

Czkawka – Szybki i wydajny program do porządkowania danych/zdjęć
Wraz z ostatnim wydaniem wersji 1.4.0 mojego programu do czyszczenia systemu - Czkawka, postanowiłem nieco opisać tą aplikację.
Dostępny jest na systemy Linux(GUI, CLI), Windows(GUI), Mac(CLI), można go pobrać tutaj(binarki Windowsa ze skanem Virustotal) - https://github.com/qarmin/czkawka/releases
Na Linuxie instalację można przeprowadzić instalację poleceniem

cargo install czkawka_gui
Lecz należy zainstalować wcześniej wymagane biblioteki GTK(3.22+) oraz cargo
Ubuntu/Debian
sudo apt install libgtk3-dev cargo
Fedora:
sudo yum install gtk3-devel glib2-devel cargo
W najnowszej wersji głównymi zmianami było poprawienie wyszukiwania i wyświetlania podobnych obrazów oraz przede wszystkim dodanie wsparcia dla wielowątkowości co przyniosło na moim komputerze przyspieszenie wyszukiwania od 100% nawet do 500%(głównie w CLI).
Istniejące oprogramowanie
FSlint - świetne narzędzie, z którego do niedawna dość często korzystałem. Funkcjonalność napisana jest w Bashu i korzysta tam gdzie można z wbudowanych w system funkcjonalności(np. md5sum) a GUI jest napisane w niewspieranym już Pythonie 2 oraz korzysta z PyGTK 2 co spowodowało, że nie jest już dostępny w repozytoriach Ubuntu 20.04. Niestety już od dawna nie otrzymuje prawie wcale zmian ani ulepszeń. Jest dostępny wyłącznie na Linuxie, przez co zawiera szereg funkcjonalności unikalnych dla tego systemu.
DupeGuru - Napisane w Pythonie narzędzie, popularne ze względu na duże możliwości konfiguracji. Posiada wyszukiwanie duplikatów względem ich zawartości, podobnych obrazów czy plików muzycznych z identycznymi tagami. Używa więcej pamięci Ram niż FSlint i nie posiada aż tylu funkcjonalności, jednak jest dostępny na Windowsie, Linuxie oraz MacOS.
Braki tych dwóch narzędzi spowodowały, że zapragnąłem stworzyć nowe wielofunkcyjne narzędzie, które będzie oferowało podobną albo nawet i większą wydajność jak i użyteczność.
Czkawka wyglądem przypomina FSLint, ponieważ bardzo podobała mi się prostota jego interfejsu.
Język
Jedną z ważniejszych rzeczy, o których trzeba wcześniej pomyśleć jest wybranie języka programowania w którym będzie się tworzyło aplikację.

Z racji tego, że aplikacja będzie umożliwiała odczytywanie tysięcy lub nawet milionów rekordów/plików to użycie języka niskiego poziomu powinno znacząco ograniczyć zużycie zasobów systemowych i zmniejszyć czas na wykonanie danego zadania. Dlatego pierwszym pomysłem było wykorzystane języka C++, z którym miałem już wcześniej do czynienia jednak konieczność stałego korzystania z Valgrinda, Address, Undefined czy Leak Sanitizers skierowały mnie na język Rust w którym jedynie do tej pory tylko przepisałem i skompilowałem przykład Hello World z dokumentacji, co jednak uznałem jako dobry powód na jego naukę.

Ważnym również było wybranie frameworka dla interfejsu graficznego aplikacji. Z racji popularności i dobrego połączenia z językiem Rust, postanowiłem wybrać GTK, ponieważ mogłem stworzyć program bazujący na pliku Glade z FSlint. Niestety podczas wyboru frameworka musiałem odrzucić wszystkie te korzystające wyłącznie z Rusta, ponieważ nie posiadały wystarczająco wiele funkcjonalności do zbudowania GUI dla tego projektu, jednak ciągle szukam możliwości użycia natywnego Orbtk w swoim projekcie.
Przy jego pomocy prawie całkowicie porzuciłem Valgrinda, który jednak od czasu do czasu używam z uwagi na używanie GTK, który jak wiadomo jest napisany w C i jest pełen niezdefiniowanego zachowania gdy używa się go niepoprawnie.
