

Proxy dla laików — kompleksowa konfiguracja squid — cz.1
karolSerwer Proxy – narzędzie, które w wielu przypadkach jest bardzo przydatne. Używamy go do różnych celów. Jednym z nich jest np.: obejście blokady regionalnej na jakiejś witrynie. Filmik, który obejrzą jedynie osoby zamieszkujące w Stanach Zjednoczonych będziemy mogli bez większych problemów wyświetlić w dowolnym miejscu pobytu dzięki temu przydatnemu narzędziu. Wystarczy znaleźć serwer proxy znajdujący się w Ameryce i przez niego obejrzeć uwielbiany filmik. Serwer pośredniczący pozwala również zapewnić jaką taką anonimowość w sieci. Dlaczego? Bo łącząc się z serwerem proxy, a następnie z docelową witryną (np.: tvn24), nasze prawdziwe IP jest ukrywane. TVN24 myśli, że to serwer proxy, a nie my, połączył się z nim i np.: napisał komentarz. Nie jest to pełna anonimowość, gdyż każdy serwer pośredniczący gromadzi logi i statystyki, które mówią o tym, kto, kiedy i po co go używał.
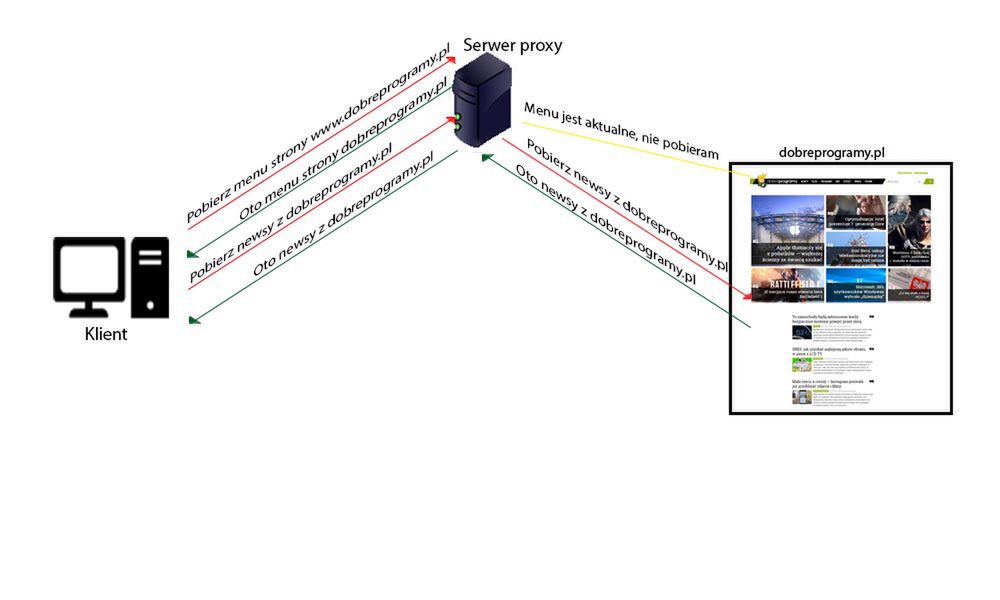
Oprócz wymienionych powyżej zadań, proxy może realizować także wiele innych. Załóżmy, że nauczyciel jakiegoś przedmiotu technicznego przeprowadza sprawdzian przy użyciu komputerów. Chce umożliwić uczniom dostęp jedynie do witryny, na której odbywa się test oraz do kilku innych, mających służyć jako pomoc naukowa. Natomiast dostęp do Facebooków i innych pudelków ma być zablokowany. Można to skonfigurować za pomocą różnych programów na poszczególnych stacjach roboczych. Takie rozwiązanie ma poważną wadę – zajmie masę czasu. Po drugie, jeśli w przyszłości chcielibyśmy zmienić zakres dostępnych stron, będziemy musieli osobno skonfigurować każdy komputer. Nie jest to zbyt przyjemna perspektywa, prawda? Serwer proxy natomiast, umożliwia nam szybką i bezproblemową konfigurację tego typu rzeczy.

Warto wspomnieć, że możliwość blokowania możemy wykorzystać także do innych celów - np.: nie ma przeszkód, aby w ten sam sposób zablokować skrypty śledzące (np.: google analytics) lub reklamy.
