Kurs Packet Tracer 6.2 — od zera do sieci tworzenia cz.4 — RIP i EIGRP
W poprzedniej części poznaliśmy podstawowe zastosowanie i funkcje najprostszego protokołu routingu dynamicznego – RIP. Dzisiaj na podstawie RIP poznamy kulisy pewnego niepojącego zjawiska mogącego wystąpić w sieciach – a mianowicie pętli routingu. W tej części poznamy kolejny protokół trasowania dynamicznego, który możemy skonfigurować w programie Packet Tracer – EIGRP. Dowiemy się także co nieco o redystrybucji pakietów między sieciami posługującymi się różnymi protokołami routingu. No to zaczynamy!
Liczniki RIP
Wcześniej dowiedzieliśmy się, że RIP wysyła aktualizację tras co pewien czas. Skąd router wie, w którym momencie ma wysłać taką aktualizację? Otóż, protokół RIP posiada cztery liczniki: Update Timer, Invalid Timer, Flush Timer i Hold-down Timer. One sterują takimi czynnościami. Czym dokładnie zajmują się te liczniki? Zobaczmy:

- Update Timer – jest to jeden z najprostszych liczników do zrozumienia. Jego wartość to po prostu interwał między dwoma rozgłoszeniami. Domyślna wartość tego licznika to 30. Oznacza to, że aktualizacje tras routingu są rozsyłane co 30 sekund.
- Invalid Timer – załóżmy, że router R1 dostaje od routera R2 cykliczne aktualizacje co 30s. Nagle komunikacja urywa się. Mija pewien czas i nadal nie ma żadnego znaku życia od R2. Co się wtedy dzieje? Router R1 uznaje, że R2 kopnął w kalendarz i oznacza ten router jako nieosiągalny. Za to właśnie odpowiada Invalid Timer. Jest maksymalny czas, przez który wpis w tablicy routingu może istnieć bez aktualizacji. Po upływie czasu zawartego w Invalid Timer router docelowy jest uznawany za nieosiągalny. Domyślna wartość tego licznika to 180s.
- Flush timer – Załóżmy, że trasa do routera R2 została uznana za nieosiągalną przez poprzedni licznik. Router jest nieosiągalny, jednakże wpis cały czas wisi w tablicy routingu. Czy tak będzie w nieskończoność? Otóż nie. Po upływie czasu zawartego w Flush timer wpis jest usuwany z tablicy routingu. Liczniki Flush timer i Invalid Timer są startowane automatycznie – w momencie, kiedy nie występują aktualizację ze strony routera R2. Stąd też wartość licznika Flush timer musi być większa od wartości licznika Invalid timer. Domyślna wartość licznika Flush timer wynosi 240 sekund. Przykład: Jeśli od routera R2 nie docierają informacje aktualizacyjne, to po 180s trasa do tego routera jest oznaczana jako nieosiągalna, a po kolejnych 60s wpis jest usuwany z tablicy routingu.
- Hold-down timer – ten licznik ma najbardziej skomplikowane zadanie. Wróćmy jeszcze raz do wcześniej wspominanego przykładu. Router R2 staje się nieosiągalny. Trasa do niego jest oznaczana jako nieosiągalna. Co jednak stanie się, jeśli w tym momencie od innego routera (np.: R3) dostaniemy informację o tym, że jednak istnieje trasa do R2? Mogłoby wtedy powstać zjawisko pętli routingu, o którym więcej będzie w następnym rozdziale. Aby do tego nie dopuścić, opracowano właśnie ten licznik. Jeśli od routera, do którego biegnie dana trasa (w tym wypadku R2) nie otrzymano informacji aktualizacyjnych, to trasa ta, po oznaczeniu jako nieosiągalna, nie może być nadpisana przez informacje aktualizacyjne otrzymywane od innych routerów. Domyślna wartość tego licznika to 180 sekund. Pomyślmy, jak to by wyglądało w naszym przykładzie. Otóż, jeśli trasa do R2 zostanie oznaczona jako nieosiągalna, to przez 180 sekund informacja o „nieosiągalności” tego routera nie może zostać zmieniona. Nawet jeśli nasz router dostanie informację o dostępnej trasie, np.: od R3 to informacja ta nie zostanie wpisana do tablicy routingu naszego routera.
Pętla routingu – czyli „korek w sieci”.
Jak wiemy z poprzedniej części kursu, routery zapisują trasy do poszczególnych sieci w swoich tablicach routingu. Dzięki nim router wie, do kogo wysłać dany pakiet tak, aby dotarł do miejsca docelowego. Co się jednak stanie, jeśli przez przypadek do tablicy routingu zostanie wprowadzona jakaś błędna informacja? Może to zagrozić spójności sieci, a także doprowadzić to tzw. „pętli routingu”. Cóż to takiego jest? Zjawisko to może wystąpić na przykład w sytuacji, kiedy jedna z sieci przyłączonych bezpośrednio do routera stała się niedostępna. Zjawisko to polega na tym, że pakiet krąży między dwoma routerami (np.: R2 wysyła go do R1, a R1 odsyła do R2). Zajmijmy się analizą przykładowej sytuacji, w której może wystąpić pętla routingu.
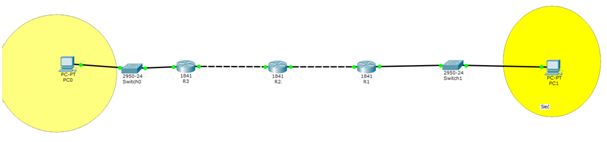
Załóżmy, że wszystkie funkcje zapobiegające pętlom routingu (takie jak podzielony horyzont, o czym mowa będzie później) są wyłączone. W pewnym momencie połączenie między R1 a Switch1 się urywa …
R1 bezpośrednio przyłączony do tej sieci wymaże nieaktualną informację z tablicy routingu. Lecz jeśli w tym momencie od innego routera (np.: R2) otrzyma kopię tablicy routingu zawierającą feralną sieć, to R1 wpisze sobie do swojej tablicy, że trasa do niedostępnej sieci biegnie właśnie przez R2, od którego otrzymano informację. Jeśli w tym momencie jakiś komputer będzie chciał połączyć się z niedostępną siecią, to przebieg trasy pakietu będzie następujący:
- R2 otrzymuje pakiet. W swojej tablicy routingu ma zapisane, że aby pakiet dotarł do docelowej sieci, musi zostać wysłany do R1. Tak też się dzieje.
- Pakiet dociera do R1. Przez to, że R1 otrzymał błędną informację od R2, sądzi, że należy pakiet wysłać do R2. Tak też się dzieje.