Przegląd Dostępnych narzędzi
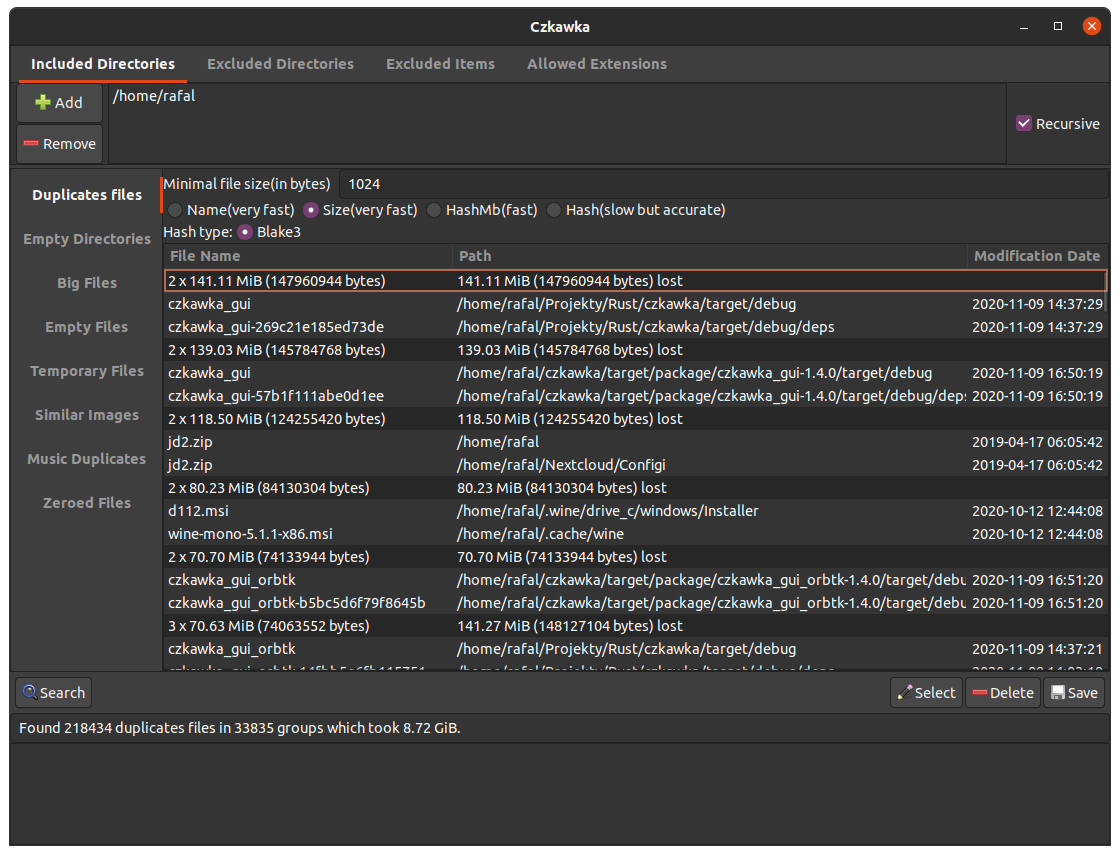
Duplikaty
Najbardziej podstawowe narzędzie, umożliwia grupowanie plików o podanych parametrach, tak aby łatwo można je przeglądać, zaznaczać i usuwać.
Lista dostępnych parametrów wyszukiwania - Po nazwie - pliki są grupowane ze względu na nazwę(musi być identyczna, bez żadnych wariacji). Bardzo szybki, lecz użyteczny wyłącznie w niewielu sytuacjach.
- Po rozmiarze - najpierw sprawdzane są rozmiary plików i według nich wyznaczane jest czy dany plik ma duplikaty
- Po hashu - składa się z trzech części. Pierwsza wykonuje sprawdzanie rozmiarem i po jego zakończeniu usuwa pliki o unikalnej wielkości, ponieważ nie ma potrzeby ich hashować skoro i tak wiadomo, że są inne od reszty. Następnie przechodzi do hashowania początkowych 2KB każdego z plików, tak aby bez wielkiej straty czasu wyrzucić ze sprawdzania pliki, które mają inny początek pliku, na zakończenie jest sprawdzany hash całego pliku aby być pewnym, że np. pliki nie różnią się tylko ostatnim znakiem. Jest to domyślny i najbardziej wiarygodny test do sprawdzania duplikatów.
