync, duplicity jest aplikacją opracowaną od początku do końca z myślą o backupie. Dostarcza dzięki temu szereg przełączników, służących do analizy zawartości backupów, a także czasu ich wykonania. Teraz poznamy kilka podstawowych przełączników służących do tego celu.
Wykonujemy backupy. Bardzo przydatna byłaby wiedza, jakie kopie zapasowe, z jakich okresów posiadamy na swoim nośniku. Możemy poznać te informacje za pomocą następującego polecenia:
duplicity collection-status file:///media/dysk_na_kopie/kopia
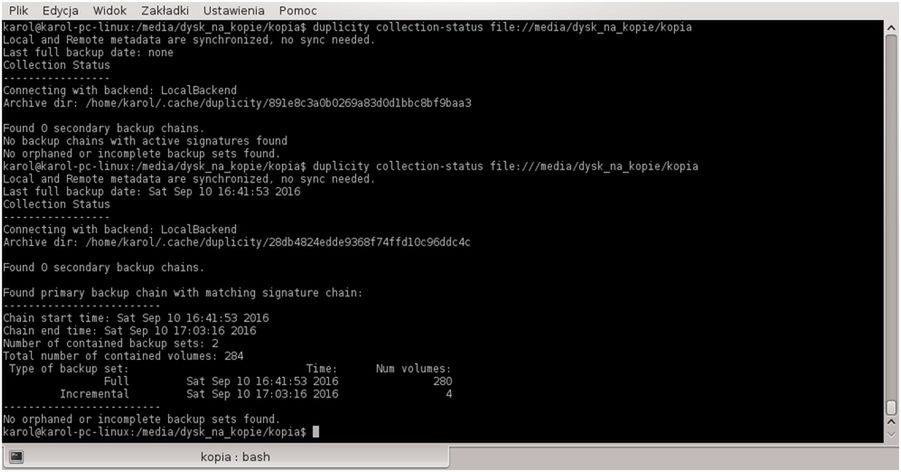
Wynik działania polecenia widzimy na screenie powyżej. Przełącznik collection-status dostarcza informacji na temat rodzaju oraz daty wykonania kopii zapasowych.
Czasami chcemy wyświetlić historię modyfkacji danego pliku na przestrzeni ostatnich kilku backupów. Listę wszystkich plików znajdujących się w kopiach zapasowych możemy wyświetlić za pomocą polecenia:
duplicity list-current-files file:///media/dysk_na_kopie/kopia
Istnieje jeden problem. Chodzi nam przecież o konkretny plik, a nie o wszystkie! Musimy przefiltrować to, co wyrzuca duplicity za pomocą polecenia grep. Przypuśmy, że chcemy poznać historię modyfikacji pliku zawierającego słowa “Bazy danych.docx”. Powinniśmy użyć polecenia:
duplicity list-current-files file:///media/dysk_na_kopie/kopia | grep ‘Bazy danych.docx’
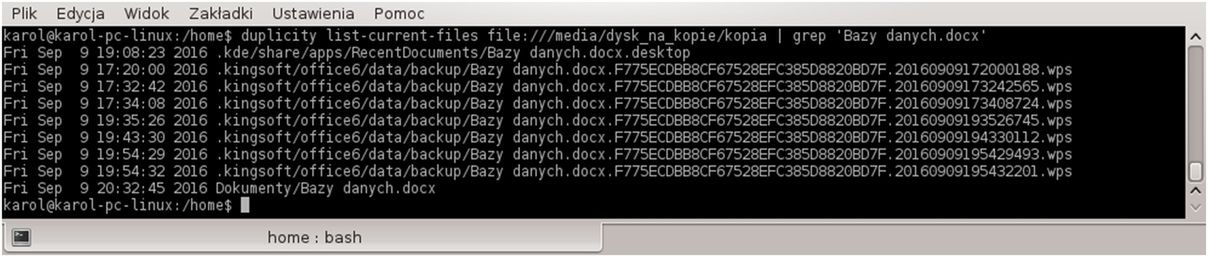
Wynik polecenia jasno wskazuje że plik ten występuje tylko raz w naszej kopii zapasowej. Znamy także datę jego ostatniej modyfikacji.