Istnieje jeszcze jedna, bardzo ważna zaleta tego typu aplikacji – możemy bez większych ekscesów monitorować działalność podległych nam użytkowników w Internecie. Jeśli odpowiednio skonfigurujemy stacje robocze, przeszkody nie stanowi nawet SSL. Dzięki odpowiedniemu dodatkowemu oprogramowaniu, damy radę tworzyć także dzienne, tygodniowe czy miesięczne raporty, które pozwolą dowiedzieć się, jakie witryny są najczęściej odwiedzane przez naszych użyszkodników.
Lokalny serwer pośredniczący może przydać się także w środowisku domowym. Dlaczego? Wspomnieliśmy już większość zastosowań tego typu oprogramowania, ale zapomnieliśmy o jednym z najważniejszych. Przypuśćmy, że nasze łącze nie należy do najszybszych, natomiast, niejednokrotnie łączymy się z jakąś witryną w Zimbabwe, której pobranie i wyświetlenie za każdym razem trwa wieki. Poza tym, zużywa (być może) nasz cenny transfer. Właśnie w tym miejscu z pomocą przychodzi oprogramowanie serwera pośredniczącego. Jeśli jakaś witryna jest bardzo często pobierana i nie zmienia się zbyt często, serwer proxy może ją „zbuforować”. Nasz komputer łącząc się z daną stroną internetową, nie musi pobierać jej z odległego, wolnego serwera sieci Web. Załaduje ją natomiast z lokalnego, szybkiego serwera proxy. Przy okazji, taka operacja nie zużyje transferu internetowego.
Powyższe rozważania prowadzą do następującej myśli – jak skonfigurować takie oprogramowanie? Jest to bardzo proste, o czym zaraz się przekonamy.
Kompilacja i instalacja squid
Squid jest jednym z najpotężniejszych serwerów pośredniczących dostępnych na platformę Linux. Z tego oprogramowania możemy korzystać także na alternatywnych systemach operacyjnych. Mimo dostępności, nie polecam takiego rozwiązania, gdyż Squid dla Windowsa nie jest tak dopracowany, jak jego wersja na macierzysty system operacyjny. Squid dostępny jest w postaci paczek .deb lub .rpm w większości dystrybucji. Niestety, cele, które sobie założymy wykluczą użycie prekompilowanych wersji. Dlaczego? Squid dostępne w repozytoriach w większości przypadków zawiera tylko podstawową funkcjonalność. My chcemy osiągnąć znacznie więcej, niż zwykłą optymalizację łącza internetowego. My chcemy wprowadzić kompletną kontrolę nad poczynaniami naszych użytkowników w tej ogromnej sieci, zwanej Internetem. Dlatego musimy użyć kilku specjalnych przełączników kompilacji.
Najpierw pobieramy źródła squid. Możemy pobrać starszą (najczęściej) wersję z repozytoriów lub pokusić się o najnowszą z oficjalnej witryny projektu. Na dzień dzisiejszy ostatnia wersja Squid ma numerek 3.5.19 i jest dostępna do ściągnięcia pod tym adresem.
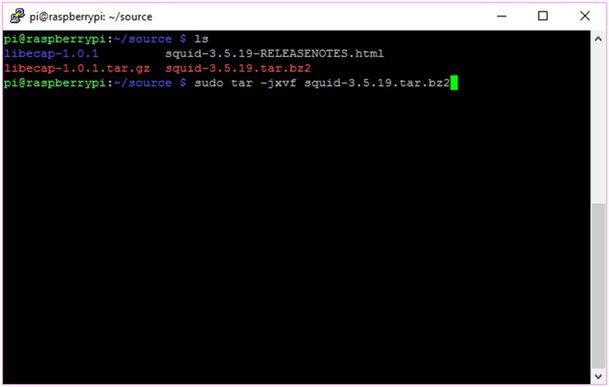
Po ściągnięciu Squid rozpakowujemy je. Robimy to poleceniem:
tar –jxvf squid-3.5.19.tar.bz2
Przełącznik j oznacza, że zajmujemy się archiwum bzip, -x – że będziemy je rozpakowywać. V Oznacza tryb verbose, który informuje nas o tym, co aktualnie się dzieje. F jako parametr występuje zawsze i oznacza, że zajmujemy się plikiem, a nie strumieniem czy innym wynalazkiem.