- R2 otrzymuje pakiet. Powtarza się sytuacja z punktu pierwszego.
Występowanie w sieci pętli routingu niesie ze sobą wiele przykrych konsekwencji. Pakiety, które były adresowane do konkretnej sieci, mogą „ugrząźć w korku” między dwoma routerami i nigdy nie dotrzeć do celu. Pętle routingu powodują obciążenie procesora routera przez co sieć staje się mniej wydajna.
Na szczęście, projektanci protokołów trasowania przewidzieli taką sytuację i opracowali kilka sposobów na ominięcie tego typu problemów. Są to:
- Czas „wstrzymania” (hold-down timer) – został omówiony w poprzednim rozdziale, więc nie będę do tego wracał.
- Podzielony horyzont (Split-horizon) – bardzo ciekawa funkcja. Jeśli ta funkcja nie jest włączona, to R2, po otrzymaniu informacji aktualizacyjnej od R1, natychmiastowo wyśle do R1 kopię własnej tablicy routingu. Zwykle nie ma takiej potrzeby. Taka funkcjonalność nie przynosząc wielkich zalet, może natomiast powodować wiele problemów, takich jak nieprawidłowe wpisy w tablicy routingu..
- Uaktualnienia zatrucia zwrotnego (poison reverse updates) – jeśli w sieci istnieje pętla routingu, to zjawisko takie najłatwiej rozpoznać po metryce, która zwiększa się w niekontrolowany sposób. W takiej sytuacji są wysyłane uaktualnienia zatrucia zwrotnego, które mają na celu usunięcie nieprawidłowej trasy z tablic routingu routerów. Podobną funkcję w protokole RIP pełnią tzw. „triggered updates”. W skrócie, jeśli sieć przyłączona do routera okaże się nieosiągalna, to natychmiastowo, bez czekania na Update Timer wysyłana jest informacja do pozostałych routerów o nieosiągalności trasy.
Zaawansowana konfiguracja protokołu RIP
Wiemy już, co to jest pętla routingu. Zastanówmy się teraz, jak skonfigurować protokół RIP, aby uniknąć takich sytuacji. Skupimy się głównie na drugiej wersji protokołu RIP, umożliwiającą korzystanie z VLSM. Poznamy także inną przyczynę powstawania pętli routingu, która wynika ze źle skonfigurowanej funkcji „auto summary”. Tak więc zaczynajmy!
W poprzednim rozdziale poznaliśmy rodzaje liczników RIP. Spróbujmy teraz w praktyce zmienić wartość poszczególnych liczników i ustalić, jak to wpływa na sieć w rzeczywistości. Przyjmijmy, że otrzymałeś od pewnej firmy następujące zadanie:
„Chcemy stworzyć sieć składającą się z czterech routerów. Wszystkie sieci muszą się ze sobą łączyć. Do łączenia routerów należy użyć adresów IP z sieci 10.0.0.0/31. Natomiast komputery powinny znajdować się w podsieciach 172.20.0.0/29”. Należy użyć protokołu RIPv2. Konwergencja powinna być sześciokrotnie mniejsza niż przy tradycyjnej konfiguracji. Komputer z dowolnej podsieci powinien mieć możliwość połączenia z dowolnym innym. Po to cię wezwaliśmy.”
Link do zadania znajduje się tutaj. (plik: zad1.pka). Poniższa tabelka zawiera adresy IP interfejsów, które należy przydzielić routerom abyś wykonał zadanie zgodnie z zaleceniami.
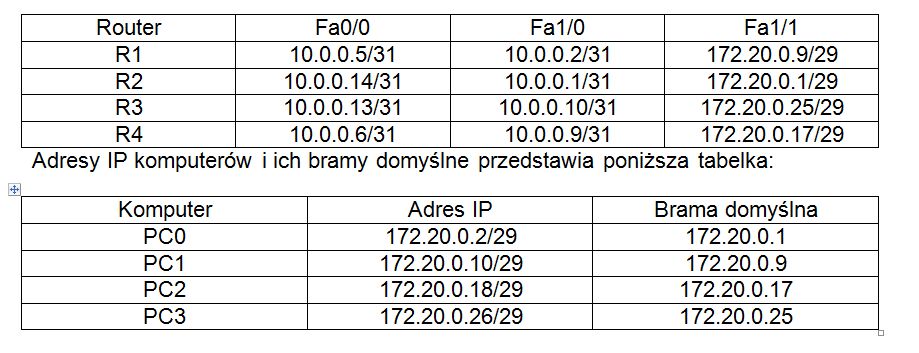
Musimy osiągnąć łączność między wszystkimi komputerami. Aby to uczynić, musimy skonfigurować protokół RIP w wersji drugiej. Dzieje się to podobnie, jak w wypadku wersji pierwszej. Jedyną różnicą jest to, że musimy poinformować router o tym, że chcemy użyć właśnie wersji drugiej protokołu RIP.
Pamiętasz pewnie jak wejść do trybu konfiguracyjnego routera. Będąc w CLI wydajemy polecenie config t. Potem należy wydać polecenie router rip, aby przejść do konfiguracji protokołu routingu. Tu poznamy jedno z nowych poleceń. Aby zadeklarować, że chcemy użyć drugiej wersji protokołu RIP, musimy wydać polecenie version 2. Dzięki temu sieci VLSM będą rozgłaszane poprawnie. Jak pamiętasz, informacje o rozgłaszanych sieciach wpisywaliśmy za pomocą polecenia network. Polecenie to nie przyjmuje jako argumentu maski podsieci. Więc np.: jeśli mamy podsieci 10.0.0.4/31 i 10.0.0.8/31 to wystarczy, że wydamy polecenie network 10.0.0.0. Podsieci należące do sieci klasy A 10.0.0.0 zostaną rozpoznane automatycznie.
Dla R1 ciąg wydanych poleceń powinien być następujący:
version 2 network 10.0.0.0 network 172.20.0.0
Dla pozostałych routerów (R2‑R4) polecenia będą analogiczne.
Skonfigurowaliśmy podstawowy routing. Zanim przejdziemy do testów, zwróćmy uwagę na miejsca docelowe pakietów rozgłoszeniowych RIP. Przejdźmy w tryb symulacji i poobserwujmy chwilę (możemy klikać przycisk Capture/Forward aby szybciej dojść do tego momentu) do jakich urządzeń docierają pakiety rozgłoszeniowe RIP.
