

Porównanie wydajności porównywania ID różnych typów danych.
Od dłuższego już czasu męczyło mnie o ile wydajniejsze jest wykonywanie operacji join w zależności od typu danych jaki jest do tworzenia ID w kolumnie. Ostatnio widziałem także podobne pytanie na forum i postanowiłem się wreszcie temu przyjrzeć.
Testy wykonam na SQL Server 2012 Express. Porównam trzy typy danych:
- Integer - typ liczb całkowitych, zalecany przez Microsoft, jego wielkość to 4 bajty (32 bity)
- Nvarchar - typ ciągu znaków, jego wielkość jest zależna od ilości znaków.
- Uniqueidentifier - typ przechowujący unikalne identyfikatory niepowtarzalne w skali globu, jego wielkość to 16 bajtów (128 bitów)

Porównuję te typy, ponieważ spotykam się z nimi w życiu i chciałem wiedzieć jaka jest rzeczywista różnica.
Do porównania wykorzystałem tabele o wielkości 1 000 000 wierszy, aby serwer miał co robić. Na tabelach są założone indeksy aby test wykonać w warunkach zbliżonych do rzeczywistych zastosowań.
Jeśli ktoś chce przeprowadzić testy u siebie to poniżej jest do pobrania skrypt.
No i sam wynik.
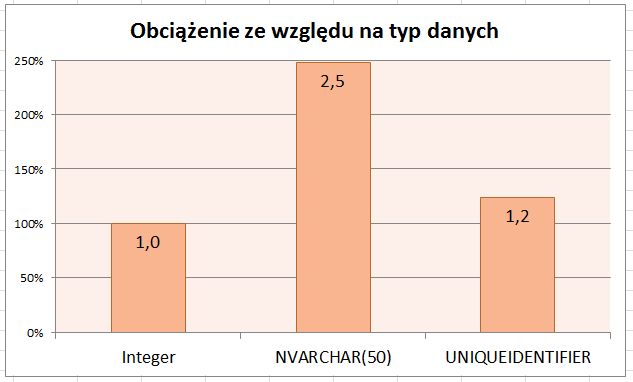
Wnioski
Jak widać najwydajniejszy okazał się być Integer, zgodnie z zaleceniami Microsoftu. Jeśli jednak z jakiegoś powodu chcemy aby każde ID było unikalne w skali nie tylko bazy ale także wielu baz to najlepiej jest stosować Uniqueidentifier, który jest nieco wolniejszy od Integera, ale znacznie szybszy od Nvarchar-a przechowującego Uniqueidentifier.
Więcej rozpisywać się nie będę bo nie ma o czym. Mam nadzieję że uzyskane informacje okażą się dla was przydatne i będziecie dobierać właściwe typy danych projektując jakąś bazę danych.



![Mroczna Rewolucja i Taktyczna Walka w Świecie Roguelite. Liberté [Recenzja]](https://v.wpimg.pl/OThlLnBuYDUJDjpdbQ5tIEpWbgcrV2N2HU52TG1AdmMQX31YbQEqNwBCOx4hESF6GABjBy8SYGddD34IcREpeV9ZdV9vQS02X0EuXnJFYjJdXC1XIRd8NlFUKUAyGyh2FQ)

![Wytrzymały i szybki dysk SSD z USB-C. ADATA SC740 (2TB)[Recenzja]](https://v.wpimg.pl/ODRkLmpwYCUzCTpeXwxtMHBRbgQZVWNmJ0l2T19CdnMqWH1bXwMqJzpFOx0TEyFqIgdjBB0QYHI0WXpYFBYqaWBYe1tdQyknYUYtCBFBYndhXXxbQBQsfGpfKEMaByhmLw)