Ok, rozpakowaliśmy squid. Przygotujmy sobie teraz środowisko do kompilacji. Jeśli wcześniej nie robiliśmy tego typu rzeczy, musimy zainstalować kilka dodatkowych paczek. Najprościej będzie wgrać paczkę build-essential, która powiązuje ze sobą wszystkie narzędzia wykorzystywane w budowaniu i kompilacji programów. Poza tym, powinniśmy także zainstalować pakiet dpkg-dev. Dzięki temu będziemy mogli automatycznie pobrać zależności niezbędne do samodzielnej kompilacji squid. W systemach rodziny Debian możemy to zrobić za pomocą polecenia:
sudo apt-get install build-essential dpkg-dev
Ok, środowisko mamy już przygotowane. Teraz pora na pobranie niezbędnych zależności. Moglibyśmy każdy pakiet instalować ręcznie, ale po co, skoro mamy do tego odpowiednie narzędzia? Wydajmy polecenie:
sudo apt-get build-dep squid3
Pobierze ono większość (ale nie wszystkie!) zależności, które są potrzebne do poprawnej kompilacji serwera pośredniczącego SQUID. Część dodatkowych pakietów będziemy mogli pobrać z repozytoriów. Potrzebna będzie m.in. biblioteka libssl. Możemy ją pobrać za pomocą polecenia:
sudo apt-get install libssl-dev
Dla najnowszej wersji squid będziemy musieli dodatkowo skompilować libecap w wersji 1.0. Niestety, w repozytoriach stabilnych wersji Ubuntu i Debiana dostępna jest jedynie starsza wersja 0.2. Na szczęście, jest to zadanie niezwykle proste. Najpierw pobieramy program ze strony domowej producenta:
Następnie rozpakowujemy pakiet poleceniem:
tar -zxvf libecap-1.0.1.tar.gz
Kompilacja i instalacja tej biblioteki jest bardzo prosta i składa się z trzech poleceń:
./configure make sudo make install
Pora rozpocząć kompilację naszego celu. Wchodzimy do katalogu, w którym znajduje się rozpakowany wcześniej program. Następnie wydajemy polecenie:
sudo ./configure --datadir=/usr/share/squid3 \ --sysconfdir=/etc/squid3 \ --mandir=/usr/share/man \ --enable-inline \ --disable-arch-native \ --enable-async-io=8 \ --enable-storeio="ufs,aufs,diskd,rock" \ --enable-removal-policies="lru,heap" \ --enable-delay-pools \ --enable-cache-digests \ --enable-icap-client \ --enable-follow-x-forwarded-for \ --enable-auth-basic="DB,fake,getpwnam,LDAP,MSNT,MSNT-multi-domain,NCSA,NIS,PAM,POP3,RADIUS,SASL,SMB" \ --enable-auth-digest="file,LDAP" \ --enable-auth-negotiate="kerberos,wrapper" \ --enable-auth-ntlm="fake,smb_lm" \ --enable-external-acl-helpers="file_userip,kerberos_ldap_group,LDAP_group,session,SQL_session,unix_group,wbinfo_group" \ --enable-url-rewrite-helpers="fake" \ --enable-eui \ --enable-esi \ --enable-icmp \ --enable-zph-qos \ --enable-ecap \ --disable-translation \ --with-swapdir=/var/spool/squid3 \ --with-logdir=/var/log/squid3 \ --with-pidfile=/var/run/squid3.pid \ --with-filedescriptors=65536 \ --with-large-files \ --with-default-user=proxy \ --enable-ssl \ --enable-ssl-crtd \ --with-openssl \ --enable-delay-pools
Nie będę omawiał znaczenia wszystkich użytych tutaj przełączników, gdyż właśnie w ten sposób została skompilowana paczka znajdująca się w repozytoriach. Jedyne co dodaliśmy, to cztery ostatnie przełączniki: -‑enable-ssl -‑enable-ssl-crtd -‑with-openssl oraz -‑enable-delay-pools. Trzy pierwsze włączają moduł SSLBUMP, co pozwala nam modyfikować treść stron szyfrowanych za pomocą protokołu TLS. Ostatni natomiast włącza możliwość ograniczenia prędkości klientom, wg różnych kryteriów.
Po przeprowadzeniu konfiguracji środowiska możemy rozpocząć kompilację za pomocą standardowego polecenia sudo make. Aby przyspieszyć ten proces, możemy po przełączniku -j podać liczbę rdzeni/wątków, którymi dysponuje nasz komputer. Dzięki temu do procesu kompilacji zostaną wykorzystane wszystkie dostępne zasoby.