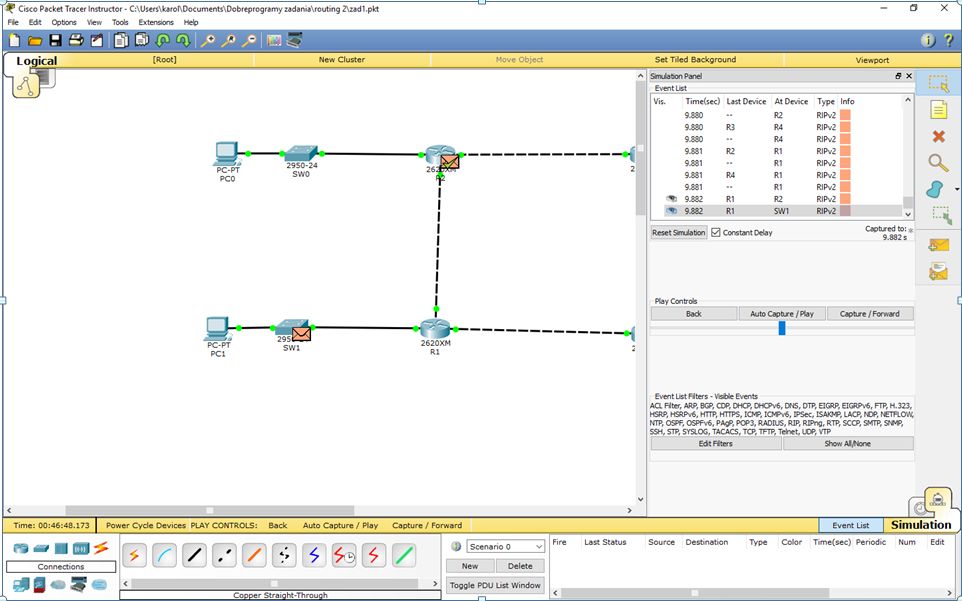
Zauważymy, że R1 poinformował nie tylko sąsiednie R2 i R4 o podsieciach. Informacja dotarła także do SW1. Nie stanowi to wielkiego problemu, ale mimo wszystko w takiej sieci generowany jest zbędny ruch. Aby to naprawić, musimy użyć kolejnego nowego polecenia: passive-interface. Jako argument polecenie to przyjmuje nazwę interfejsu. Jeśli ustawimy jakiś interfejs jako pasywny, to ten interfejs nie będzie wysyłał pakietów routingu. Na każdym z routerów ustawmy więc jako pasywny interfejs fa1/1, gdyż właśnie ten interfejs w każdym wypadku jest podłączony do podsieci zawierającej komputery.
Routing został skonfigurowany. Wejdź teraz na PC0 i spróbuj wysłać pakiet ICMP (czyli spingować) do komputera PC2. Wpisz polecenie ping 172.20.0.18.
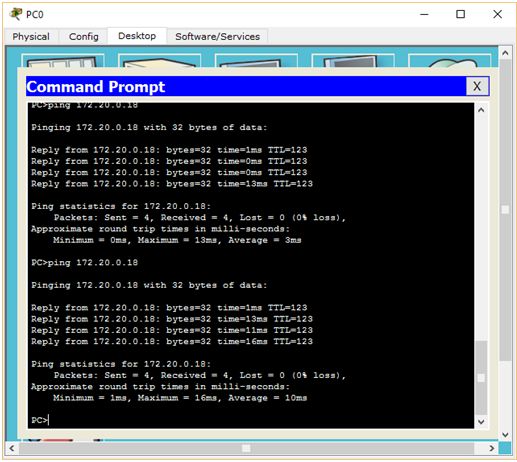
Jak widzimy, wszystko działa poprawnie. Komputer docelowy odpowiada. No to teraz spróbujmy spingować PC3 z PC0 (ping 172.20.0.26).
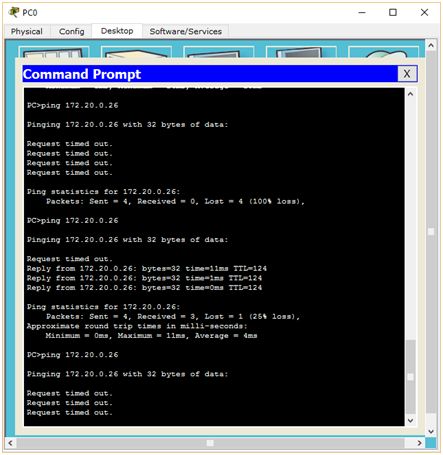
Coś jest nie tak. Bardzo często czas odpowiedzi został przekroczony. W moim wypadku, z 12 wysłanych pakietów jedynie 3 pozwoliły na odebranie odpowiedniego pakietu zwrotnego. Taki problem nie może występować w korporacyjnej sieci, gdyż byłaby po prostu niewydajna. Zastanówmy się, co poszło nie tak? Najprostszym sposobem jest przejście w tryb symulacji i obserwowanie drogi, jaką pokonują pakiety przez sieć. Zróbmy więc to. Tym razem spingujmy komputer PC3 z PC0 za pomocą „zamkniętej koperty”. Jeśli pakiet przebył poprawną trasę (PC0->SW0->R2->R3->SW3->PC3) to ponów próbę. Przy kolejnych próbach (prędzej czy później) zauważysz, że pakiet „zbacza” z optymalnej trasy. Np.: z R3 zamiast do SW3 trafia do R4, który z kolei wysyła pakiet do R1 a ten znowu odsyła go do R4. Dochodzimy do wniosku, że w tej sieci występuje typowa pętla routingu. Jednakże, czym jest ona spowodowana? Aby poznać przyczynę, musimy zajrzeć do tablic routingu poszczególnych routerów. Przeanalizujmy najpierw tablicę routingu R2.
