

Regex i duży plik - jak ugryźć to w javie?
Wstęp
Dla jasności - mówimy o pliku rozmiaru co najmniej 1 GB. Załóżymy, że mamy sobie taki plik, wyglądający o tak:abbbbbbbbbbbb....bbbbbbbbc
"b" powtarzamy, aż plik osiągnie 1 GB. Chcielibyśmy znaleźć liczbę wystąpień wzorca "ab*c". Oczywista oczywistość - wczytanie całego pliku do pamięci raczej nie jest dobrym pomysłem. Żarówką, który najszybciej mi zapaliła się (i najszybciej zgasła) była próba własnoręcznego zaimplementowania parsera wyrażeń regularnych. Oczywiście - to porywanie się z motyką na słońce (jak na mojego skill-a), dlatego zrezygnowałem. Postanowiłem ugryźć to z innej strony.

Zadanie to miałem zdefiniowane na studiach. Jak się okazało, treść troszkę była inna: nie trzeba było obsługiwać regexów, a tylko wyszukiwanie wystąpienia zadanego tekstu (którego długość była ograniczona liczbą stałą) - co jest oczywiście dużo łatwiejsze. Ale że już wziąłem się za wyrażenia regularne...
Nowa nadzieja
Do głowy przyszedł mi nowy pomysł (przy wsparciu kolegów ze stackoverflow-a :‑) ): w klasie [code=java]Pattern[/code] występuje wdzięczna metoda o nazwie [code=java]matcher[/code] Jako argument, przyjmuje ona implementację interfejsu [code=java]CharSequence[/code]
Hmm.. a jakby tak zaimplementować ten interfejs? Głównym problemem jaki się nasuwa to dostęp do dowolnego znaku w pliku. Zwłaszcza, ze może być różne kodowanie. Chwilka.. a co, jeśli byśmy nie wczytywali pojedynczych znaków, tylko pewien bufor określonego rozmiaru, który przechowuje też znaki w otoczeniu pożądanej przez matcher litery? To ma sens! Przecież jest wielce prawdopodobne, że regex może chcieć informacje o sąsiadujących znakach (niestety, moze się też zdarzyć, że będziemy skakać po całym pliku, tego nie unikniemy).
Implementacja
Pomysł wygląda następująco: Podzielimy plik na stało-wymiarowe "okna". Implementujemy interfejs CharSequence. Gdy zostanie wywołana metoda charAt, obliczmy w którym "oknie" znak się znajduje a następnie ladujemy okienko do pamięci. Oczywiście, najpierw sprawdzamy, czy dana ramka nie jest już załadowana.
Nasze okno w pliku będzie reprezentować klasa:
public class CharFrame{ private final long frameSize; private final long fileOffset; private final long charSize; private final long charOffset; public CharFrame(long frameSize, long fileOffset, long charSize, long charOffset) { this.frameSize = frameSize; this.fileOffset = fileOffset; this.charSize = charSize; this.charOffset = charOffset; } public long getFrameSize(){ return this.frameSize; } public long getFileOffset(){ return this.fileOffset; } public long getCharOffset(){ return this.charOffset; } public long getCharSize(){ return this.charSize; } }
W tej prostej klasie przechowywać będzie informacje o pojedynczej ramce: jej położenia (offset) w pliku (względem bajtów) oraz wielkość w bajtach. Analogiczne dane - ale względem znaków - też będziemy przechowywać.
Przygotujmy teraz pomocniczy interfejs:
public interface Mappable extends Closeable { ByteBuffer map(FileChannel.MapMode mapMode, long offset, long size) throws MappingBufferException; long size() throws CalculatingSizeException; }
Interfejs umożliwia załadowanie "kawałka" pliku do pamięci (kawałek jest reprezentowany przez offset względem początku i wielkość). Metoda zwróci bajty, które reprezentują dany kawałek pliku. Zaimplementujmy ten interfejs:
public class MappableFileChannel implements Mappable { private final FileChannel fileChannel; public MappableFileChannel(RandomAccessFile randomAccessFile){ this.fileChannel = randomAccessFile.getChannel(); } @Override public ByteBuffer map(FileChannel.MapMode mapMode, long offset, long size) throws MappingBufferException { try { return this.fileChannel.map(mapMode, offset, size); } catch (IOException e) { throw new MappingBufferException(e); } } @Override public long size() throws CalculatingSizeException { try { return this.fileChannel.size(); } catch (IOException e) { throw new CalculatingSizeException(e); } } @Override public void close() throws IOException { this.fileChannel.close(); } }
Dodatkowe klasy wyjątków nie będę opisywał - wystarczy, że dziedziczą po Exception.