- Po częściowym hashu - działa identycznie jak tryb hashowania, lecz na końcu nie sprawdza całego pliku, tylko maksymalnie 1MB danego pliku. Nie jest aż tak pewny jak powyższy tryb, lecz zwykle powinien wystarczyć, zwłaszcza jeśli wystarczą nam przybliżone wyniki.
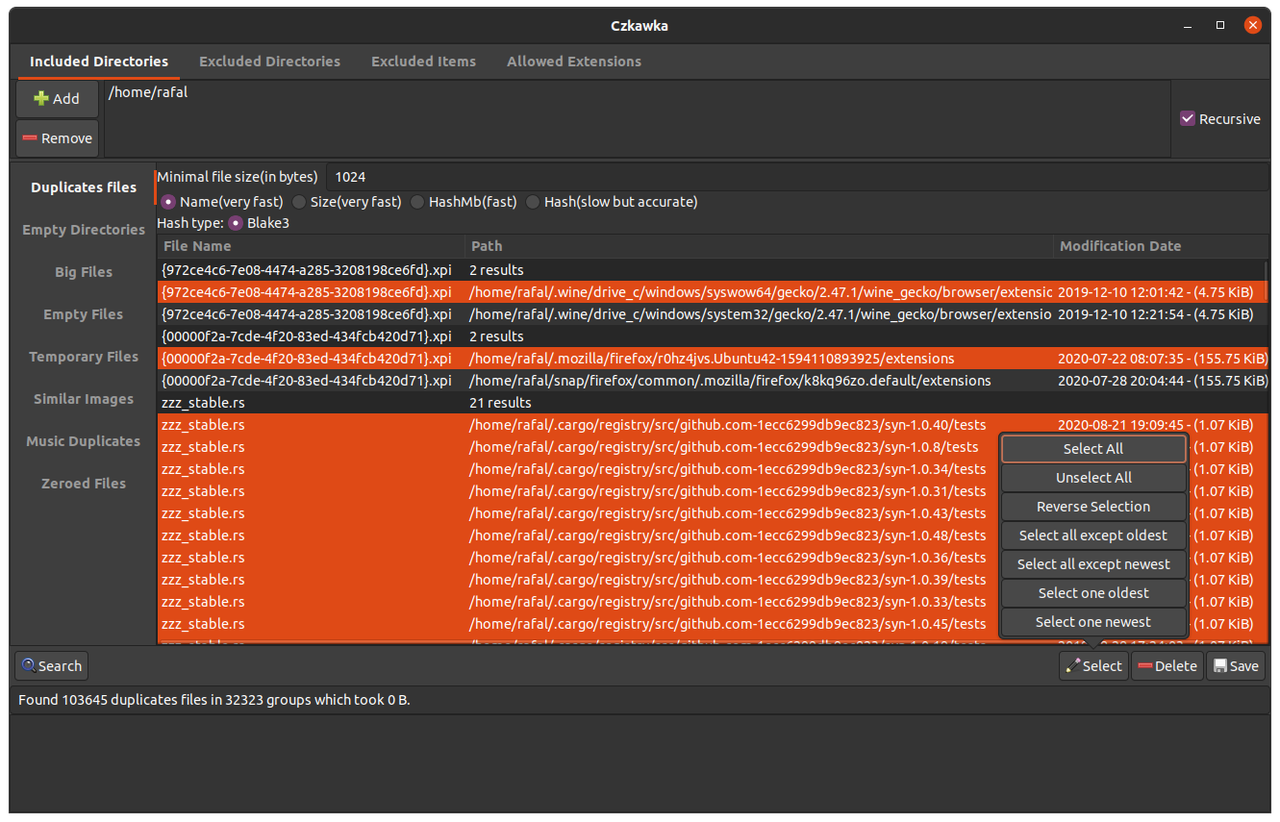
Duże pliki
Pozwala na wyświetlenie podanej ilości największych plików w określonej lokacji(domyślnie 50)
Puste Pliki
Wyszukuje pliki o długości równej 0
Puste foldery
Znajduje foldery które nie mają wewnątrz siebie innych folderów i plików oraz takie, które posiadają tylko i wyłącznie puste foldery
Wyzerowane pliki
Wyszukuje pliki, które mają składają się wewnątrz całkowicie tylko z zer. Mogą to być np. produkty nieprawidłowego kopiowania czy pobierania plików. Najpierw sprawdza pierwsze 64 bajty pliku, tak aby już na tym kroku odrzucić większość plików, a następnie w pętli są sprawdzane 32 KB części plików.