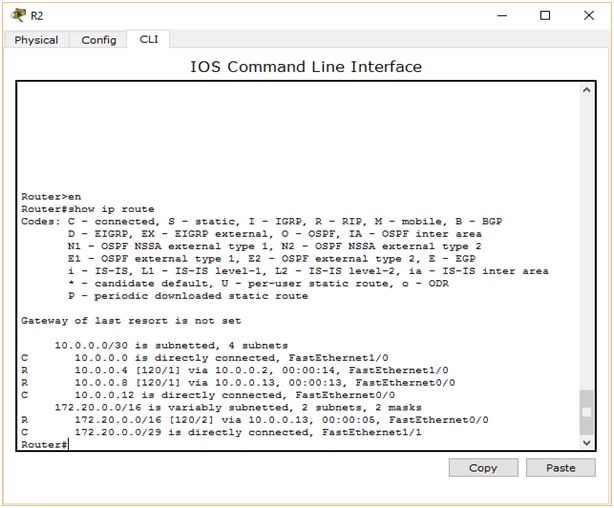
Niby wszystko jest w porządku. Zastanawiający jest jednak poniższy wpis: 172.20.0.0/16 [120/1] via 10.0.0.13 00:00:3 FastEthernet0/0
Zauważyłeś co się nie zgadza? Tak, to właśnie maska podsieci. W tablicy routingu mamy zapisane, że podsieć 172.20.0.0 ma maskę 255.255.0.0, co jest niezgodne z rzeczywistością. Nie widzimy za to prawdziwych podsieci, które zostały przez nas utworzone (poza tymi, które są bezpośrednio podłączone do R2). Spójrzmy więc na kolejny punkt trasy, czyli na R3:
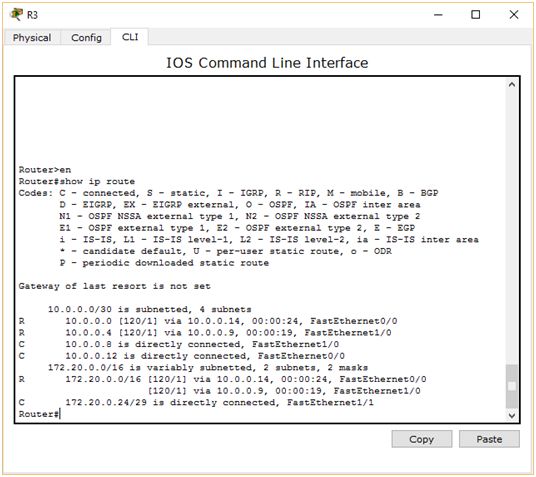
Tu widzimy jeszcze gorsze zamieszanie. Mamy powiedziane, że do podsieci 172.20.0.0 możemy dostać się aż przez dwa routery – o adresach 10.0.0.14 lub przez 10.0.0.9. Po raz kolejny nie widzimy wpisów odpowiedzialnych za trasę do utworzonych wcześniej podsieci (172.20.0.0/29, 172.20.0.8/29 172.20.0.16/29 i 127.20.0.24/29). Może więc wystąpić nawet taka sytuacja, że pakiet otrzymany od PC0 R2 wysyła do R3, R3 odsyła do R2 i tak w kółko. Routery powinny rozgłaszać adresy podsieci bezklasowo, a rozgłaszają klasowo. Jest to wynikiem działania funkcji „auto-summary”. W skrócie odpowiada ona za to, że wszystkie podsieci w tablicy routingu są sprowadzane do ich klasowego odpowiednika. Funkcja ta działa poprawnie jeśli do routingu używamy adresów klasowych. Problem pojawia się gdy zaczynamy korzystać z VLSM. Aby rozwiązać ten problem, na każdym z routerów musimy wydać polecenie: no auto-summary. Spójrzmy więc jeszcze raz na tablicę routingu R2, tym razem po wprowadzeniu zmiany:
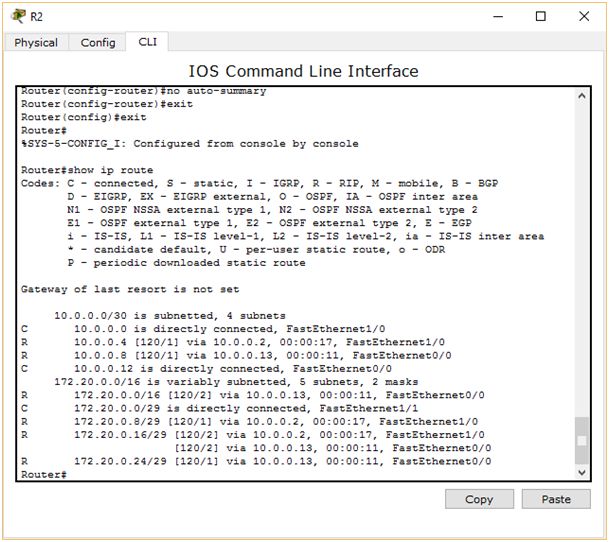
Widzimy ogromną różnicę. Teraz router posiada informację o każdej z istniejących podsieci. W takim wypadku nie powstanie już pętla routingu.
Został nam ostatni punkt do wykonania. Musimy sześciokrotnie zmniejszyć czas konwergencji sieci. Domyślasz się pewnie, że powinniśmy zmniejszyć wartość pierwszego licznika, odpowiadającego za interwał między rozgłoszeniami (Update Timer). Skoro domyślną wartością tego licznika jest 30s. To nowa wartość musi być sześciokrotnie mniejsza i wynosić 5 sekund. Aby zmienić wartość liczników, musimy użyć polecenia timers basic. Jako argumenty podajemy kolejne wartości liczników wg takiej kolejności, w jakiej je omawialiśmy (Update,Invalid,Holddown,Flush). My jesteśmy zainteresowani tylko licznikiem Update. Musimy więc na każdym routerze wydać polecenie:
timers basic 5 180 180 240
Hurra! Wykonaliśmy zadanie poprawnie. Właściciel tej sieci może być teraz zadowolony z naszej pracy :)
EIGRP – Extended Interior Gateway Routing Protocol
EIGRP jest protokołem wektora odległości. Stworzony został jako następca IGRP. Wielką zaletą w porównaniu z IGRP jest obsługa VLSM, co pozwala na znaczne zaoszczędzenie ilości adresów IP.
Podobnie jak RIP, EIGRP swoją wiedzę na temat sąsiadujących sieci opiera na uaktualnieniach, które są rozsyłane domyślnie co 90 sekund. Protokół IGRP/EIGRP posługuje się trzema rodzajami tras:
- Trasy wewnętrzne – trasy między podsieciami sieci powiązanych z interfejsem routera. (np.: między siecią podłączoną do fa0/0 i fa0/1 routera). Jeśli sieci powiązanej z interfejsem routera nie podzieliliśmy na podsieci, to trasy wewnętrzne nie są rozgłaszane.
- Trasy systemowe – trasy do innych sieci znajdujące się w obrębie jednego systemu autonomicznego
- Trasy zewnętrzne – trasy do innych sieci, znajdujących się w innym systemie autonomicznym.
Konfiguracja EIGRP jest banalnie prosta i bardzo podobna do konfiguracji wcześniej poznanego protokołu routingu – RIP.
