

Jak podbić agregatory treści i teoria posta idealnego
Jakiś czas temu miała miejsce następująca historia: wróciłem spokojnie z gry ASG do domu i po upchnięciu sprzętu w szafie rozsiadłem się przed laptopem celem odpoczynku. Zajrzałem m.in. na główną Wykopu, bo chociaż zdecydowanie preferuję Reddita i to tam oddaję swoje kliki, czasem dobrze jest być zorientowanym, co w rodzimych socjalach piszczy.
Możecie chyba wyobrazić sobie moje zdziwienie, kiedy na stronie głównej zobaczyłem nic innego, jak mój własny wpis. Fantastyczna sprawa, tym bardziej, że (nieco na przekór obecnym trendom) praktycznie nie promuję własnego bloga na DP w sposób inny niż regularne pisanie i link w CV.
Przebić się na agregatorach treści nie jest wcale łatwo. Dodawane znaleziska często kończą swój żywot na kilkunastu odwiedzinach, zakopane na dziesiątych z kolei podstronach serwisu i bez żadnych głosów dodatnich ani komentarzy. Patrząc z kolei na strony główne, można nawet odnieść wrażenie, że proces osiągania sukcesu jest zupełnie losowy i że wybić się można tylko jakimś dziwacznym viralem. Najlepiej z kotami.

Jakoś pod koniec ubiegłego roku temu ukazał się jednak bardzo ciekawy artykuł autorstwa ludzi ze Stanford University, zatytułowany „What’s in a name? Understanding the Interplay between Titles, Content, and Communities in Social Media”. Najkrócej rzecz ujmując, badacze skupili się na zależnościach pomiędzy tytułem dodawanego znaleziska, czasem dodania, stopniem personalizacji pod kątem grupy docelowej a jego sukcesem. I, jak się możecie domyślać z samego faktu iż ten wpis powstał, wnioski warte są chwili uwagi.

Powyższy wzór, wyjęty żywcem z raportu dostępnego za darmo w Internecie, może na pierwszy rzut oka wglądać na skomplikowany, ale nie trzeba nawet specjalnie się nad nim zagłębiać, bowiem jest on rozłożony na czynniki pierwsze i świetnie wyjaśniony przez autorów na kolejnych stronach. Nas interesują jedynie wnioski, skoncentrujmy się więc na trzech typach grafów:
Zachęć