Muzyka
Możliwe jest również wyszukanie plików muzycznych, które będą grupowane według wybranego przez nas kryterium, które możemy dowolnie łączyć - wykonawcę utworu, tytuł utworu, rok, wykonawcę albumu czy tytuł albumu. Chętnie dodałbym również wyszukiwanie po długości utworu, ale to akurat jest zależne od zewnętrznej biblioteki - https://crates.io/crates/audiotags.
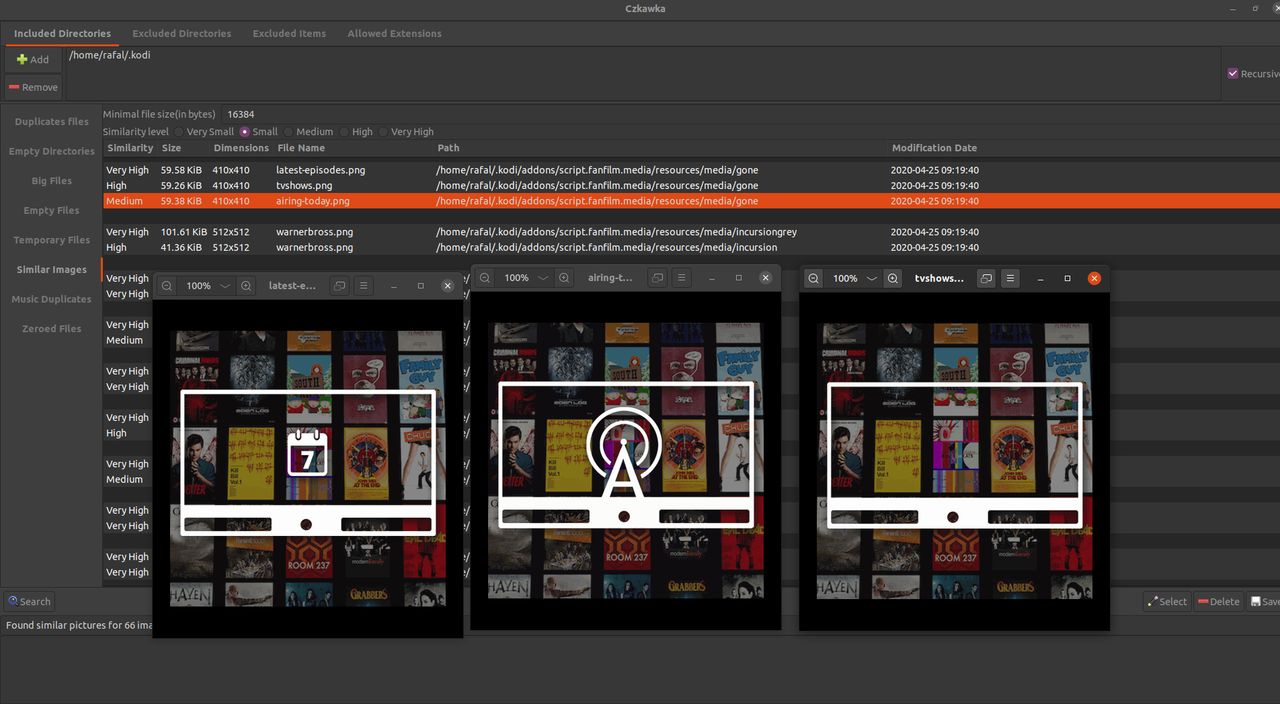
Podobne obrazy
Tutaj Czkawka dla każdego obrazu(póki co jpg i png) tworzy hash perceptualny, który dla podobnych obrazów nie różni się zbytnio. Jest on następnie porównywany z każdym innym hashem i jeśli odległość między nimi jest niewielka, to obraz jest uznawany jako podobny(np. AAABB jest podobne do ABABA ale nie do ZFTWQ). Można określać różną wielkość podobieństwa, tak aby znajdywać nieco mniej podobne obrazy.
Wydajność
Celem sprawdzenia który z programów oferuje największą wydajność, przetestowałem je na moim systemie z dyskiem SSD CX400 oraz procesorem i7 4770(4/8)
Duplikaty
Testowany był osobny dysk z 229868 plikami które zajmowały 203,7GB w których było 13708 duplikatów w 9117 grupach zajmujących 7.9 GB. Minimalna wielkość pliku wynosiła wszędzie 1KB.