Aby skonfigurować EIGRP na routerze, musimy w trybie konfiguracyjnym wydać polecenie router eigrp x. Zamiast x podstawiamy numer systemu autonomicznego. Potem należy dodać listę rozgłaszanych sieci. Robimy to tak samo, jak przy protokole RIP. Jednakże tym razem musimy także podać maskę podsieci w postaci wildcard (odwrotności maski tradycyjnej). Przykładowy ciąg poleceń mógłby wyglądać tak:
router eigrp 1 network 10.0.0.0 0.0.0.3 network 10.0.0.4 0.0.0.3 network 10.0.0.8 0.0.0.3 network 192.168.10 0.0.0.255
Również i w tym wypadku najlepiej wyłączyć funkcję auto-summary, gdyż może ona powodować problemy.
Metryka EIGRP
Wiesz już pewnie, co to jest metryka. Mówiliśmy o tym w poprzedniej części kursu. W przypadku RIP, jedynie liczba skoków określała jakość trasy. W EIGRP metryka jest o wiele bardziej skomplikowana i bierze pod uwagę większą ilość parametrów. Brane są pod uwagę następujące czynniki:
[list] [item]Pasmo – do dalszych obliczeń wybierana jest najniższa przepustowość (np.: chcemy dostarczyć pakiet od R1 do R3 przez R2. Połączenie od R1 do R3 ma przepustowość 1 Gbit/s, natomiast połączenie od R2 do R3 jedynie 10Mbit/s. Aby obliczyć metrykę bierzemy więc pod uwagę szybkość 10Mbit/s.[/item][item]Opóźnienie – każdy interfejs powoduje jakieś opóźnienie. Aby je sprawdzić, w trybie uprzywilejowanym możemy wydać polecenie: show interface x (gdzie za X podstawiamy rodzaj i numer interfejsu, np.: fa0/0). Dla interfejsów Ethernet domyślnym opóźnieniem jest 100 mikrosekund.[/item]
[item]Niezawodność – określana jest na podstawie wymiany komunikatów podtrzymania. Domyślnie nie jest brana pod uwagę przy wyznaczaniu metryki.[/item][item]Obciążenie – aktualne wykorzystanie łącza prowadzącego do miejsca docelowego. Domyślnie nie jest brane pod uwagę przy wyznaczaniu metryki.[/item][/list]
Dowiedzmy się teraz, jak ręcznie obliczyć metrykę EIGRP. Do jej wyliczenia musimy znać wartości pięciu stałych K1‑K5. Domyślne wartości przypisują wartość 1 stałym K1 i K3. Natomiast metryki K2, K4, K5 są równe zero. Poznajmy teraz wzór na metrykę:

Wzór jest nieco skomplikowany, prawda ?. Na szczęście w domyślnej konfiguracji jest on sporo uproszczony. Skoro wartości metryk K2, K4 i K5 domyślnie są równe zero a metryk K1 i K3 jeden, to zobaczmy co się stanie ze wzorem:

Widzimy, że w tym wypadku pod uwagę brane byłoby tylko pasmo. Byłoby to trochę niefunkcjonalne. Na szczęście twórcy protokołu EIGRP pomyśleli o tym i uznali, że przy domyślnych wartościach routingu nie powinniśmy brać pod uwagę ostatniego członu, który ma postać: K5/(Niezawodność+K4). W tym wypadku wzór ostateczny będzie miał postać:
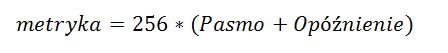
Do wzoru niestety nie możemy podstawić parametrów bezpośrednio odczytanych z wyniku polecenia show interface. Musimy to odpowiednio przekształcić. Wzory będą następujące:

Ostateczny wzór mógłby więc wyglądać tak:
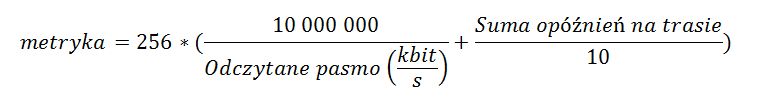
Aby zobaczyć metrykę EIGRP w praktyce, zbudujmy sieć o następującej topologii (możesz pobrać gotowy plik. Link znajduje się tutaj. (plik: przyk1.pkt).
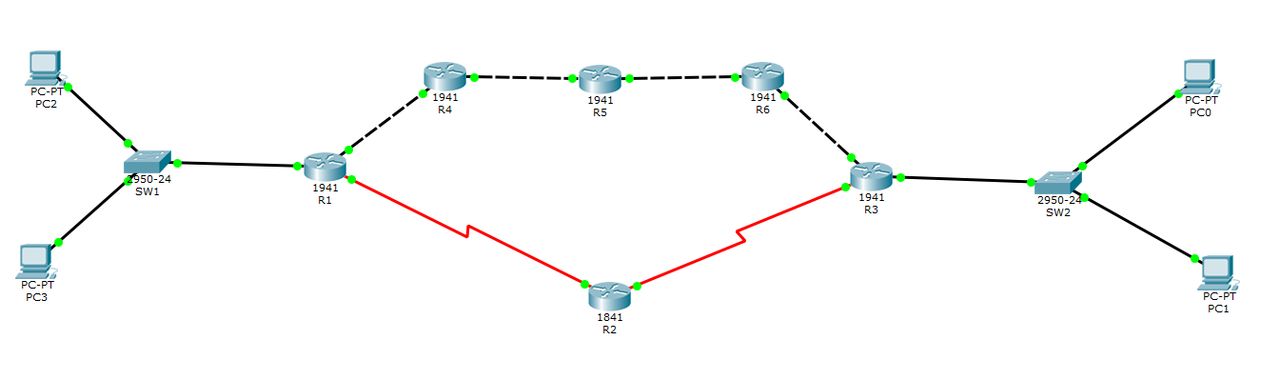
Zwróciłeś pewnie uwagę na nowy typ połączenia. „Czerwone pioruny” to połączenie typu serial – szeregowe. Jego zasada działania podobna jest do RS‑232. Szybkość zresztą też.