Jak widać, w zależności od docelowego subreddita, istnieją słowa znacznie zwiększające lub zmniejszające szanse dodanej treści na sukces. W dodatku nie są to jakieś oczywistości – przykładowo w kategorii Pics bardzo negatywnym słowem jest najzwyklejsze „interesting”. Jako stały użytkownik reddita i człowiek dociekliwy zbadałem, czy metodologia mogła wypaczyć wyniki i nie, one naprawdę są wiarygodne. W dodatku po fazie zbierania danych autorzy zrobili eksperyment, którego wyniki w 100% pokrywają się z założeniami.
Nie zwrócili oni jednak uwagi na jedną rzecz, którą uważam za interesującą – najlepsze wyniki osiągnęły w tabelce na dole tytuły: ‘MERICA i God bless whoever makes these…
Oba mają coś wspólnego – są mało konkretne i nęcą użytkownika do kliknięcia. Jeżeli ktoś siedzi na Reddicie czy Wykopie, to zazwyczaj jest w stanie poświęcić chwilę czasu na taką niespodziankę. Z jednej strony, przeważa chęć odkrycia czegoś fajnego i nieznanego ogółowi. Z drugiej zaś, luźna atmosfera panująca na tych portalach pozwala bezproblemowo potencjalnie stracić chwilę czasu zupełnie bezproduktywnie (np. link prowadzi do czegoś o kiepskiej jakości). Z nieco bardziej osobistego punktu widzenia, enigmatyczne tytuły linków do obrazków/video z samym „Bo to Polska właśnie” „Polska….” „Tylko w Polsce” oraz wszelkie inne wariacje faktycznie wydają się być interesujące, gdyż zazwyczaj prowadzą do często szukanych i lubianych treści (fuszerki budowlane, śmieszne obrazki, dziwne sytuacje) i to w dodatku w ujęciu lokalnym. Zdjęcie wibratora sprzedawanego w Biedronce jest dla polskiego odbiorcy ciekawsze niż analogiczne z Wal‑Martu.
Idąc dalej:
Nisza vs dopasowanie
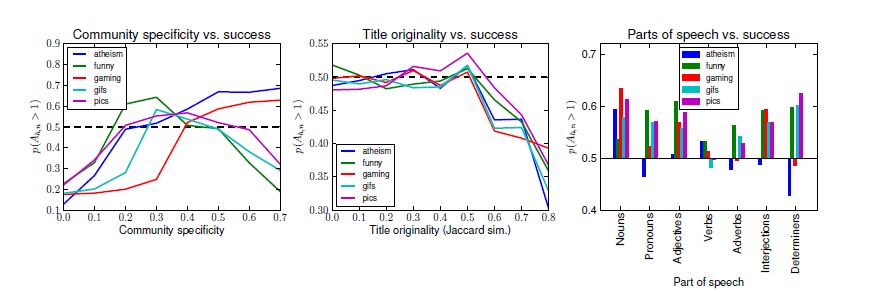
Skupmy się na chwilę na krzywej po lewej stronie obrazka. Nie jest ona jednostajna, tak naprawdę najbliżej jej chwilami do krzywej Bella. Oznacza to, że z krojeniem treści na miarę należy uważać – zbytnia personalizacja prowadzi bowiem do wejścia tematu w niszę, co ma bardzo negatywny wpływ na szanse na sukces. To samo widać na wykresie w środku – od pewnego momentu oryginalność tytułu szkodzi, a nie pomaga. Znalezisko musi więc być zatytułowane unikatowo, ale bez zbytniej ekstrawagancji.
Trzeci wykres przedstawia z kolei zależność między częściami mowy użytymi w tytule a sukcesem treści. I tak, różne subreddity (a więc grupy userów skupionych wokół danego tematu w ramach większej społeczności całego Reddita) mają różne preferencje. Nie sądzę, aby dało się przekleić ich gusta choćby na Wykop w stosunku 1:1, ale na pewno pokazuje to istnienie pewnych zależności i potencjalnie można zacząć samemu kolekcjonować takie dane.
Czas na ostatni na dzisiaj wycinek:
Znaczenie powyższego
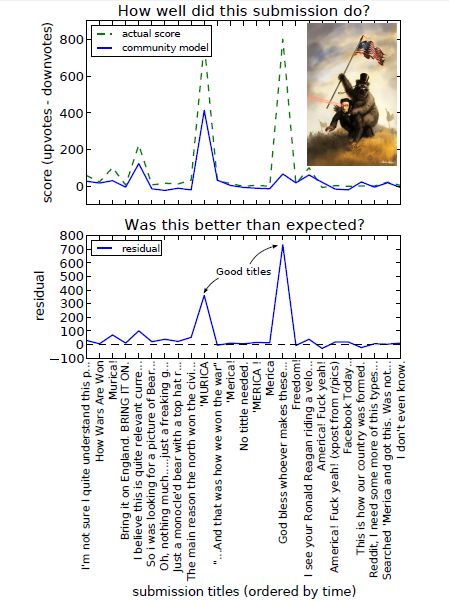
Jak widać, tylko dwa wspomniane już wcześniej tytuły odniosły zauważalny sukces. Wyniki części z pozostałych oscylują wręcz w granicach zera.
Gdyby spróbować streścić wnioski płynące z całego artykułu, brzmiałyby one tak:
- Tytuł nie jest ważny, jest absolutnie kluczowy
- Czasem ta sama rzecz osiąga różne wyniki w zależności od kilku czynników
- Istnieje pewien czas, po którym można wrzucić coś, co już było i negatywne konsekwencje nie wystąpią
- Personalizacja i oryginalność po osiągnięciu pewnego stopnia zaczynają szkodzić
- Istnieję dobre i złe słowa, częściowo mało oczywiste
- Kluczowe są czas i miejsce wrzucenia
Czy można przełożyć wyniki na nasz rodzimy rynek? Jak już wspominałem, uważam że tak. Wbrew pozorom różnice między portalami nie są jakieś ogromne, wystarczy samemu zebrać odrobinę danych aby posiadać zmienne dotyczące specyfiki społeczności itp. Wierzę też, że taka wiedza może być szalenie przydatna i zrobić naprawdę dużą różnicę.
Co ciekawe, nie ma żadnych informacji jakoby ktoś takie dane u nas faktycznie gromadził, a może być z tego niezły biznes. Tylu mamy (lepszych i gorszych) social media specialistów, a co gdyby faktycznie znaleźć ich Złotego Graala i oferować komercyjnie gwarancję, że dana kampania/projekt/cokolwiek będzie sukcesem i zadowoli ich klientów?



![Bezprzewodowy odkurzacz 5 w 1 z funkcją mopowania. JIMMY PW11 Pro Max [Recenzja]](https://v.wpimg.pl/NmZkLkpQYQw7CTpYXypsGXhRbgIZc2JPL0l2SV9kd1oiWH1dXyUrDjJFOxsTNSBDKgdjAh02YQloDi8JQGUoQGJceVJdZX5cb0YtDhVjY1pjWCldQTQrCGwNKEU6AQlPJw)

![Otwarte słuchawki bezprzewodowe TWS. Baseus Eli Sport 1 [Recenzja]](https://v.wpimg.pl/OWMyLmpwYDYsGzpeXwxtI29DbgQZVWN1OFt2T19CdmA1Sn1bXwMqNCVXOx0TEyF5PRVjBB0QYGZ4S31eR0cren1BelpdQytkKFR1DhNBYjJ4GngLRUYuNHQafkMaByh1MA)