Teraz, po kilkunastu minutach oczekiwania czeka nas jedynie instalacja upragnionego serwera pośredniczącego. Robimy to standardowo, za pomocą polecenia sudo make install. Od tego momentu możemy się cieszyć w pełni funkcjonalnym, lecz jeszcze nie skonfigurowanym serwerem proxy.
Konfiguracja systemd

Musimy pamiętać, że wersja ręcznie kompilowana nie zawiera plików dla sysvinit/systemd, które umożliwiają łatwe zamykanie/uruchamianie/restartowanie usługi. Będziemy musieli je stworzyć ręcznie.
Przykładowy plik dla usługi systemd, który umieszczamy w katalogu /etc/systemd/system, może wyglądać tak:
[Unit] Description=LSB: Squid HTTP Proxy version 3.x Before=runlevel2.target runlevel3.target runlevel4.target runlevel5.target shutdown.target After=network-online.target remote-fs.target systemd-journald-dev-log.socket nss-lookup.target Wants=network-online.target Conflicts=shutdown.target [Service] Type=forking Restart=no TimeoutSec=5min IgnoreSIGPIPE=no KillMode=process GuessMainPID=no RemainAfterExit=yes SysVStartPriority=2 ExecStart=/usr/local/squid/sbin/squid ExecStop=/usr/local/squid/sbin/squid -k kill ExecReload=/usr/local/squid/sbin/squid -k restart [Install] WantedBy=multi-user.target
Następnie wydajemy dwa polecenia:
systemctl enable squid3.service
Dzięki temu poleceniu usługa squid3 będzie uruchamiana zawsze przy starcie komputera. Usługę będziemy mogli zamykać/restartować za pomocą systemctl
systemctl [start/stop/restart] squid3.service
Domyślny plik konfiguracyjny
acl SSL_ports port 443 acl Safe_ports port 80 # http acl Safe_ports port 21 # ftp acl Safe_ports port 443 # https acl Safe_ports port 70 # gopher acl Safe_ports port 210 # wais acl Safe_ports port 1025-65535 # unregistered ports acl Safe_ports port 280 # http-mgmt acl Safe_ports port 488 # gss-http acl Safe_ports port 591 # filemaker acl Safe_ports port 777 # multiling http acl CONNECT method CONNECT http_access deny !Safe_ports http_access deny CONNECT !SSL_ports http_access allow localhost manager http_access deny manager http_access allow localhost http_access deny all http_port 3128 coredump_dir /var/spool/squid3 refresh_pattern ^ftp: 1440 20% 10080 refresh_pattern ^gopher: 1440 0% 1440 refresh_pattern -i (/cgi-bin/|\?) 0 0% 0 refresh_pattern . 0 20% 4320
Squid, podobnie jak każdy inny linuksowy program, jest domyślnie w jakiś sposób skonfigurowany. Niestety, w naszym przypadku będziemy musieli się trochę napracować. Domyślny plik konfiguracyjny zawiera jedynie podstawowy zestaw opcji, które lekko poprawiają komfort korzystania z internetu. W jaki sposób? Fragmenty nieraz odwiedzanych witryn, które nie zmieniają się zbyt często, są zapisywane w pamięci RAM serwera proxy. W ten sposób, gdy klient znowu zażąda otwarcia tej samej witryny, jej części nie są pobierane ze źródłowego serwera, a z lokalnego. Poprawia to znacznie (szczególnie, jeśli nie mamy zbyt szybkiego łącza) komfort przeglądania globalnej sieci. Przeanalizujmy, linijka po linijce treść, która znajduje się w domyślnym pliku konfiguracyjnym.
acl SSL_ports port 443
acl oznacza definicję listy kontroli dostępu. Tej konstrukcji będziemy używali dość często. W tym wypadku tworzona jest lista portów, przez które będziemy mogli komunikować się ze światem. Ruch płynący przez wszystkie pozostałe porty zostanie zablokowany (http_access deny !Safe_ports).