Zostaje nam ostatni problem do rozważenia - jak przywrócić pliki z kopii zapasowej wykonanej za pomocą duplicity? Zacznijmy od przywrócenia zawartości całego folderu. Służy do tego następujący ciąg znaków:
duplicity --no-encryption --file-to-restore Dokumenty file:///media/dysk_na_kopie/kopia /home/karol/Dokumenty/kopia
Jaka jest składnia? Poznaliśmy nowy parametr -‑file-to-restore. Informuje on duplicity o tym, że chcemy przywrócić dane. -‑no-encryption zastosowaliśmy dlatego, że nasza kopia zapasowa nie była szyfrowana. Następnie podajemy nazwę folderu, który chcemy przywrócić. Potem jedynie zapisujemy źródło oraz cel. Voila! Plan został wykonany. Podobnie postępujemy, jeśli chcemy przywrócić pojedynczy plik.
Powstaje pytanie - co zrobić, jeśli chcemy przywrócić nie najnowszą wersję pliku, ale np.: taką sprzed 10 dni? Polecenie będzie takie samo jak te powyżej. Musimy dodać jedynie przełącznik -t, po której podajemy wiek pliku. Przykładowo, chcemy przywrócić plik bazy_danych.docx sprzed 10 dni. Polecenie będzie wyglądało następująco:
duplicity --no-encryption --file-to-restore -t 10D Dokumenty/bazy_danych.docx file:///media/dysk_na_kopie/kopia /home/karol/Dokumenty/bazy_danych.docx
Szyfrujemy kopię zapasową
Duplicity jest narzędziem nie tylko o wiele wygodniejszym od rsynca, ale dającym “out-of-the-box” wiele więcej możliwości. Jedną z najważniejszych jest możliwość szyfrowania naszych kopii zapasowych, jeśli zapisujemy je na niezaufanym medium. Konfiguracja jest, podobnie jak w poprzednich wypadkach, niezwykle prosta.
Omawiany program może korzystać z szyfrowania za pomocą gpg. GPG (GNU Privacy Guard), funkcjonuje podobnie jak TLS używany w przeglądarkach. Do szyfrowania niezbędna jest para kluczy publiczny-prywatny. Klucz prywatny należy chronić przed osobami trzecimi, gdyż pozwala odczytać zaszyfrowane za pomocą klucza publicznego dane. Aby użyć GPG, najpierw musimy wygenerować klucze. Robimy to za pomocą polecenia:
gpg --gen-key
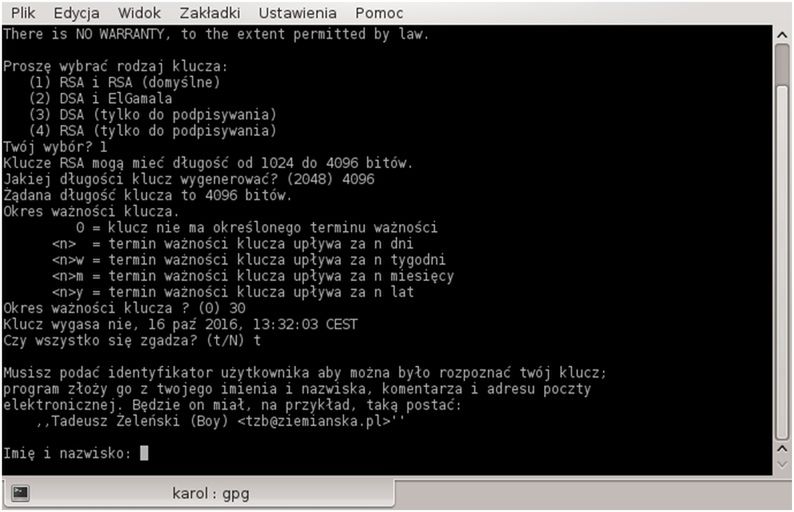
Najpierw wybieramy rodzaj klucza, który będzie używany do właściwego szyfrowania. Domyślną opcją jest algorytm RSA. Szyfrowanie Elgamala jest pewniejsze, ale pochłania większą ilość mocy obliczeniowej. Załóżmy, że wybraliśmy domyślną opcję: RSA i RSA.