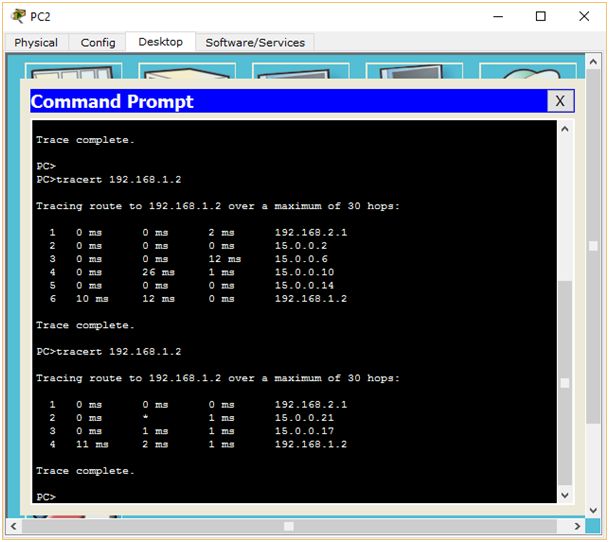
Spójrzmy dokładnie na wcześniej przedstawiony schemat sieci. Załóżmy, że naszym komputerem jest PC2 i chcemy wysłać pakiet do PC0. Istnieją dwie trasy do miejsca docelowego. Pakiet danych może zostać wysłany za pomocą łącza szeregowego przez R2 lub za pomocą Gigabit Ethernet przez R4, R5 i R6. Wydajniejszym rozwiązaniem na pewno będzie skorzystanie z drugiej opcji. W końcu łącze serial o przepustowości 1.5Mbit/s jest 666 razy wolniejsze od Gigabit Ethernet. Ale zastanów się, która opcja byłaby wybrana, gdyby sieć została oparta o protokół RIP? Aby dotrzeć z PC2 do PC0 przez łącze o większej przepustowości, musielibyśmy wykonać aż 6 skoków. Lecz jeśli skorzystamy z połączenia szeregowego będą to jedynie cztery skoki. Widzisz pewnie różnicę? Krótsza trasa nie zawsze oznacza lepszą trasę. Spójrzmy teraz na tablicę routingu R1.
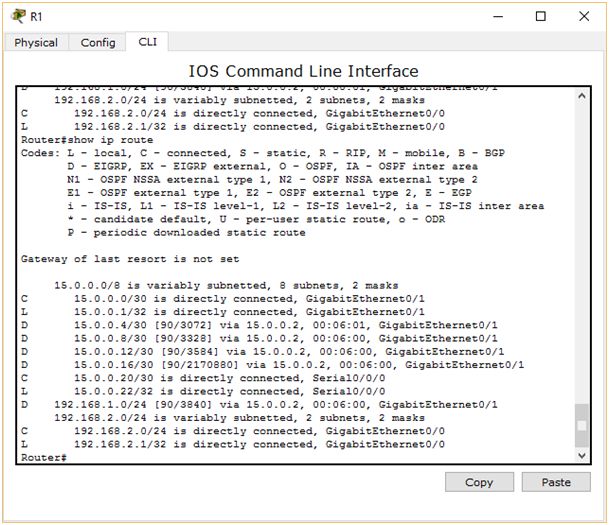
Dystans administracyjny protokołu EIGRP przy trasach systemowych wynosi 90. To znaczy, że jeśli na routerze mielibyśmy skonfigurowany zarówno RIP jak i EIGRP, to preferowaną trasą byłaby ta dostarczana przez EIGRP. Działoby się tak dlatego, gdyż dystans administracyjny protokołu RIP wynosi 120. Jest większy niż dystans EIGRP (90).
Metryka trasy do sieci 192.168.1.0 wynosi 6144. Zasymulujmy teraz „awarię” na łączu Gigabit Ethernet tak, aby jedyną dostępną opcją była podróż pakietu przez kabel Serial i spójrzmy, jak zmieni się tablica routingu.
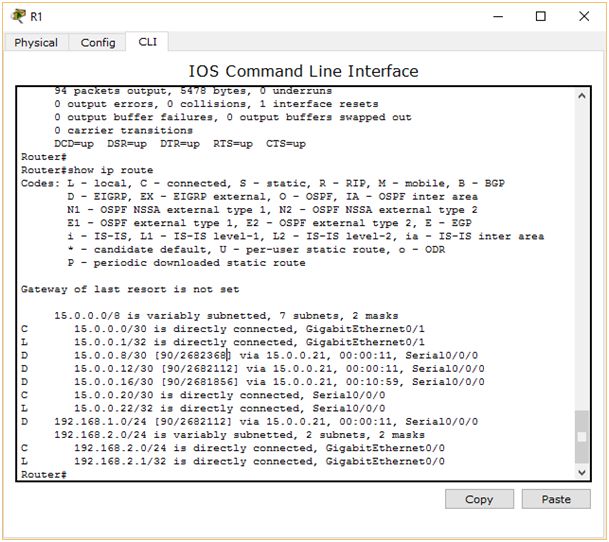
Metryka trasy do 192.168.1.0 zwiększyła się masakrycznie! Teraz widzimy tam liczbę 2682212, co oznacza, że druga trasa wg protokołu EIGRP jest 436 razy gorsza niż wcześniejsza.
Poznaliśmy wzory, spróbujmy więc przeliczyć ręcznie te metryki. Zajmijmy się najpierw bardziej optymalną trasą, biegnącą przez łącze Gigabit Ethernet.
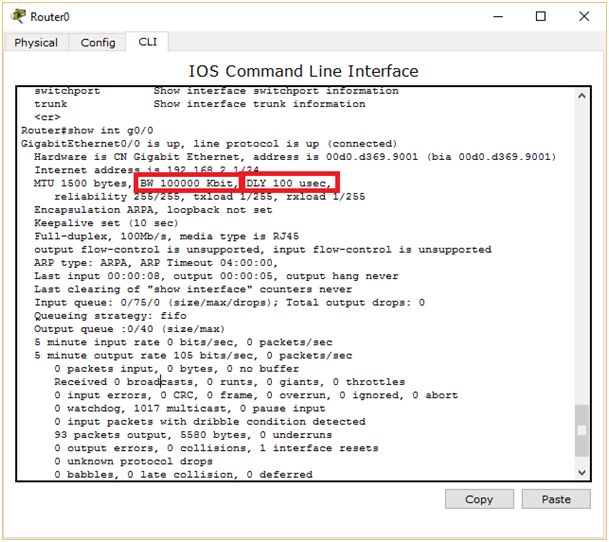
Musimy poznać dwa najważniejsze parametry tej trasy: szybkość i opóźnienie. Co do przepustowości, możemy się domyślić, jaka będzie jej wartość. Ale opóźnienia nie odgadniemy. Zresztą, po co się wysilać, skoro odpowiednich informacji może nam dostarczyć sam router? Użyjmy polecenia show interface, o którym wspominałem na samym początku niniejszego artykułu.