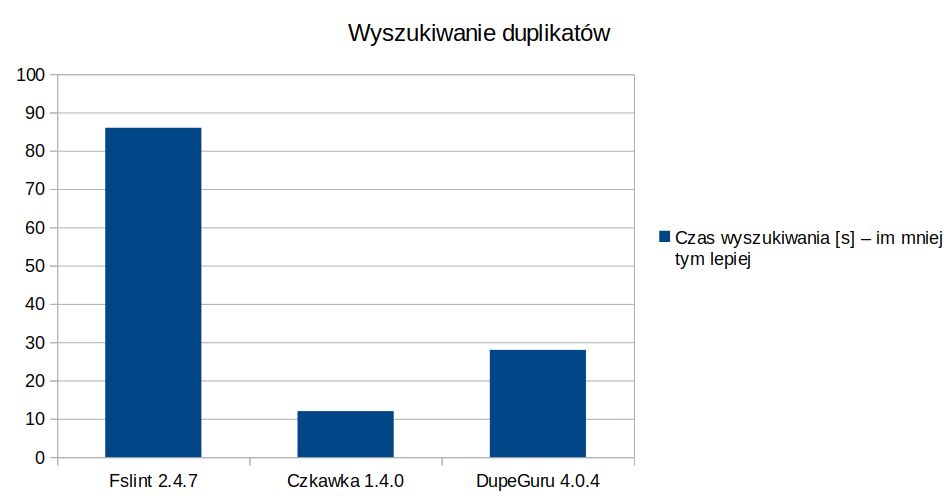
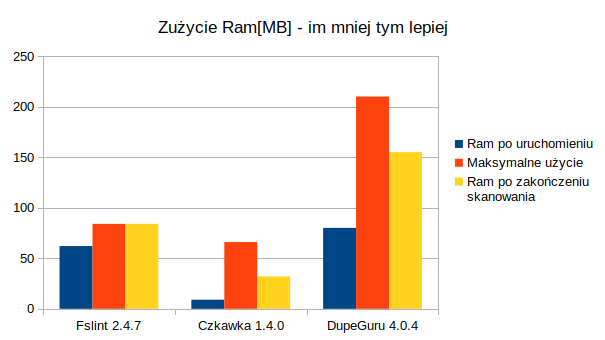
Zużycie Ram
Zużycie Ram przez DupeGuru i FSlint sprawdziłem programem mprof, a Czkawkę - Heaptrack.
Podobne obrazy
Użyłem w DupeGuru ustawień domyślnych a w Czkawkce ustawienia High
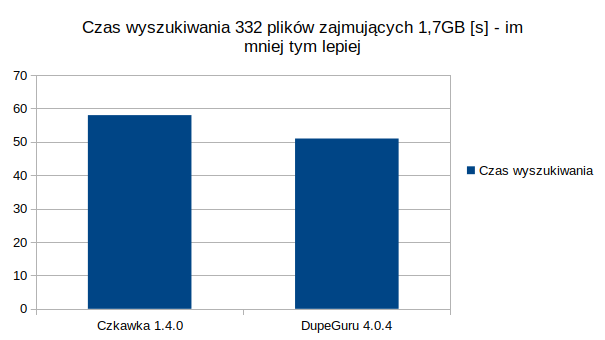
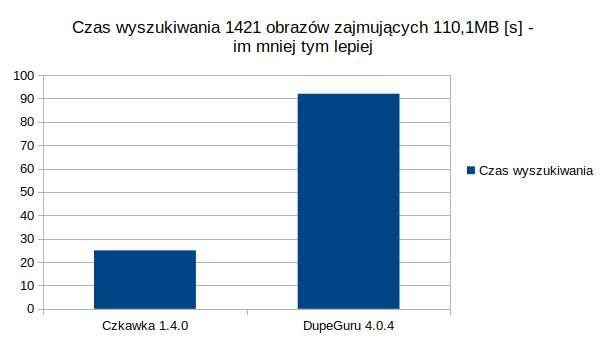
Jak widać ku mojemu zdziwieniu, nawet użycie wielu wątków w wyszukiwaniu dużych plików, nie pomogło pokonać DupeGuru w wyszukiwaniu dużych plików. Muszę przeszukać jego kod źródłowy, aby znaleźć jakiego konkretnie algorytmu używa i go użyć w Czkawce tak by i tutaj była ona szybsza.