Kolejnym poleceniem, którego będziemy bardzo często używali jest http_access. Przykład jego zastosowania widzimy w kolejnych linijkach domyślnego pliku konfiguracyjnego. [code=shell]http_access allow localhost manager[/code]
Powyższa linijka pozwala na używanie serwera proxy jedynie “menedżerowi pamięci cache” oraz maszynie lokalnej. Na końcu zawsze znajduje się polecenie
http_access deny all
Jeśli pakiet nie został przepuszczony przez jedną z wcześniejszych linijek, to w tym momencie zostanie na pewno odrzucony.
Kolejna linijka to http_port 3128. Definiuje ona, którego portu używa nasz serwer proxy. Możemy wybrać dowolną liczbę. Nie ma to większego znaczenia.
Coredump_dir /var/spool/squid3
Jest to miejsce, w którym umieszczane będą zrzuty z pamięci programu, jeśli będzie on działał niepoprawnie. refresh_pattern - dotarliśmy do jednego z ciekawszych, ale i ostatnich elementów pliku konfiguracyjnego. Są to reguły, wg których do do pamięci tymczasowej zapisywane będą pliki danych witryn.
Spójrzmy, wg jakiego schematu mogą być tworzone te reguły:
refresh_pattern regex_min percent regex_max
Regex_min oraz regex_max to odpowiednio minimalny i maksymalny “wiek” zapisywanego obiektu. Wartość percent służy do ustalenia “świeżości” obiektu w przypadku, kiedy ten został zmodyfikowany na źródłowym serwerze. Jeśli pierwszy raz czytasz o czymś takim, może być to trochę trudne do zrozumienia, dlatego posłużę się przykładem:
refresh_pattern -i \.gif$ 1440 20% 10080
Co oznacza ta reguła? Zobaczmy:
- Reguła tyczy się wszystkich plików, których nazwa kończy się na .gif lub .GIF.
- Jeśli wiek (wiek mówi o tym, jak długo obiekt znajduje się na naszym serwerze proxy) jest mniejszy niż 1440 minut, oznacza to, że ta kopia jest świeża i nie trzeba jej aktualizować z serwera źródłowego.
- Jeśli wiek pliku jest większy niż 10080 minut, oznacza to że jest przestarzały i należy pobrać świeżą kopię z serwera.
- Jeśli wiek pliku jest większy niż 1440 minut, ale mniejszy niż 10080 minut, oznacza to, że należy obliczyć “współczynnik świeżości”. Możemy to zrobić, dzieląc czas, przez jaki plik istnieje na naszym lokalnym serwerze przez ilość minut, która upłynęła od jego ostatniej aktualizacji na serwerze źródłowym. Na przykład, przyjmijmy że nasz gif został u źródła zaktualizowany 10000 minut temu, natomiast na naszym serwerze pośredniczącym jest obecny od 1800 minut. Mając te dane możemy obliczyć domniemany współczynnik świeżości, który w tym wypadku wynosi 1800/10000*100%=18%. Jest to wartość mniejsza niż podana w pliku konfiguracyjnym (20%). Oznacza to, że to analizowane zdjęcie jest świeże.
Domyślne reguły sprawdzają się w większości przypadków. Jeśli jednak chcemy bardziej zaryzykować i osiągnąć lepsze wyniki, możemy stworzyć własne refresh_patterns. Dodatkowe informacje na temat ich tworzenia możemy uzyskać w dokumentacji projektu:
A co z logami?
Log jest to potoczna nazwa zapisu wyniku działania programu - jego komunikatów ostrzegawczych czy błędów. Squid tworzy dwa pliki. Obydwa są zapisane w katalogu /var/log/squid3 (jeśli wymarzyłeś sobie inne miejsce - nie ma przeszkód. Wystarczy podać inny katalog podczas konfiguracji źródeł Squid).
