

Packet Tracer 6.2. — od zera do sieci tworzenia — cz 5.2. — UDP i ICMP
Wracamy do Packet Tracera. Od ostatniej części minął dość spory szmat czasu, więc teraz musimy to nadrobić ?. Ostatnio zajmowaliśmy się jednym z protokołów warstwy transportowej – Transmission Control Protocol. Protokół TCP jest dosyć skomplikowany – używany w chwilach, kiedy ważne jest nie tylko nawiązanie i utrzymanie połączenia między dwoma komputerami, ale także gwarancja dostarczenia pakietu. W TCP, nawet jeśli pakiet został podzielony na segmenty, to te muszą dojść do adresata w odpowiedniej kolejności. Dba o to nie programista aplikacji, ale właśnie protokół TCP. Transmission Control Protocol zwykle jest niezastąpiony, ale nie w każdym zadaniu sprawuje się równie dobrze. Do niektórych zadań muszą zostać wybrane inne protokoły. Dzisiaj poznamy kolejny protokół warstwy transportowej – UDP. Zobaczymy także, co dzieje się na niższych warstwach.
TCP nie nadaje się do wszystkich zadań. Załóżmy np.: że oglądamy jakiś stream na żywo. Gdzieś na trasie pakietu pomiędzy nami a serwerem streamingu wystąpiło zakłócenie, które spowodowało uszkodzenie jednej z przesyłanych klatek filmu. Co by się stało, gdyby tę transmisję obsługiwał TCP? Klient odesłałby do serwera informację o tym, że klatka filmu została uszkodzona. Musielibyśmy czekać na odpowiedź serwera i przesłanie jeszcze raz tej samej klatki filmu. Kręcące się kółko, oznajmujące proces ładowania filmu mogłoby nas w końcu doprowadzić do stanu szewskiej pasji.
Zadajmy sobie pytanie, czy naprawdę strata tej jednej klatki z 60 FPS‑owego filmu byłaby taka straszna? Ludzkie oko nawet by jej nie zauważyło. Właśnie w takich wypadkach stosuje się bezpołączeniowy protokół UDP.
UDP – User Datagram Protocol
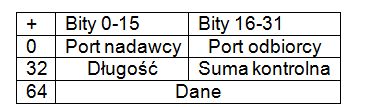
Spójrzmy na nagłówek protokołu UDP. Już na pierwszy rzut oka widzimy, że jest on o wiele prostszy od TCP. Zawiera tylko cztery pola, z czego dwa są nieobowiązkowe.

Pola port nadawcy i port odbiorcy występowały już w protokole TCP. Port nadawcy informuje, z którego portu (z której aplikacji) została wysłana wiadomość. Informacja z tego pola będzie wykorzystywana wtedy, gdy odbiorca pakietu będzie chciał nadać informację zwrotną do nadawcy. Gdy nie istnieje taka konieczność, pole może zostać wypełnione wartością zero.
Pole port odbiorcy musi być wypełnione. Bez tego nie byłoby wiadomo, która aplikacja po stronie odbiorcy ma zająć się obsługą pakietu.
Pole długość jest 16 bitowe. Informuje o długości całego datagramu – liczymy zarówno nagłówek jak i dane. Minimalna długość datagramu UDP to 8 bajtów i jest to długość nagłówka. Skoro pole jest 16 bitowe, to bardzo łatwo możemy ustalić największą możliwą długość datagramu UDP – i jest to 65527 bajtów.
Suma kontrolna jest ostatnim polem nagłówka. Nie jest ona obowiązkowa. Zresztą, nawet jeśli suma kontrolna zostanie umieszczona, to sprawdza ona jedynie poprawność przesyłu nagłówka. Na podstawie sumy kontrolnej z nagłówka UDP nie możemy ustalić, czy znajdujące się w treści datagramu dane nie uległy uszkodzeniu. Suma kontrolna jest obliczana tutaj tą samą metodą, którą stosuje się przy protokole TCP, tyle tylko, że nie bierzemy pod uwagę danych przesyłanych przez datagram.