Możemy praktycznie przejść od meritum. Dodajmy sobie interfejs:
public interface TextProvider extends CharSequence, Closeable { }
Rozpoczynamy implementację, przekazując przygotowywując potrzebne zmienne globalne:
public class LargeFileTextProvider implements TextProvider { // szerokość ramki private final int BUFF_SIZE; // mapowanie pliku na pamięc private final Mappable mappable; // kodowanie pliku tekstowego private final Charset charset; // długość pliku w bajtach private final long totalFileSize; // długość pliku w znakach w zadanym kodowaniu private final long totalCharSize; // lista możliwych wszystkich "okienek" w pliku poukładane w kolejności rosnącej // np. ramka opisująca bajty w przedziale // 0-BUFF_SIZE - 1, BUFF_SIZE - 2*BUFF_SIZE - 1 itd. private List<CharFrame> charFrames; // ostatnio wczytana ramka (metadane) private CharFrame lastReadFrame; // znaki ostatnio wczytanego "okienka" private CharBuffer lastBuffer; }
Przydatne będą na pewno te dwie metody:
private CharsetDecoder newDecoder(){ return charset.newDecoder() .onMalformedInput(CodingErrorAction.REPORT) .onUnmappableCharacter(CodingErrorAction.REPORT); } private CharBuffer newCharBuffer(){ return CharBuffer.allocate(BUFF_SIZE); }
CharsetDecoder (klasa domyślnie dostępna w javie) umożliwać będzie nam konwertowanie bajtów na znaki w zadanym kodowaniu. Druga będzie tworzyć instancję bufora dla bajtów (tak naprawdę tablicę znaków).
Kolejna metoda będzie tak naprawdę wrapperem do naszego mappable - zwróci nam bufor bajtów pewnego "kawałka" pliku:
private ByteBuffer loadFilePieceIntoMemory(long fileOffset, long size) throws MappingBufferException { return this.mappable.map(FileChannel.MapMode.READ_ONLY, fileOffset, size); }
W tej chwili jesteśmy w stanie zbudować pojedynczą ramkę (instancję CharFrame) która będzie przechowywała nasze metadane:
private CharFrame readCharFrame(long fileOffset, long charOffset, CharsetDecoder decoder, CharBuffer buffer) throws MappingBufferException, CharacterCodingException { long remainingFileSize = min(BUFF_SIZE, this.totalFileSize - fileOffset); final ByteBuffer mappedBuffer = this.loadFilePieceIntoMemory(fileOffset, remainingFileSize); buffer.rewind(); decoder.reset(); // próbujemy odczytać znaki final CoderResult decodingResult = decoder.decode(mappedBuffer, buffer, true); if (decodingResult.isError()){ decodingResult.throwException(); } if (decodingResult.isMalformed()){ // prawdopodobnie ramka "ucięła" znak. Może to wystąpić, jeśli takowy // jest zapisany w postaci dwóch bajtów. Nasza ramka zawierać pierwszy bajt // ale niekonieczne ten drugi. W takim przypadku, bierzemy tyle bajtów, ile udało // się nam odczytać (ramka nie ma rozmiar bufora, tylko już mniejszy) remainingFileSize = (long) mappedBuffer.position(); } // parametry: rozmiar ramki, pozycja w pliku (w bajtach), // ilość odczytanych znaków, pozycja w pliku względem znaków return new CharFrame(remainingFileSize, fileOffset , buffer.position(), charOffset ); }
Nie zostało nam nic innego, jak przygotować ramki dla całego pliku:
private void prepareFrames() throws MappingBufferException, CharacterCodingException { final CharsetDecoder decoder = this.newDecoder(); final CharBuffer buffer = this.newCharBuffer(); long fileOffset = 0, charOffset = 0; while (fileOffset < this.totalFileSize){ CharFrame charFrame = this.readCharFrame(fileOffset, charOffset, decoder, buffer); charOffset += charFrame.getCharSize(); fileOffset += charFrame.getFrameSize(); this.charFrames.add(charFrame); } }
Teraz możemy zbudować już konstruktor:
public LargeFileTextProvider(Mappable mappable, Charset charset, int bufferSize) throws CalculatingSizeException, MappingBufferException, CharacterCodingException { if (bufferSize < 1024){ throw new IllegalArgumentException("Buffer size cannot be lower than 1024 bytes."); } if (mappable == null){ throw new IllegalArgumentException("Mappable cannot be null."); } this.mappable = mappable; this.charset = charset; this.BUFF_SIZE = bufferSize; this.charFrames = new ArrayList<CharFrame>(); this.totalFileSize = this.mappable.size(); this.prepareFrames(); CharFrame lastFrame = this.charFrames.get(this.charFrames.size() - 1); this.totalCharSize = lastFrame.getCharOffset() + lastFrame.getCharSize(); }
W nim ustawiane są zmienne prywatne i obliczane ramki dla całego pliku.