Kolejnym krokiem będzie wybranie długości klucza. Logiczne jest, że klucz jest tym bezpieczniejszy, im dłuższy. Toteż najlepiej wybrać największą wartość - 4096 bitów.
Następnie wybieramy okres ważności klucza. Ten fakt zależy w całości od nas. Jeśli nie będzie istniało zbyt duże ryzyko wycieku, możemy ustawić dłuższy czas ważności. W przeciwnym wypadku lepiej częściej wymieniać klucze szyfrujące, choć z pewnością jest to bardziej kłopotliwe.
Pozostaje przed nami jeden z ostatnich kroków. Musimy wypełnić dane osobowe. Zapisane one będą w pliku klucza publicznego, jednoznacznie deklarując jego właściciela.
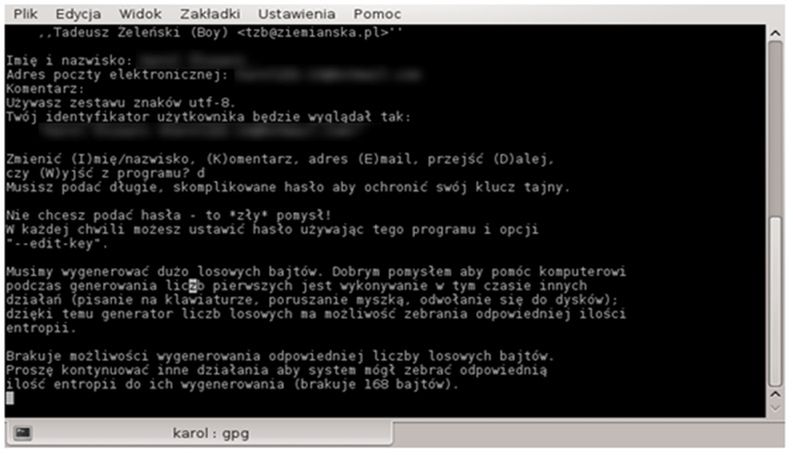
Po wypełnieniu kilku pól możemy, ale nie musimy wpisać klucz, którymi będziemy chronić nasz klucz prywatny. Jest to kolejna opcja, której możemy użyć dla zwiększenia bezpieczeństwa naszych danych.
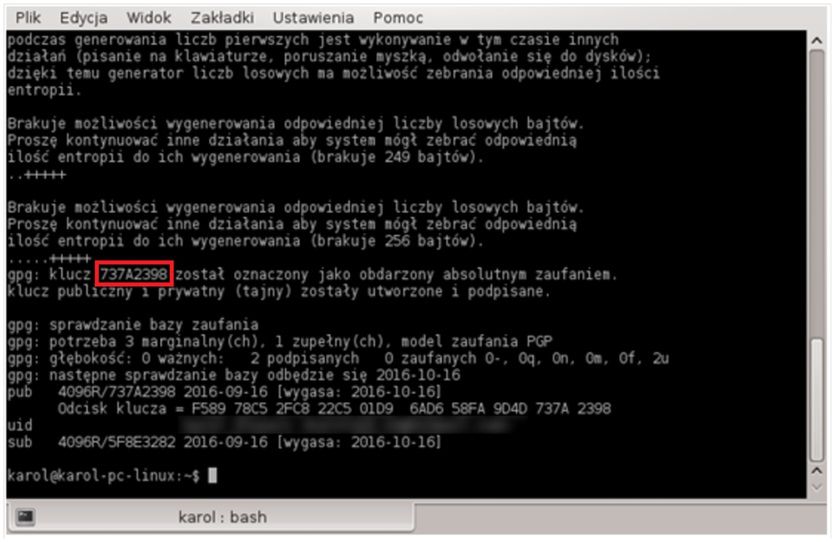
Najgorszym i najbardziej denerwującym etapem generowania klucza jest entropia. Co to jest? W skrócie, generator liczb losowych, podobnie jak wszystko w informatyce, musi polegać na jakimś algorytmie. GPG jako “ziarno” do generatora liczb losowych wprowadza różne dane, związane np.: z tym, co aktualnie robimy przy komputerze, jakie znaki na klawiaturze wpisujemy itp. Czym większa entropia, tym większe bezpieczeństwo klucza. GPG nie wygeneruje nam klucza dopóty, dopóki nie będzie miał odpowiedniego zasobu “losowych” informacji. Ten etap jest stosunkowo najdłuższy.