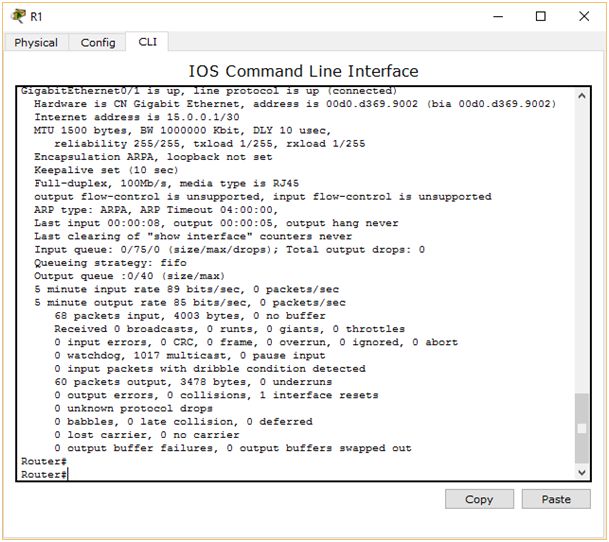
Parametry, na które musimy zwrócić uwagę to BW i DLY. W tym wypadku prędkość interfejsu to 1000000 kbit/s. Natomiast opóźnienie wynosi 10 mikrosekund. Policzmy więc:
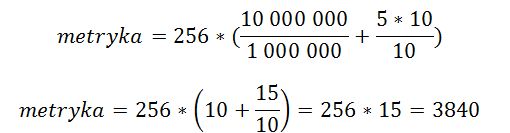
Pomnożyliśmy 10 przez 5, gdyż mamy 5 skoków (R4‑>R5->R6->R3->sieć docelowa). Wynik zgadza się z tym, co automatycznie obliczył router, więc poprawnie wyliczyliśmy metrykę. Obliczmy jeszcze metrykę drugiej, gorszej trasy. Zobaczymy, czy uzyskamy taki sam wynik jak router. Ponownie wydajemy polecenie show interface, tym razem jako argument podając interfejs szeregowy s0/0/0.
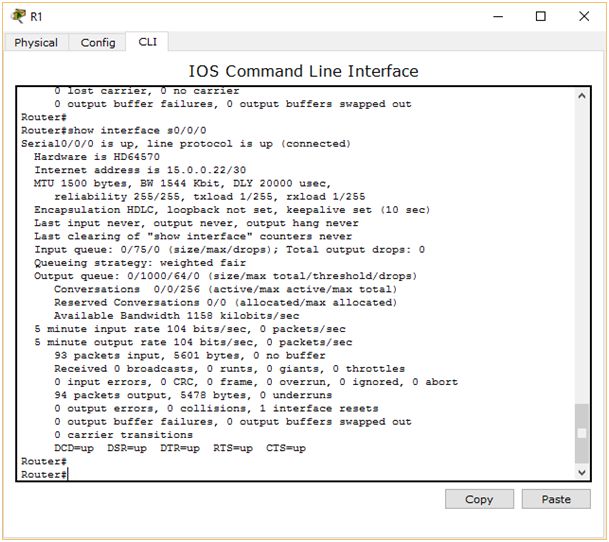
Odczytujemy parametry. Opóźnienie wynosi 20000 mikrosekund, czyli jest ponad 2000 razy większe niż w przypadku GigabitEthernet. Prędkość jest za to 650 razy mniejsza i wynosi 1544 kbit/s. Musimy wykonać dwa skoki, aby dostać się do routera R3 i jeszcze jeden, aby dostać się do docelowej sieci. Stąd nasz wzór będzie miał następującą postać:
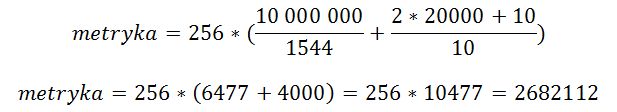
Po raz kolejny otrzymaliśmy poprawny wynik. Oznacza to, że bezbłędnie umiemy obliczać metrykę routingu EIGRP.
Warto jeszcze powiedzieć słówko na temat tej tajemniczej cyfry 256, przez którą mnożymy wynik dodawania. Bierze się to stąd, że EIGRP używa 32‑bitowej liczby jako metryki, natomiast IGRP jedynie 24‑bitowej. Aby zachować kompatybilność między tymi dwoma protokołami routingu, użyto swoistego „uzupełnienia” 24‑bitowej liczby do 32‑bitowej.
Podstawy redystrybucji – wymiana informacji między różnymi protokołami routingu
Załóżmy, że mamy sieć firmową, dobrze skonfigurowaną, działającą od kilku lat. Chcemy ją połączyć z nowo powstałym oddziałem naszej firmy. Sieć w drugim oddziale oparta jest o protokół EIGRP. Bez konfiguracji redystrybucji nie ma szans, aby te dwie sieci mogły się ze sobą skomunikować. Zobaczmy więc, jak wygląda najprostsza możliwa metoda konfiguracji na tym prostym przykładzie. Topologia jest dostępna do pobrania tutaj. (plik: zad2.pkt).). Spójrzmy na wstępną topologię:
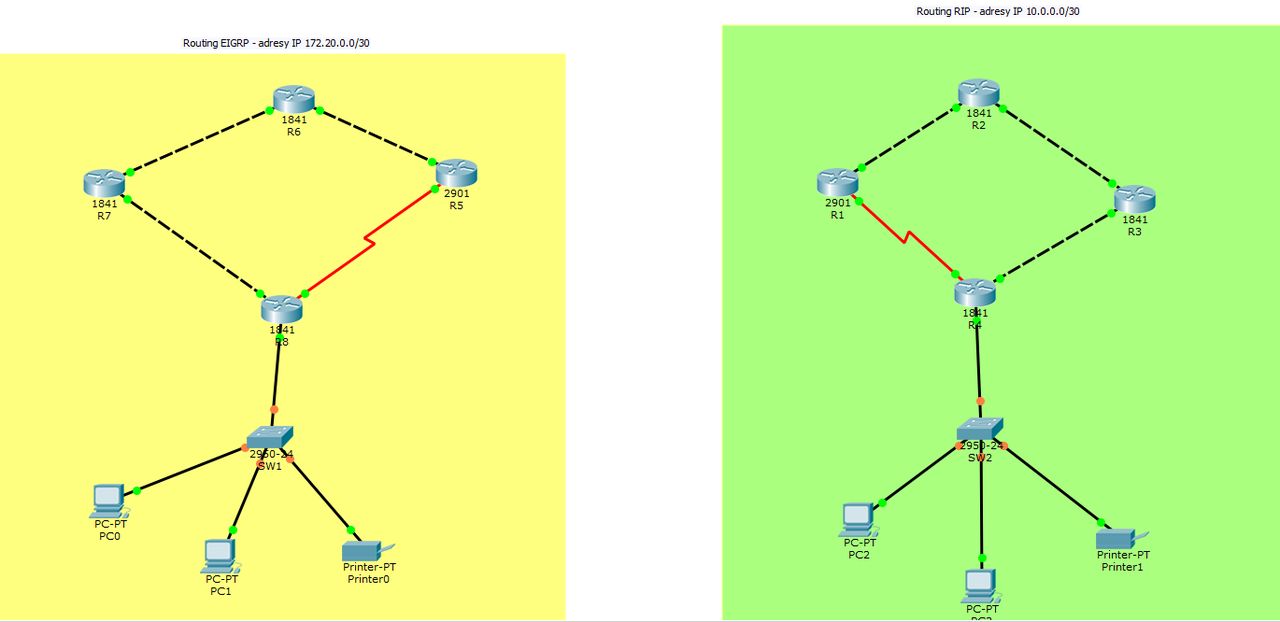
Naszym zadaniem jest połączenie sieci 172.20.0.0/30, w której jest stosowany routing EIGRP i 10.0.0.0/30, w której użyty został RIPv2. Najprostszym zadaniem będzie dołożenie kolejnego routera, który będzie „pośredniczył” w komunikacji między tymi dwoma sieciami. Nazwijmy go R9. Najlepiej, aby był to router 2901. Łączymy interfejs Gig0/0 R4 z Gig0/0 R9 oraz Gig0/1 R9 z Gig0/0 R8. Na R8 i R4 są już ustawione odpowiednie adresy IP. Na R9 Gig0/0 ustawmy adres 172.20.0.18 z maską 255.255.255.252 a na drugim interfejsie 10.0.0.18 z taką samą maską jak wcześniej.