Możemy zabrać się za implementację interfejsu CharSequence. Pierwsza potrzebna metoda będzie stwierdzała, czy dla zadanego znaku na pozycji i musimy załadować "okno" z pliku, czy też mozemy użyć ostatnio załadowany:
private boolean needFrameChange(int i){ if (this.lastReadFrame == null){ return true; } return i < this.lastReadFrame.getCharOffset() || this.lastReadFrame.getCharOffset() + this.lastReadFrame.getCharSize() < i + 1; }
Teraz metoda, która załaduja dla znaku dla zadanej pozycji odpowiednią ramkę (tzn. jej zawartość w bajtach):
private void loadFrameForChar(int i) throws MappingBufferException { int frameIndex = 0; CharFrame charFrame = this.charFrames.get(frameIndex); // TODO binary search while (charFrame.getCharOffset() + charFrame.getCharSize() < i + 1){ frameIndex += 1; charFrame = this.charFrames.get(frameIndex); } // znaleźlimy pożądaną ramkę this.lastReadFrame = charFrame; final CharsetDecoder decoder = this.newDecoder(); final CharBuffer buffer = this.newCharBuffer(); // bierzemy jej wielkość w bajtach long remaining = min(this.totalFileSize - this.lastReadFrame.fileOffset, BUFF_SIZE); // ładujemy bajty z pliku do pamięci ByteBuffer byteBuffer = this.loadFilePieceIntoMemory(this.lastReadFrame.getFileOffset(), remaining); // odczytujemy znaki decoder.decode(byteBuffer, buffer, true); // zawartość (znaki) załadowanej ramki this.lastBuffer = buffer; }
Mając te dwie metody, możemy zaimplementować charAt:
@Override public char charAt(int i) { if (i < 0){ throw new ArrayIndexOutOfBoundsException(); } if (i > this.length() - 1){ throw new ArrayIndexOutOfBoundsException(); } if (this.needFrameChange(i)){ try { this.loadFrameForChar(i); } catch (MappingBufferException e) { throw new RuntimeException(e); } } assert(i >= this.lastReadFrame.charOffset); try{ return this.lastBuffer.get((int) (i - this.lastReadFrame.charOffset)); } catch(IndexOutOfBoundsException e){ e.printStackTrace(); throw new IndexOutOfBoundsException(); } }
Zaimplementowanie subSequence to już czysta formalność. Zrobiłem to najprostszą drogą (matcher nie korzysta z subSequence, więc nie troszczyłem się bardzo o wydajność):
@Override public CharSequence subSequence(int i, int i2) { if (i > i2){ throw new IllegalArgumentException(); } if (i < 0){ throw new ArrayIndexOutOfBoundsException("Start index is too low."); } if (i >= this.totalCharSize){ throw new ArrayIndexOutOfBoundsException("Start index is too high."); } if (i2 > this.totalCharSize){ throw new ArrayIndexOutOfBoundsException("End index is too high."); } StringBuffer buffer = new StringBuffer(); while (i < i2){ buffer.append(this.charAt(i)); } return buffer; }