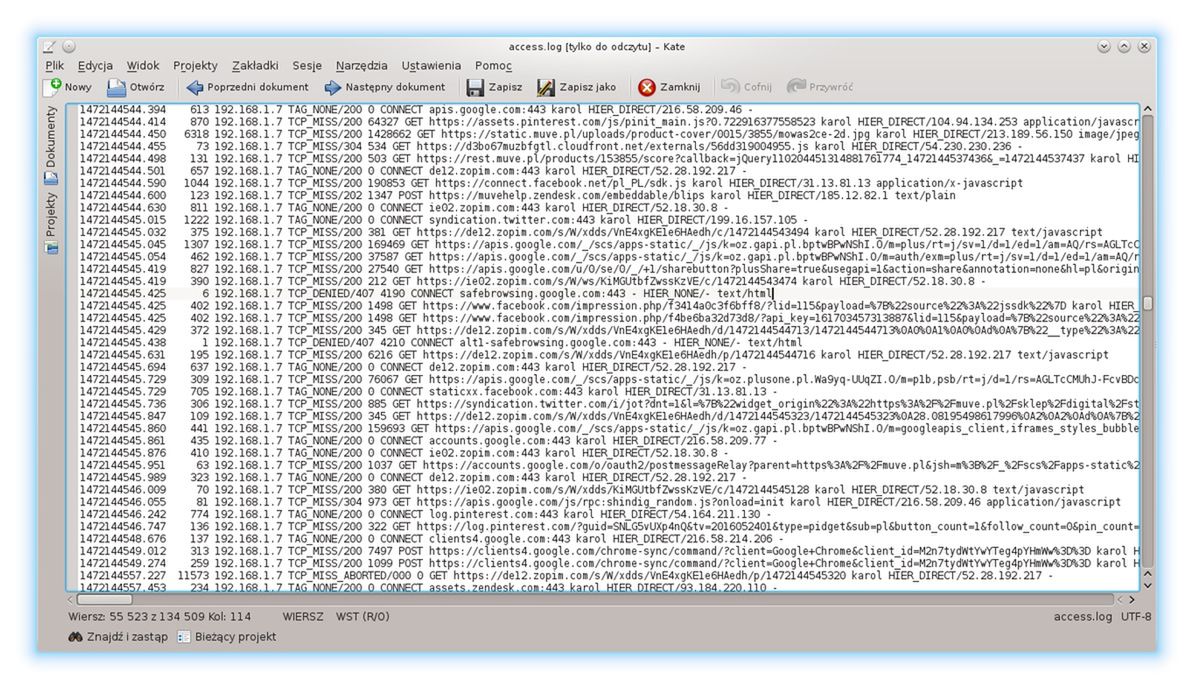
Pierwszym z nich jest access.log. Przechowuje on wszystkie próby dostępu do Internetu podejmowane przez użytkowników korzystających z danego serwera. Z pliku tego możemy odczytać m.in.:
- Stempel czasowy
- Jaki adres IP/użytkownik podjął próbę nawiązania połączenia
- Czy połączenie się udało(TCP_MISS) czy zostało zablokowane przez serwer pośredniczący(TCP_DENIED)
- Z jakim adresem internetowym/adresem IP/portem próbowano podjąć próbę połączenia
- Jaki rodzaj treści był pobierany/wysyłany
Jak widzimy, plik access.log może dostarczyć bardzo dużą ilość informacji o zwyczajach użytkowników korzystających z naszej sieci. Niestety, wyniki działania tu zapisane są ciężkie w interpretacji przez człowieka. Pojedyncza próba połączenia się z witryną (np.: www.dobreprogramy.pl) może wygenerować od kilku do kilkudziesięciu wpisów w pliku access.log. Oddzielne linijki utworzą między innymi żądania pobrania reklam czy skryptów śledzących zachowanie użytkownika na stronie.
Drugim z plików zapisujących wyniki działania programu jest cache.log. Z jego treści możemy dowiedzieć się między innymi, ile elementów stron internetowych zostało zapisanych na serwerze pośredniczącym. W tym miejscu możemy także dowiedzieć się o różnych błędach (np.: niemożności otwarcia jakiegoś pliku wymaganego do poprawnego działania serwera).
Modyfikujemy podstawową konfigurację
Serwer proxy powinien pracować cały czas. Nie mniej, czasami może zajść ewentualność (np.: brak prądu), która spowoduje jego restart. W takim wypadku cały zgromadzony zasób cache zostanie stracony, gdyż domyślnie przechowywany jest on jedynie w pamięci RAM. Możemy temu zapobiec, tworząc magazyn obiektów cache na dysku. Najpierw musimy do pliku konfiguracyjnego dodać następującą linijkę:
cache_dir ufs /var/spool/squid3/cache 100 16 256
/var/spool/squid3/cache to oczywiście ścieżka do katalogu, gdzie chcemy przechowywać pliki zapisanych witryn. Liczba 100, która znajduje się tuż po lokalizacji folderu przechowującego pliki cache oznacza maksymalną ilość miejsca, jaką poświęcimy na ten cel. 16 oraz 256 oznaczają liczbę podkatalogów, w których przechowywane będą fragmenty stron internetowych. Możemy zmienić te wartości, ale najlepszym wyjściem w chwili obecnej będzie pozostawienie liczb domyślnych.