Warto wyjaśnić jeszcze jedną rzecz. Protokół UDP jest protokołem bezpołączeniowym. Co to oznacza? Używając protokołu TCP, jak dobrze wiemy z poprzedniego artykułu, odbiorca nawiązuje z serwerem połączenie („sesję”) w ramach której wymieniają się danymi. Połączenie to gwarantuje dotarcie nieuszkodzonych pakietów w odpowiedniej kolejności. Po zakończeniu wymiany danych jedna ze stron powinna zakończyć połączenie. Rozwiązanie ma pewną wadę. W zależności od architektury i różnych czynników, aplikacja nie może nawiązać nieograniczonej liczby połączeń TCP. Zresztą, jak już wcześniej mówiliśmy, TCP jest nieco wolniejsze od UDP. W przypadku UDP, nie jest nawiązywane żadne połączenie. Serwer po prostu oczekuje na odbiór danych na danym porcie (operacja ta nazywa się bindowaniem portu). Gdy dane otrzyma, przetwarza je. Jeśli w nagłówku UDP nie była zawarta informacja o porcie nadawcy, odbiorca nawet nie może odpowiedzieć, gdyż nie wie, gdzie ten pakiet miałby wysłać.
Przykład transmisji po protokole UDP – DNS
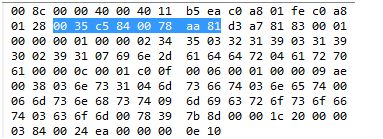
Protokołu UDP używa wiele aplikacji. Jedną z nich jest system nazw DNS, którym zajmiemy się w przyszłości. Na niebiesko zaznaczony jest nagłówek datagramu UDP. Odczytanie portu źródłowego, docelowego, długości i sumy kontrolnej pozostawiam jako proste ćwiczenie dla czytelnika.
TCP vs UDP
Zamykamy temat warstwy transportowej. Na koniec krótki filmik, który w zabawny sposób podsumowuje różnice między TCP i UDP. [youtube=https://www.youtube.com/watch?v=KSJu5FqwEMM]
Przechodzimy na warstwę niżej - IP
Omówiliśmy już najczęściej wykorzystywane we współczesnym Internecie protokoły warstwy transportowej – TCP i UDP. Jednakże, przed pakietem, który znajduje się na tym etapie podróży jeszcze daleka droga. Swoje kilka groszy musi dołożyć protokół IP. We wcześniejszych częściach kursu wspominaliśmy o czymś takim jak adresy IP. Adres IP jest adresem logicznym, który identyfikuje dane urządzenie w sieci. Adresy IP – źródłowy i docelowy są dołączane do pakietu w warstwie sieciowej modelu OSI. Odpowiada za to Internet Protocol – IP.
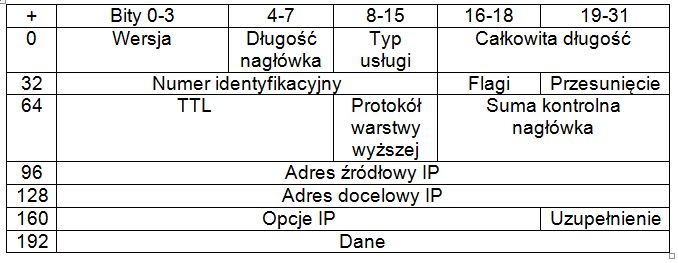
Omówmy po kolei poszczególne pola nagłówka IP.
