

e‑książki a formatowanie tekstu
E‑książki (zwane również e‑bookami) stają się ostatnio coraz popularniejsze. Coraz więcej księgarni ma w swej ofercie publikacje w postaci cyfrowej. Zabawną kwestią jest to, że książki papierowe objęte są 5 procentowym VATem, natomiast książki cyfrowe - 23 procentowym. Nie o tym jednak chciałem pisać…
Jakość produktu, za który płacimy
Człowiek płaci, człowiek wymaga. A czego? Jakości! Niestety e‑książki, które dostępne są w różnego rodzaju księgarniach są robione po prostu byle jak. Tekst się zgadza (choć też nie zawsze), prezentuje się na czytniku niby przyzwoicie, ale niestety idealnie nie jest. Zajrzałem więc kiedyś z ciekawości do kodu pliku .epub pobranego z bazy publikacji wolnelektury.pl i niesamowicie się zdziwiłem.
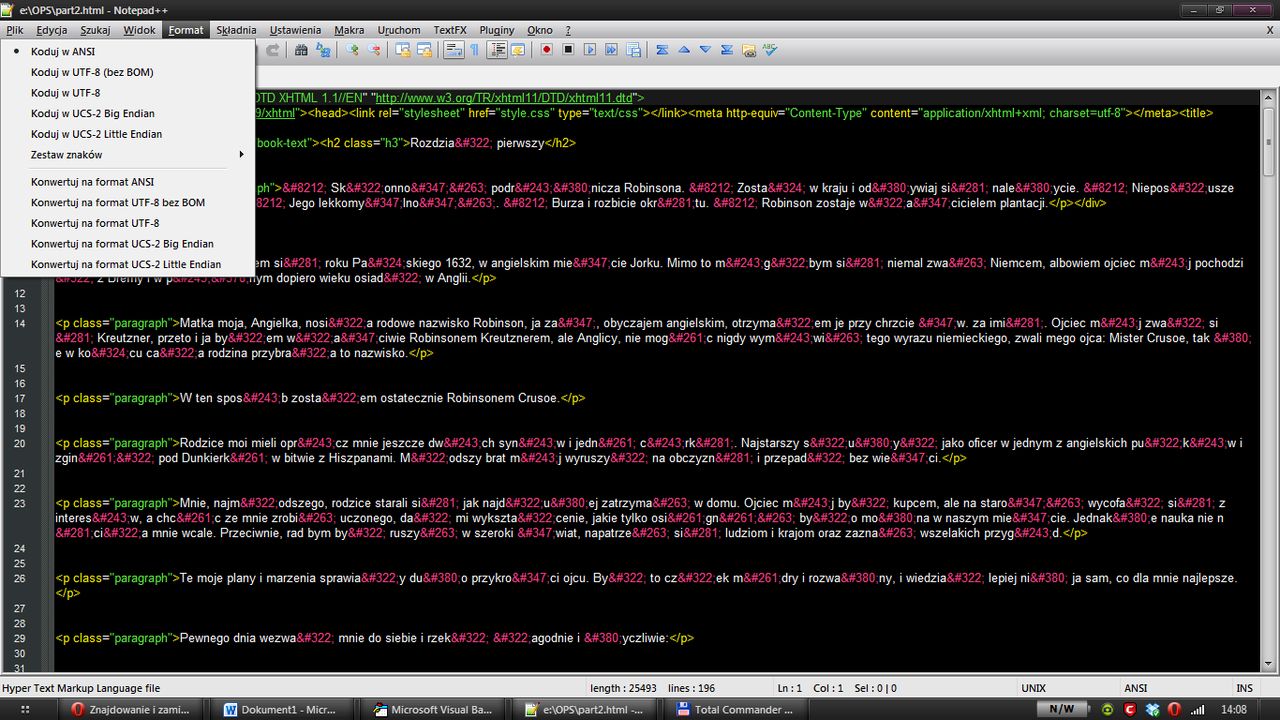
- Kod polskiej publikacji w ANSI a nie w UTF-8,
- znacznik nagłówka 2 z przypisaniem do klasy H3 (niezły misz-masz),
- brak znaków twardej spacji (przez co na końcu linii pozostają osierocone spójniki - widział ktoś, by coś takiego miało miejsce w drukowanej publikacji?!).

I coś, czego nie widać na zrzutach ekranu:

- stosowanie na przemian znaków minusa, pauzy i półpauzy (przez co moduł text-to-speech ma problemy i czasami zdarza się, że na początku każdej wypowiedzi w rozmowie czyta na głos słowo „minus”),
- stosowanie wielu znaków końca linii (Enterów) zamiast ustalić odstęp za pomocą stylu,
- stosowanie wielu spacji zamiast użycia tabulacji,
- itp., itd.
Ręce mi opadły. W przypadku plików z WeltBilda, Empiku czy NextTo wcale nie jest lepiej.
Skąd taki stan rzeczy?
Powodów może być wiele, ale wydaje mi się, iż głównym z nich jest to, że za tworzenie e‑książek odpowiedzialni są humaniści bez podstawowej wiedzy z zakresu korzystania z pakietów biurowych. Nie oszukujmy się - dziś mało kto tworzy publikacje w Acrobat Pro lub InDesign. Zdecydowana większość publikacji powstaje w Wordzie/Writerze i jest ona tworzona za pomocą funkcji „Zapisz jako PDF”. Fraza „znajomość pakietów biurowych” to dziś standard w CV, jednak mało kto tak naprawdę potrafi z tych programów korzystać. Niektórzy piszą to z premedytacją, by ubarwić swoje CV, inni piszą to, bo w swej głupocie naprawdę uważają, że potrafią korzystać z Worda. Tymczasem po zaznaczeniu opcji pokazywania ukrytych elementów formatowania cała ta „wiedza” pięknie się ukazuje.
Calibre i jakość konwersji formatów ebooków
Do tego wpisu skłonił mnie komentarz DjLeo pod newsem o pojawieniu się nowej wersji programu Calibre.
Co do samej konwersji na formaty epub czy mobi to ta heurystyka pozostawia jeszcze wiele do życzenia. Przynajmniej jeżeli chodzi o konwersje z pdf‑ów.
Mając na uwadze to, co napisałem powyżej o umiejętności korzystania z programów do redagowania tekstu przez twórców/redaktorów e‑książek nasuwa się pytanie - w jaki sposób Calibre ma konwertować idealnie e‑książki na różne formaty, skoro pliki źródłowe wołają o pomstę do nieba? Np. zamiast konkretnych nagłówków są inne (np. tak jak wyżej na obrazku H2 z przypisaną klasą H3) lub tytuły rozdziałów są tworzone poprzez wyśrodkowanie tekstu zwykłego akapitu, powiększenie jego czcionki i jej pogrubienie. Jeśli chodzi o nagłówki to przecież w przypadku e‑publikacji są one dość istotne, bo na ich podstawie generowane są spisy treści.
Nie da się więc stworzyć skryptu, który konwertowałby idealnie publikacje cyfrowe pomiędzy różnymi formatami, bo trzeba by przewidzieć wszystkie możliwe sposoby używania edytorów tekstu przez ludzi, a ile ludzi, tyle różnych sposobów obsługi Worda, Writera i innych programów. Nawet gdyby komuś udało się coś takiego zrobić, to skrypt ten pewnie pracowałby kilka godzin, by ogarnąć jedną książkę.
Lekarstwo?
Przestudiowałem specyfikację formatu FutureBook (FB2). Nie jest on w Polsce specjalnie popularny, ale e‑booki czytam za pomocą aplikacji FBReader więc wybór formatu wydał mi się oczywisty. Swoją drogą okazało się, że jego składnia okazała się dla mnie dużo bardziej przejrzysta niż te z formatów EPUB czy MOBI. Stworzyłem sobie w Wordzie własny zestaw stylów i 3 makra (1. do usuwania zbędnych wolnych przestrzeni - wielu enterów, spacji i tabulatorów, 2. do poprawiania błędów formatowania - wstawianie twardych znaków, zamiana trzech kropek na znak trzykropka, zmiana minusa na pauzę, itd., 3. Do konwersji kodu HTML do kodu FB2). Następnie dostosowałem sobie Worda tak, by mi się wygodnie z niego korzystało.
Na warsztat wziąłem więc pierwszą lepszą e‑książkę, którą była „Gra o tron” George’a R. R. Martina. Przekopiowałem tekst z epuba do Worda, a w nim pozmieniałem formatowanie tekstu za pomocą stylów, odpaliłem makra do usuwania pustych przestrzeni i do poprawiania błędów, a następnie zapisałem dokument jako przefiltrowany html. Otworzyłem tekst w notatniku i skopiowałem go do Worda, a następnie uruchomiłem makro do konwersji kodu html na kod fb2. Następnie ten kod przekopiowałem do Notepada++ i zapisałem plik jako FB2.
Efekt?
- Plik w 100% zgodny ze specyfikacją formatu FutureBook,
- DZIAŁAJĄCA możliwość dostosowywania pod siebie wyglądu KAŻDEGO elementu e-książki z poziomu aplikacji FBReader,
- Plik wynikowy (FB2) o wielkości 2090kB, a po zapisaniu jako FB2.ZIP plik ma wielkość 900kB. Warto dodać, że większość programów do czytania e-booków w formacie FB2 obsługuje je bez konieczności rozpakowywania archiwum ZIP, w którym znajduje się plik FB2,
- Plik źródłowy ePUB miał wiekość 2,7MB, a plik w tym samym formacie, który utworzyłem konwertując stworzony przeze mnie plik FB2 na format ePUB zaledwie 985kB. Czyli wychodzi na to, że w kupionym pliku 2/3 danych to śmieciowy kod,
- Okazało się również, że Calibre konwertuje pliki idealnie pomiędzy formatami FB2, ePUB i MOBI dając w efekcie pliki w 100 procentach zgodne ze specyfikacjami poszczególnych formatów, o ile format wejściowy jest zgodny z jego specyfikacją.
Tak więc wracając do zarzutu DjLeo:
Co do samej konwersji na formaty epub czy mobi to ta heurystyka [w Calibre] pozostawia jeszcze wiele do życzenia.
Czy to ta heurystyka faktycznie nie działa dobrze, czy może coś innego?



![Mobilny czytnik, który mógłby zostać smartfonem. Onyx Boox Palma [Recenzja]](https://v.wpimg.pl/MDliLmpwYiUNCzpeXwxvME5TbgQZVWFmGUt2T19CdHMUWn1bXwMoJwRHOx0TEyNqHAVjBB0QYnUKXXwOSUQvaVQLLlldQygmD0QtWkEWYHdYXXVZQEF_J1xQLkMaBypmEQ)