Wsparcie
Z racji tego, że program tworzę w większości sam i nie narzekam na zbyt dużą ilość wolnego czasu, to przydałaby mi się pomoc w niektórych elementach tj.: - Wsparcie dla GUI GTK w systemie Mac - niestety bez posiadania maca jest to prawie niemożliwe, jednak ważne by dało się to włożyć do CI Githuba(ma dedykowany wirtualny systemy Mac, ale wolałbym coś z cross-kompilacji). - Wyczyszczenie kodu - jako, że to mój pierwszy projekt w Rust, to pewnie wiele rzeczy jest zrobione w dość pokrętny sposób, który można by poprawić/ulepszyć/uprościć. - Stworzenie paczki Snap i Flatpak - Appimage już mam zaimplementowany, lecz automatyczne aktualizacje niestety nie są w nim możliwe. - Dodanie systemu tłumaczeń z plików PO - Dodanie do repozytorium Debiana
Dlatego jeśli możecie, to byłbym wdzięczny za pomoc
Zakończenie
Mimo, że program na tę chwilę oferuje już większość wymaganych przeze mnie funkcji, to ciągle planuję jego dalszy rozwój i póki co będę się skupiał na: - Dodaniu zmiany plików na hardlinki zamiast ich usuwania - Przyspieszeniu wyszukiwania podobnych zdjęć - Dodaniu obsługi większej ilości hashy - Dodaniu miniatur do podobnych obrazów
Repozytorium aplikacji - https://github.com/qarmin/czkawka
![Klawiatura do zastosowań gamingowych. Logitech G Pro X TKL [Recenzja]](https://v.wpimg.pl/MzU5LmpwYhs0VzpeXwxvDncPbgQZVWFYIBd2T19CdE0tBn1bXwMoGT0bOx0TEyNUJVljBB0QYk1gUHsMSBJ6V2NRfl9dQylIbBgtXhUSYBhiBX4IFBIvHGYAdUMaBypYKA)
![Wieloportowa ładowarka sieciowa. Zestaw Natec Ribera Gan i Prati [Test]](https://v.wpimg.pl/MGI4LmpwYiYoVjpeXwxvM2sObgQZVWFlPBZ2T19CdHAxB31bXwMoJCEaOx0TEyNpOVhjBB0QYnAoB38MFhIsaigMKQtdQ3okKxl1XURHYHJ_A3VeE05_c3lWdEMaByplNA)
![Kompaktowy projektor ze wbudowanym Google TV. ViewSonic LX60HD [Recenzja]](https://v.wpimg.pl/Y2M0LmpwdlMsUjpeXwx7Rm8KbgQZVXUQOBJ2T19CYAU1A31bXwM8USUeOx0TEzccPVxjBB0QdlN6A3hVQEZvHyxUfVpdQ2pWeh11CRUUdAJ7Ai0OQEI7BS5TeEMaBz4QMA)
![Bezprzewodowa myszka dla fanatyków minimalizmu. Logitech Pop Mouse [Recenzja]](https://v.wpimg.pl/YjM4LmpwdgssVjpeXwx7Hm8ObgQZVXVIOBZ2T19CYF01B31bXwM8CSUaOx0TEzdEPVhjBB0Qdg95AXkPRUZqRyhVL1pdQz1YfBktXkNPdFp9Bi0MFkBvXC8HdEMaBz5IMA)
![Kalibracja kolorów monitora w trzech krokach. Calibrite Display 123 [Recenzja]](https://v.wpimg.pl/M2I4LmpwYlMoVjpeXwxvRmsObgQZVWEQPBZ2T19CdAUxB31bXwMoUSEaOx0TEyMcOVhjBB0QYlNxBigIQk4sHytWdQtdQ38DeBl1XklDYAF_DHkMQkZ6C3pWdEMaByoQNA)
![Szybki i kompaktowy dysk SSD na USB-C. ADATA SC750 (2 TB) [Recenzja]](https://v.wpimg.pl/OWU5LmpwYDY0VzpeXwxtI3cPbgQZVWN1IBd2T19CdmAtBn1bXwMqND0bOx0TEyF5JVljBB0QYGJgBXhdEUYsemJXdVldQ31gNxguWENAYmIzUHQJQE4rNGxQdUMaByh1KA)