[list] [item]Wersja – sama nazwa tego pola mówi, co ono określa. Pole to zawsze przyjmuje wartość 4 dla protokołu IPv4, oraz wartość 6 dla IPv6.[/item][item]Długość nagłówka – pole to zajmuje tylko 4 bity. Czy to oznacza, że nagłówek IP może mieć długość jedynie 16 bitów? Nie! W tym miejscu określamy, ile 4 bajtowych części znajduje się w nagłówku. Np.: jeśli nagłówek będzie miał długość 48 bajtów, to pole to będzie zawierało cyfrę 12.[/item][item]Typ usługi – teoretycznie określa „priorytet” pakietu, aczkolwiek pole to najczęściej nie jest wykorzystywane, toteż nie będziemy się nim zajmować.[/item][item]Całkowita długość – określa długość nagłówka IP wraz z danymi[/item][item]Identyfikator – pole wykorzystywane wtedy, gdy fragmentacja występuje na poziomie warstwy sieci. [/item][item]Flagi – pole dwubitowe. Pierwszy bit określa, czy dane można fragmentować, czy nie. Natomiast drugi mówi nam o tym, czy dany pakiet składa się z większej ilości datagramów.[/item] [item]Przesunięcie – wykorzystywane wtedy, kiedy pakiet jest pofragmentowany. Pole przesunięcie mówi nam o tym, w którym miejscu pakietu należy wstawić bieżący datagram, aby otrzymać prawidłowe dane[/item][item]TTL – czas życia pakietu. Parametr ten określa, ile razy pakiet może być przesłany pomiędzy routerami, zanim dotrze do miejsca docelowego. Aby łatwiej zrozumieć te pole, popatrzmy na następujący przykład. Załóżmy, że pakiet zostaje wysłany przez serwer i ma wartość TTL równą 5. Pierwszy router na trasie, który odbiera pakiet, przesyła go dalej, zmniejszając TTL do 4. Kolejny router zmniejsza TTL do 3 itd., do momentu, gdy nie dotrze do miejsca docelowego. Jeśli pakiet ma TTL równe 0 i dalej błąka się po sieci, nie jest już przesyłany dalej. Zwykle wartość TTL wynosi od 32 przeskoków do 128. [/item][item]Protokół warstwy wyższej – jak sama nazwa mówi, pole to określa jaki protokół był używany w warstwie wyższej. Najczęściej pole to przyjmuje wartość (w DEC) 17 (UDP), 6 (TCP) lub 1 (ICMP).[/item][item]Suma kontrolna nagłówka – zabezpiecza nagłówek przed uszkodzeniem. Zasada obliczania sumy kontrolnej nagłówka jest taka sama jak w przypadku protokołu TCP czy UDP[/item][item]Adres źródłowy IP, adres docelowy IP – jak sama nazwa mówi, pola te przechowują adres nadawcy i odbiorcy pakietu[/item][item]Opcje IP – przechowuje dodatkowe opcje protokołu IPv4. Pole bardzo rzadko wykorzystywane[/item][item]Uzupełnienie – to opcjonalne pole dba o to, aby wielkość pakietu była wielokrotnością liczby 32.[/item]
ICMP – co nieco o analizie działania sieci
Znasz pewnie polecenie takie jak ping – obsługiwane przez każdy system operacyjny. Służy ono do sprawdzenia, czy między naszym urządzeniem a stacją docelową istnieje połączenie. Innym często używanym do diagnozowania problemów z siecią poleceniem jest tracert/traceroute. Tracert służy do sprawdzenia, przez jakie routery musi przejść pakiet, zanim dotrze do miejsca przeznaczenia. Oba programy korzystają z bardzo prostego protokołu ICMP.

Dwa pierwsze pola – Typ i kod – oznaczają rodzaj i „podrodzaj” zdarzenia. Suma kontrolna dba o to, aby pakiet ICMP nie został uszkodzony. Dane to pole opcjonalne. Pole to może zawierać np.: fragment uszkodzonego nagłówka IPv4 lub fragment pakietu, który spowodował błąd. Pełną listę typów i subtypów pakietów ICMP można znaleźć na stronie IETF w dokumencie RFC792.