Wprowadzenie powyższej linii do pliku konfiguracyjnego nie wystarczy, aby serwer przerzucił pliki cache z pamięci RAM na dysk twardy. Musimy jeszcze poinstruować nasz serwer pośredniczący, aby na dysku utworzył odpowiednią strukturę katalogów. Możemy to zrobić bardzo prosto - przechodzimy do katalogu, w którym znajduje się plik wykonywalny: /usr/local/squid/sbin. Następnie wydajemy polecenie:
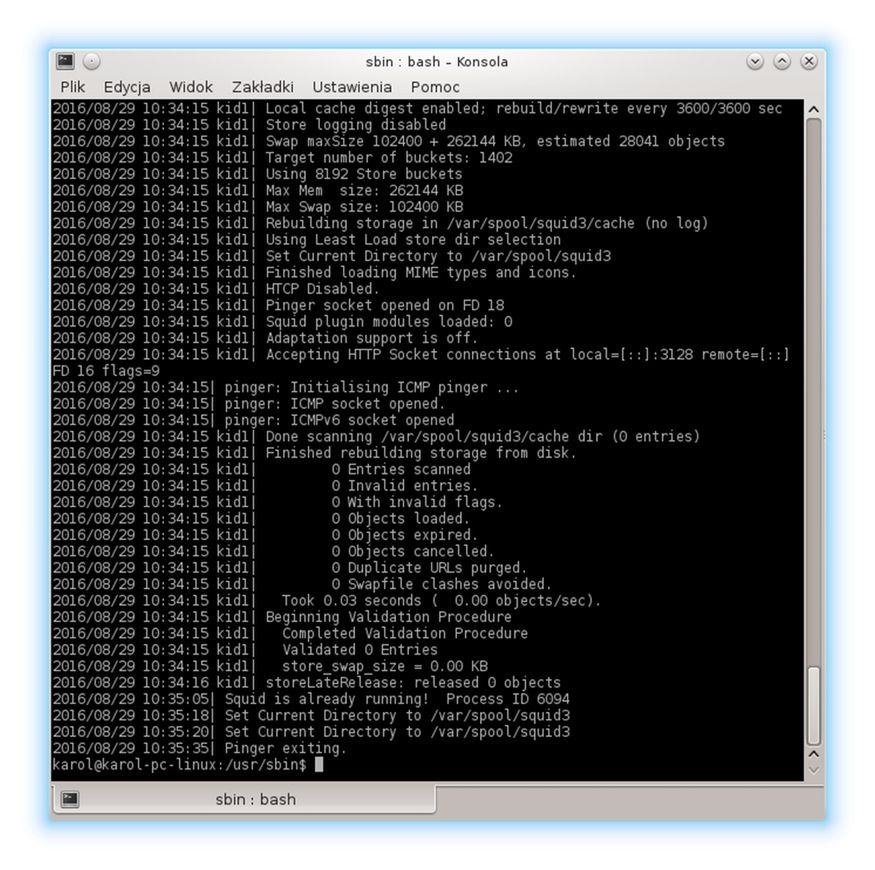
./squid -z
Wynik działania tego polecenia widzimy na powyższym zrzucie. Od tego momentu wszelkie fragmenty przeglądanych przez użytkowników naszej sieci stron internetowych będą zapisywane w nowo utworzonej strukturze katalogów.
Domyślnie, z serwera pośredniczącego może korzystać tylko maszyna lokalna - ta, na której ta aplikacja działa. Aby umożliwić pozostałym komputerom w naszej sieci LAN dostęp do proxy, musimy dodać do pliku konfiguracyjnego kilka linijek.
