

W świecie komputerowego tekstu
Zastanawialiście się kiedyś jak komputery "widzą" tekst? Albo dlaczego różne urządzenia elektroniczne pod kontrolą różnych systemów operacyjnych widzą i rozumieją ten sam tekst?
To zasługa w niemałej części American National Standards Institute, w skrócie ANSI. Ta znana niegdyś jako American Standards Association organizacja utworzyła komitet o fascynującej ;] nazwie X3, którego zadaniem było zestandaryzowanie sposobu wymiany tekstu między różnymi urządzeniami. Standard ten znany jako ASCII (American Standard Code for Information Interchange) wyparł stosowany wcześniej kod Baudota-Murraya i do dziś stanowi podstawę wymiany informacji między urządzeniami elektronicznymi. Zupełnie przypadkiem Intel jest członkiem ANSI. ;)
Ale jak działa ASCII? - ktoś zapyta. Już wyjaśniam. Historycznie większość komputerów (nie wszystkie!) operowała na bajtach o wielkości 8 bitów. Zaistniała potrzeba stworzenia jednolitego sposobu reprezentowania tekstu w postaci bajtów. Jako że w czasie powstawania standardu dalekopisy były wciąż kawałkiem szalenie zaawansowanej techniki, ASCII musiało odpowiadać także na ich zapotrzebowania, takie jak np. przewijanie papieru i powrót do początku wiersza (tzw. powrót karetki). No i te nieszczęsne urządzenia, które miały tylko 7 bitów na bajt...

ASCII stworzyło zatem tablicę kodów dla wartości od 0 do 127 (7 bitów), które to reprezentowały zarówno komendy sterujące (przewiń papier, uderz w dzwoneczek przywołujący operatora urządzenia - nie żartuję! - i temu podobne) jak i znaki niezbędne w tekście: litery, cyfry, znaki przestankowe i szereg mniej istotnych. Wartości 128‑255, z których mogły skorzystać 8‑bitowe urządzenia, miały kilka wariantów, dla większości pewnie znanych pod postacią stron kodowych w DOS. Tabela kodów jest łatwo osiągalna z poziomu wyszukiwarki Google, ale dla wygody umieściłem ją także poniżej.
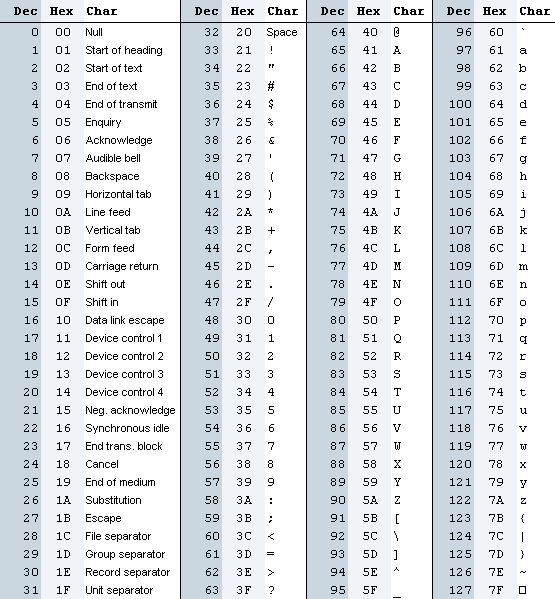
Sposób, w jaki rozdystrybuowano kody ASCII niesie ze sobą kilka interesujących właściwości. Po pierwsze, jak już wspomniałem, wszystkie "naturalne" kody (w tym litery i cyfry) znajdują się w przedziale 0‑127, a więc mają zero na najstarszym bicie klasycznego, 8‑bitowego bajtu. Co więcej wszystkie litery mają jedynkę na drugim najstarszym bicie.
Widzicie już dokąd zmierza ten wpis? :)
Każda kratka grafiki to bit. Biały - zero, czarny - jeden. W każdym rzędzie mamy zatem 16 bitów, czyli dwa bajty (dwa znaki informacji).