Ping korzysta wyłącznie z protokołu ICMP. Tracert natomiast wykorzystuje także cechy nagłówka IP. W jaki sposób? Załóżmy, że w cmd wpisujemy następujące polecenie:
tracert www.dobreprogramy.pl
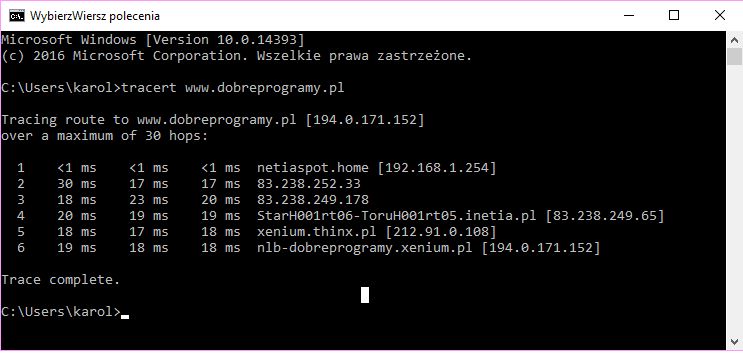
W tym momencie wysyłany jest zwykły pakiet ICMP do serwera dobreprogramy.pl. Jednakże, w nagłówku protokołu IP wprowadzamy pewną zmianę w polu TTL. Jeśli chcemy poznać pierwszy router, przez który przechodzi pakiet, pole TTL ustawiamy na 1. Gdy pakiet dotrze do pierwszego routera z trasy, ten ustawi TTL na 0 i odeśle do nas informacje o tym, że pakietowi skończył się „czas życia”. W tym momencie znamy już pierwszy router. Teraz wysyłamy taki sam pakiet, tylko że ustawiamy pole TTL na 2. Pierwszy router zmniejszy TTL do 1, ale prześle pakiet dalej. Natomiast drugi zmniejszy TTL na 0 i podobnie jak wcześniej, wyśle do nas informacje o tym, że nie może przesłać pakietu dalej. Tym sposobem możemy poznać adres IP każdego z routerów znajdujących się na trasie od nas do miejsca docelowego.
I jeszcze jeden schodek w dół
Omówiliśmy już protokoły warstwy sieciowej. Została nam jeszcze jedna warstwa – warstwa łącza danych. W tym miejscu pakiety czy segmenty danych stają się ramkami. Do każdej z nich dołączany jest adres MAC nadawcy i odbiorcy, a także informacja o tym, jaki protokół znajduje się w warstwie wyższej.
To już koniec wędrówki danych w naszym komputerze. Warstwa łącza danych przekazuje ramki do karty sieciowej, która zamienia je na ciąg zer i jedynek. Gdy pakiet dotrze do urządzenia docelowego, warstwa po warstwie – od najniższej do najwyższej – poszczególne nagłówki są usuwane. Dane trafiają do odpowiedniej aplikacji, która może zająć się ich przetwarzaniem.
Co dalej?
To już wszystko. Powinniśmy znać już zasady działania najczęściej wykorzystywanych protokołów sieciowych poszczególnych warstw modelu OSI. Dzięki temu wiemy, jak długą i wyboistą drogę muszą przebyć dane np.: z przeglądarki internetowej, zanim zostaną wysłane do serwera WWW. W następnej części zajmiemy się protokołami warstwy aplikacji i ich implementacją w Packet Tracerze. Dowiemy się między innymi, jak działa system DNS. Dowiemy się także, w jaki sposób komputer otrzymuje adres od serwera DHCP. Poznamy zasadę działania serwera WWW czy poczty email.


![Mobilny czytnik, który mógłby zostać smartfonem. Onyx Boox Palma [Recenzja]](https://v.wpimg.pl/MDliLmpwYiUNCzpeXwxvME5TbgQZVWFmGUt2T19CdHMUWn1bXwMoJwRHOx0TEyNqHAVjBB0QYnUKXXwOSUQvaVQLLlldQygmD0QtWkEWYHdYXXVZQEF_J1xQLkMaBypmEQ)
![Średnio przemyślany symulator hotelu dla zwierząt. Pets Hotel [Playtest]](https://v.wpimg.pl/YWVlLmpwdjY3DjpeXwx7I3RWbgQZVXV1I052T19CYGAuX31bXwM8ND5COx0TEzd5JgBjBB0QdmI1D3wIQ0Zqem8OdA9dQ2tjZkF1D0AWdDM3D3peQk87YTcJKUMaBz51Kw)


![Klimatyczny świat klubowego bramkarza. Techno Banter [Recenzja]](https://v.wpimg.pl/NDc4LmpwYSUCVjpeXwxsMEEObgQZVWJmFhZ2T19Cd3MbB31bXwMrJwsaOx0TEyBqE1hjBB0QYSVUA3sOQRIvaVMMKF1dQ3wlAhkuWxNFYyIGAylcEkB4dFcDdEMaBylmHg)