Po wygenerowaniu klucza zostanie wyświetlone podsumowanie związane z wykonywaną operacją. Są to bardzo podstawowe dane, związane np.: z datą wygaśnięcia klucza czy danymi właściciela. Najważniejszym parametrem, który później znajdzie zastosowanie w duplicity, jest identyfikator klucza, zaznaczony na screenie powyżej. Będziemy musieli go podać jako parametr w ciągu argumentów duplicity. Dzięki temu nasz backupowy program będzie wiedział, jakiego klucza ma użyć. Przykładowa linia poleceń może wyglądać tak:
duplicity --encrypt-key 737A2398 /home/karol file:///media/dysk_na_kopie/kopia
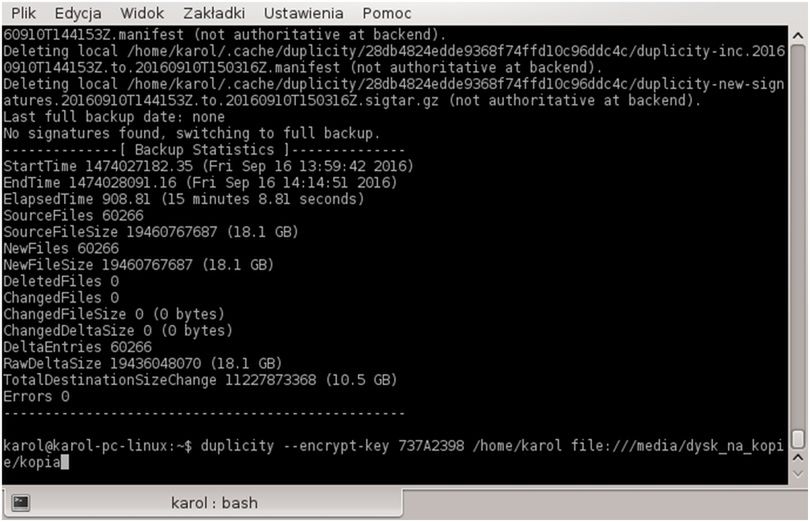
Jeśli chcemy przywrócić plik, używamy takich samych poleceń jak w poprzednim rozdziale. Jedyną różnicą jest zastąpienie parametru -‑no-encryption opcją -‑encrypt key xxx.
DODATEK A: Montujemy zasób sieciowy używający protokołu SMB na stałe
Za pomocą duplicity możemy bardzo prosto wykonywać kopię zapasową na nasz dysk sieciowy. Niestety, aby to zrobić, musimy najpierw uruchomić automatyczne montowanie zasobu w odpowiednim katalogu.
Zadanie to jest niezwykle proste. Nie znaczy to, że nie będziemy musieli doinstalować dodatkowego oprogramowania i pobawić się w konsoli. Pakietem, który powinniśmy zainstalować jest cifs-utils. Następujące polecenie wykona to zadanie:
sudo apt-get install cifs-utils
Przejdźmy teraz do katalogu media, znajdującego się w głównym drzewie katalogów. Utwórzmy tam folder: katalog_na_kopie.
Teraz czeka nas najcięższy etap zadania. Musimy dodać odpowiedni wpis do /etc/fstab. W tym pliku są zapisane wszystkie zasoby/dyski, które należy zamontować podczas startu systemu. W naszym wypadku musimy dopisać linijkę odpowiedzialną za automatyczne montowanie udostępnionego przez dysk sieciowy zasobu. W moim wypadku wyglądałaby następująco:
//192.168.1.6/karol /media/katalog_na_kopie cifs username=karol,password=supertajnehaslo,iocharset=utf8,sec=ntlm 0 0
Zamiast //192.168.1.6/karol Podstawiamy nasze dane - odpowiednio - adres IP/nazwę serwera oraz nazwę udostępnionego zasobu. Parametrów username i password możesz zastąpić słówkiem guest w wypadku, gdy udostępniony folder nie jest chroniony hasłem.