I to.. by było na tyle! Zostało kilka drobnych metod (jak np. close) których nie będe pokazywał - są one trywialne, a wpis i tak się już rozrósł :)
Przykładowe użycie:
TextProvider textProvider = new LargeFileTextProvider(new MappableFileChannel(new RandomAccessFile("plik.txt", "r")), Charset.forName("UTF-8")); Pattern regex = Pattern.compile("ab*c"); Matcher matcher = regex.matcher(textProvider);
Przygotowałem również GUI, który wygląda mniej więcej tak:
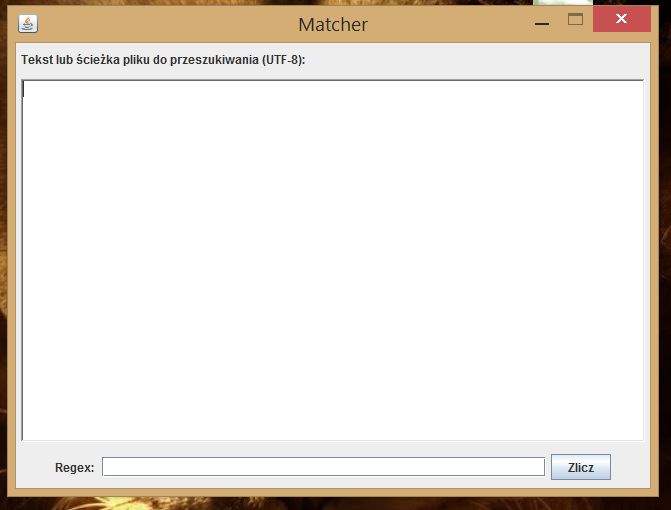
Przykładowe testy, które program przechodzi:
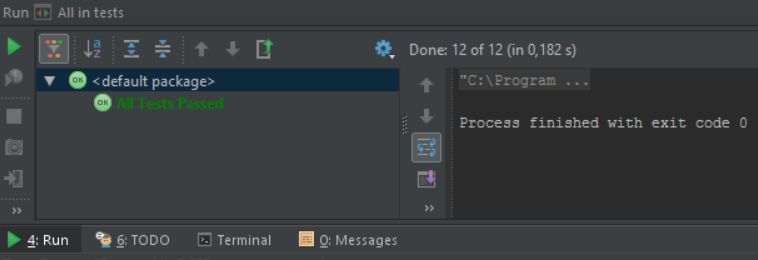
Przykładowy test:
@Test public void returningChar_WithShortData_ReturnsProperResult() throws MappingBufferException, CalculatingSizeException, CharacterCodingException { // arrange String text = "sample"; Charset charset = Charset.forName("UTF-8"); byte[] bytes = this.getTextAsBytes(text, charset); Mappable mappable = mock(Mappable.class); doReturn(MappedByteBuffer.wrap(bytes)) .doReturn(MappedByteBuffer.wrap(bytes)) .when(mappable) .map(any(FileChannel.MapMode.class), anyLong(), anyLong()); doReturn((long)bytes.length -1).when(mappable).size(); TextProvider textProvider = new LargeFileTextProvider(mappable, charset); //act char result = textProvider.charAt(2); // assert assertEquals('m', result); }
Za pewne są miejsca do optymalizacji, być może są ciekawsze sposoby rozwiązania tego problemu, ale nie o to tu chodziło - program miał spełnić swoje zadanie, zaimplementowanie przeze mnie, a myślę że to rozwiązanie spełnia te kryteria :)
Podsumowanie
Wspomniany przykład z początku: program wyszukał mi wzorzec w czasie ~ 4 sekund.

![Topowa wydajność w bezprzewodowej myszce. Genesis Zircon XIII [Recenzja]](https://v.wpimg.pl/YzMyLmpwdhssGzpeXwx7Dm9DbgQZVXVYOFt2T19CYE01Sn1bXwM8GSVXOx0TEzdUPRVjBB0Qdkt9TilYEURoV3wYKV5dQz0edVQtXEVEdE4oT35fFRU8Hi5KfkMaBz5YMA)
![Mobilny czytnik, który mógłby zostać smartfonem. Onyx Boox Palma [Recenzja]](https://v.wpimg.pl/MDliLmpwYiUNCzpeXwxvME5TbgQZVWFmGUt2T19CdHMUWn1bXwMoJwRHOx0TEyNqHAVjBB0QYnUKXXwOSUQvaVQLLlldQygmD0QtWkEWYHdYXXVZQEF_J1xQLkMaBypmEQ)
![Pojemny i wydajny. Silver Monkey Powerbank 20.000 mAh 100 W [Recenzja]](https://v.wpimg.pl/MzdkLmpwYhsFCTpeXwxvDkZRbgQZVWFYEUl2T19CdE0cWH1bXwMoGQxFOx0TEyNUFAdjBB0QYhlRWHhaR0QpVwdadVRdQ39DVkZ1WUJHYEoGWipYQUcoTldcKEMaBypYGQ)
![Duży, ciężki i pojemny. Powerbank Baseus Ambilight 30000 mAh [Szybki test]](https://v.wpimg.pl/ZmRjLmpwdQwzCDpeXwx4GXBQbgQZVXZPJ0h2T19CY1oqWX1bXwM_DjpEOx0TEzRDIgZjBB0QdV9nXXgMSUZtQGtTewtdQz8PN0ctWUEUdwlqWntUSUJoVDQOL0MaBz1PLw)