Konkursowe pytanie to grafika 16x6 punktów. Daje nam to w sumie 12 liter. Gdyby spojrzeć na trzeci MSB (most significant bit) od lewej, da się także zauważyć, że pierwszych 8 znaków to litery małe (jedynka na 3. bicie) a kolejne cztery to litery duże (zero w tym samym miejscu). Jaki to zatem tekst? Część z Was na pewno już wie: "pierwszySIMD". :)
Trzeba sobie zatem odpowiedzieć na pytanie: jaki był pierwszy powszechnie oferowany przez Intel SIMD? I co w ogóle znaczy SIMD?
SIMD to skrót od single instruction, multiple data. Idea jest następująca: by przyspieszyć działanie urządzenia, wykonujmy identyczne operacje na wielu danych jednocześnie, a nie jedna po drugiej. Pierwotnie komputery wykonywały operacje szeregowo: weź dwie wartości, zsumuj, zapisz wynik; weź dwie kolejne, zsumuj,...
Jest wiele zadań, które wymagają takich samych, powtarzalnych operacji na pokaźnych objętościowo danych. Układy wspierające SIMD pozwalają na pobranie nie dwóch, a większej liczby wartości (4, 8, 16,...), wykonanie na parach tej samej operacji oraz zapisanie wyników. Wszystko to jednocześnie! Jeśli zatem nasza aplikacja (np. program do kompresji video) operuje w jednolity sposób na bardzo dużej ilości danych, wykorzystując SIMD możemy uzyskać poważne przyspieszenie w ich przetwarzaniu.
Pierwsze oferowane w procesorach x86 rozszerzenie SIMD to oczywiście rok 1996 i technologia MMX (ponoć pierwotnie nie był to żaden skrót, choć powszechnie mówi się o rozwinięciu MultiMedia eXtension). Podkreślenie w podpowiedzi, że chodzi o technologię Intela jest o tyle istotne, że rok wcześniej zadebiutowało rozszerzenie VIS w procesorach SPARC a dwa lata wcześniej MAX w procesorach PA‑RISC od HP. Przeczy to wprost idei architektur RISC (do których należy także SPARC), ale ciężko wymagać od inżynierów konsekwencji. ;>
Czasy świetności RISCów już mocno przeminęły a architekturę PA‑RISC wyparło Itanium znane także jako IA‑64 od - nomen omen - Intela. Która to architektura, jeśli wolno mi wyrazić opinię, jest potwornie uciążliwa w debugowaniu. ;) Dziś procesory RISC pozostają architekturą wyspecjalizowaną, niszową (zrezygnowało z nich nawet Apple), natomiast x86 z MMX i jego zmiennoprzecinkowymi następcami z rodziny SSE święcą triumf. I to technologii MMX właśnie poświęcone było pierwsze zadanie specjalne. :]
Gratulacje dla wszystkich, którzy sobie z zadaniem poradzili. Mam nadzieję, że obeszło się bez siwych włosów. :) Bolesna chłosta czeka wszystkich tych, którzy chcieli popsuć zabawę innym publicznie odpowiadając lub podpowiadając. Wstydźcie się! :P
Padało wiele różnych odpowiedzi. Część z grających uznała, że wystarczy wpatrywać się w grafikę wystarczająco długo i nadejdzie olśnienie. Stąd zapewne takie odpowiedzi jak fxk, fyk, RYK, "i, zygzaki, schodki" czy "biały, czerwony, czarny". :) Część ewidentnie nie lubi podpowiedzi, bo na pytanie dotyczące Intela odpowiadała IBM lub AMD. ;] Wiele osób strzelało wpisując TLA związane z Intelem: QPI, C2D, GMA, DUO,... Część celowała bardziej ogólnie: x86 czy też w szalenie popularne CPU.
Wreszcie były i odpowiedzi zaskakujące. Część z nich to nazwy części ciała, których opublikować nie mogę. ;> Kolejna grupa to wyrazy zdziwienia. Trafiło się "haha!!!", "ale jaja!", popularne "LOL" i kilka wezwań o łaskę z nieba. Niektórzy z grających podzielili się opinią na temat pytania, kilkoro postanowiło zadać nam pytanie. Odpowiadam na jedno z nich: nie, to nie jest alfabet Braille'a. :) Trafił się też link do akcji Pajacyk i, moje ulubione: "jakie ładne... co to?". :D
I to tyle w materii rozgrzewki. Do następnego zadania specjalnego. Obiecuję, że będzie dużo trudniejsze. ;D
![Emocjonalna przygoda z krainą czczącą wieloryby. Selfloss [Recenzja]](https://v.wpimg.pl/MTk3LmpwYjUKUTpeXwxvIEkJbgQZVWF2HhF2T19CdGMTAH1bXwMoNwMdOx0TEyN6G19jBB0QYmUKAHxfEUJ4eQ4BegldQ3UxWR4tWxNGYGcJB3leFBF0Y1oKe0MaByp2Fg)
![Taktyczna strzelanka 2D dla miłośników skradania. Intravenous 2 [Rzut okiem]](https://v.wpimg.pl/ZjlkLmpwdQsNCTpeXwx4Hk5RbgQZVXZIGUl2T19CY10UWH1bXwM_CQRFOx0TEzREHAdjBB0QdQ4PWS0OQhVsR1pYfVVdQ2taXEYuWhQRd1gPXnULQkNiCwpSKEMaBz1IEQ)

![Mroczna Metroidvania dla masochistów. Voidwrought [Pierwszy rzut okiem]](https://v.wpimg.pl/NzU1LmpwYRs0UzpeXwxsDncLbgQZVWJYIBN2T19Cd00tAn1bXwMrGT0fOx0TEyBUJV1jBB0QYUtiA3VeEhJ-VzdXfghdQygbNxwuCxIWY0M0CS1fQxZ6S2IEeUMaBylYKA)
![Mroczna Rewolucja i Taktyczna Walka w Świecie Roguelite. Liberté [Recenzja]](https://v.wpimg.pl/OThlLnBuYDUJDjpdbQ5tIEpWbgcrV2N2HU52TG1AdmMQX31YbQEqNwBCOx4hESF6GABjBy8SYGddD34IcREpeV9ZdV9vQS02X0EuXnJFYjJdXC1XIRd8NlFUKUAyGyh2FQ)


![Praca / Multimedia / Granie: idealne stanowisko komputerowe [opinia]](https://v.wpimg.pl/YWZhLkpQdjY7CjpYXyp7I3hSbgIZc3V1L0p2SV9kYGAiW31dXyU8NDJGOxsTNTd5KgRjAh02djFrDnVYSGlsemtZflNdZTphaUV0WxIwdGA-Wn5aFmZuZjsOLUU6AR51Jw)