Adresy IP ustawione. Teraz musimy skonfigurować routing w taki sam sposób, jak robiliśmy wcześniej. Różnica polega na tym, że poprzednio na jednym routerze konfigurowaliśmy tylko jeden protokół routingu. Tym razem na R9 musimy skonfigurować aż dwa protokoły: EIGRP i RIP. Poprawną konfigurację zobaczysz na poniższym screenie:
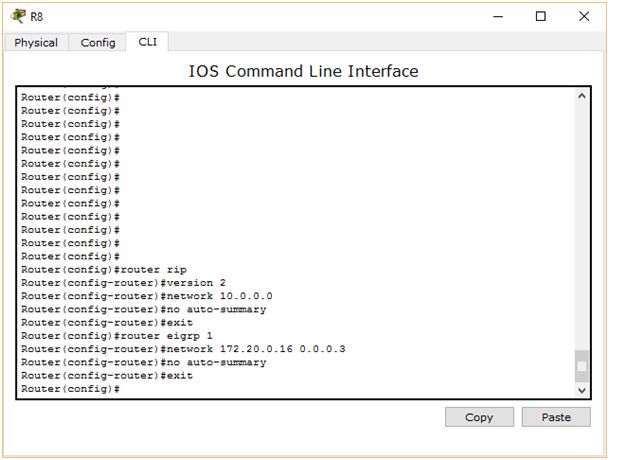
Tym sposobem zarówno z sieci 10.0.0.0/30 jak i 172.20.0.0/30 powinniśmy móc dogadać się z routerem R9. To jednak nie wszystko. R9 dalej nie wie, jak ma „łączyć” ze sobą te dwie sieci. Musimy mu o tym powiedzieć za pomocą nowego polecenia. Tą komendą jest redistribute.
Przejdźmy najpierw do trybu konfiguracji protokołu RIP. Jako pierwszy argument tego polecenia podajemy rodzaj protokołu, którego pakiety chcemy „przerobić” na RIP. Kolejnymi będą numer systemu autonomicznego i metryka. Po co metryka? A no dlatego, gdyż RIP całkowicie inaczej liczy „jakość trasy” niż EIGRP. Router samodzielnie nie przerobi sobie metryki EIGRP na RIP. Musimy sami mu podać, jak ma ją rozumieć. Wydajmy więc następujące polecenie:
redistribute eigrp 1 metric 2
Ostatni parametr (2) oznacza, że potrzeba dwóch skoków do osiągnięcia tej sieci z poziomu routera R9.
Teraz wykonujemy identyczne czynności w konfiguracji protokołu EIGRP. Tym razem, jako protokół, który chcemy „redystrybuować” podajemy oczywiście RIP. Metrykę musimy zapisać w formacie protokołu EIGRP. Przykładowo:
redistribute rip metric 1000000000 255 1 1500
oznacza, że połączenie ma przepustowość 1000000000 kbit/s, jest w 100% dostępne (255) i minimalnie obciążone a MTU (będziemy o tym mówić później) wynosi 1500. Po tej czynności powinniśmy móc bez problemu wysłać pakiet ICMP z komputera PC2 do komputera np.: PC1. Gotowa topologia z pełną konfiguracją jest dostępna do pobrania tutaj. (plik: zad2_skoncz.pkt).
Co w następnej części?
W następnej części odejdziemy trochę od protokołów routingu. Zajmiemy się głównie urządzeniami znajdującymi się w kategorii „End Devices” – czyli serwerami, laptopami itd. Poznamy usługi takie jak HTTP, DHCP, DNS czy SYSLOG. Zajmiemy się także dotychczas nieużywanymi aplikacjami dostępnymi w „systemie operacyjnym” dostępnym na komputerach w PT.


![Mobilny czytnik, który mógłby zostać smartfonem. Onyx Boox Palma [Recenzja]](https://v.wpimg.pl/YzA5Yi5qdhsgVy9aGgp7DmMPewBcU3VYNBdjSxpAa0JxTXYdUBIxVDZFOg1bXykWblw0DhpAP05xVmBaV1xhGCMBdF1QEzpXIAJoCBhCbU54AWlfBxJpQyMbMxlSUyQ)
![Średnio przemyślany symulator hotelu dla zwierząt. Pets Hotel [Playtest]](https://v.wpimg.pl/NmFlZS5qYQwnDixgGgpsGWRWeDpcU2JPM05gcRpAfFV2FHUnUBImQzEcOTdbXz4BaQU3NBpELQ52CWliBlx3D34Od2cHRX5Afw5qMhgVLw5wX2hrV0cvCCNCMCNSUzM)