Fstab jest plikiem, który każdy z użytkowników może podejrzeć. Przechowywanie w nim hasła do zasobu sieciowego nie jest zbyt dobrym pomysłem. Przenieśmy więc je do oddzielnego, ukrytego pliku o nazwie smbcredentials, znajdującego się w naszym katalogu domowym. Wydajemy polecenia:
touch ~/.smbcredentials nano ~/.smbcredentials
Treść powinna wyglądać następująco:
username=karol password=supertajnehaslo
Oczywiście za słowa karol i supertajnehaslo powstawiasz własne parametry - odpowiednio login oraz hasło do zasobu.
Teraz musimy jedynie zakazać wszystkim użytkownikom (oprócz nas) dostępu do tego pliku, a nawet jego oglądania. Robimy to za pomocą szeroko znanego polecenia chmod:
chmod 600 ~/.smbcredentials
Większość operacji została wykonana. Teraz musimy jedynie przeprowadzić edycję pliku /etc/fstab. Zamiast parametrów username i password należy użyć opcji credentials, która jako argument przyjmuje ścieżkę do naszego pliku z parametrami logowania. W praktyce wyglądać to będzie następująco:
//192.168.1.6/karol /media/katalog_na_kopie cifs credentials=/home/karol/.smbcredentials,iocharset=utf8,sec=ntlm 0 0
Słowem podsumowania
Oprócz dwóch wyżej opisanych, na Linuksa dostępnych jest wiele więcej innych narzędzi. Niestety, nie wyróżniają się one żadnymi funkcjami, których nie udostępniałby rsync lub duplicity. Niefortunnie, w tej części zabrakło miejsca dla Windowsa. Także, jeśli chcesz poczytać trochę o wykonywaniu kopii zapasowych na systemie operacyjnym z Redmond, zarówno za pomocą wbudowanych jak i dodatkowych narzędzi, zapraszam na kolejną (i prawdopodobnie ostatnią) część dotyczącą kopii zapasowych.

![Mobilny czytnik, który mógłby zostać smartfonem. Onyx Boox Palma [Recenzja]](https://v.wpimg.pl/MDliLmpwYiUNCzpeXwxvME5TbgQZVWFmGUt2T19CdHMUWn1bXwMoJwRHOx0TEyNqHAVjBB0QYnUKXXwOSUQvaVQLLlldQygmD0QtWkEWYHdYXXVZQEF_J1xQLkMaBypmEQ)
![Bezprzewodowa klawiatura dla minimalistów. Logitech Pop Icon Keys [Recenzja]](https://v.wpimg.pl/ZmRlLmpwdQwzDjpeXwx4GXBWbgQZVXZPJ052T19CY1oqX31bXwM_DjpCOx0TEzRDIgBjBB0QdV1mDSlaQEY_QDEPeAxdQz8OakF1VBFFd1plDnsMRxZqXjQIKUMaBz1PLw)
![Szybki i kompaktowy dysk SSD na USB-C. ADATA SC750 (2 TB) [Recenzja]](https://v.wpimg.pl/OWU5LmpwYDY0VzpeXwxtI3cPbgQZVWN1IBd2T19CdmAtBn1bXwMqND0bOx0TEyF5JVljBB0QYGJgBXhdEUYsemJXdVldQ31gNxguWENAYmIzUHQJQE4rNGxQdUMaByh1KA)


![Tania optyka do wideokonferencji. Kamerka Logitech Brio 100 [Recenzja]](https://v.wpimg.pl/NmE2LmpwYQwkUDpeXwxsGWcIbgQZVWJPMBB2T19Cd1o9AX1bXwMrDi0cOx0TEyBDNV5jBB0QYVUgVn9ZERR_QH0Kf15dQ3cJIR8uXRRAY11yBC5fQhR8W3NTekMaBylPOA)
![Minimalistyczna klawiatura bezprzewodowa. Logitech Pebble Keys 2 [Recenzja]](https://v.wpimg.pl/Y2Q1LmpwdlMwUzpeXwx7RnMLbgQZVXUQJBN2T19CYAUpAn1bXwM8UTkfOx0TEzccIV1jBB0QdlRpBXtdRU46H2FQLlhdQzxTYxwuVUJBdABiUi9UQxY7VjJVeUMaBz4QLA)