Najpierw musimy stworzyć nową listę kontroli dostępu - ACL. Już wcześniej powiedzieliśmy sobie o niej parę słów. Teraz zajmiemy się nią nieco dokładniej. Po słówku acl podajemy nazwę listy, typ elementu, do którego się odwołuje, a na końcu sam element. Uzbrojeni w tą wiedzę, utwórzmy listę acl localnet, która zawiera wszystkie adresy IP przewidziane dla sieci lokalnych.
acl localnet 10.0.0.0/8 acl localnet src 172.16.0.0/12 acl localnet src 192.168.0.0/16
Zauważyłeś pewnie, że kolejne podsieci są zdefiniowane w kolejnych linijkach pliku. Nie jest to błąd. Każda linijka po prostu rozszerza to, co istniało już wcześniej. Teraz musimy jedynie zaakceptować ruch płynący z adresów zdefiniowanych przez listę kontroli dostępu localnet. Robimy to za pomocą polecenia:
http_access allow localnet
Dzięki temu rozwiązaniu wszystkie komputery w naszej sieci lokalnej będą posiadały możliwość używania serwera proxy.
Konfiguracja klientów
Serwer pośredniczący może działać w dwóch trybach. Może być “niewidzialny” dla stacji roboczych. Takie proxy nazywa się “transparentnym”. My zajmiemy się drugim rodzajem, “nietransparentnym” serwerem pośredniczącym, który będzie wymagał dodatkowej konfiguracji na klienckich komputerach. Dlaczego podjąłem taki wybór? Przerobienie nietransparentnego proxy na transparentne to kwestia kosmetycznych zmian. Dodatkowo jest to szeroko opisane w Internecie (polskim także!). Natomiast tutaj chcemy się skupić na bardziej zagmatwanych zagadnieniach związanych z omawianym serwerem pośredniczącym. No to bierzmy się do roboty.
Pierwsza metoda zakłada zmianę w opcjach internetowych.
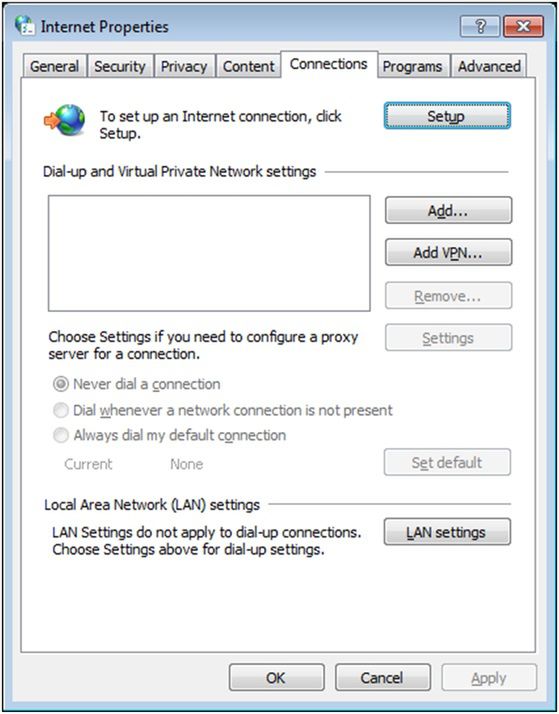
Ustawienia serwera Proxy możemy wprowadzić, wchodząc w Opcje Internetowe. Należy przejść na zakładkę Połączenia i kliknąć “Ustawienia sieci LAN”.
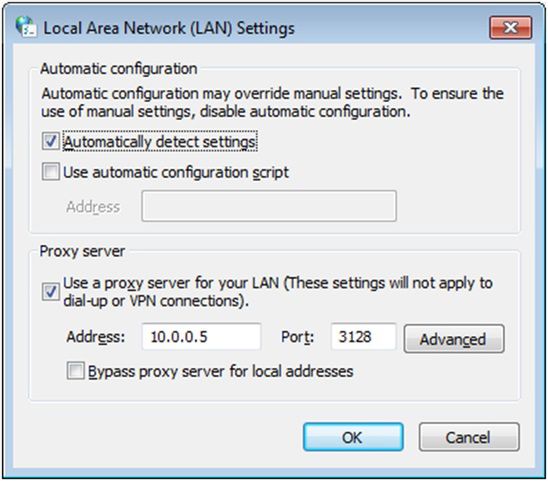
Zaznaczamy pole “Użyj serwera proxy dla twojej sieci LAN”. Następnie wprowadzamy adres IP oraz port, z którego korzysta nasz serwer pośredniczący. Sposób ten ma jedną wadę. Użytkownik będzie mógł w każdej chwili zmienić ustawienia serwera proxy. Dodatkowo, na każdym koncie musimy wprowadzać zmiany powtórnie. Aby wyemilinować te wady, musimy skorzystać z edytora lokalnych zasad grupy (gpedit).
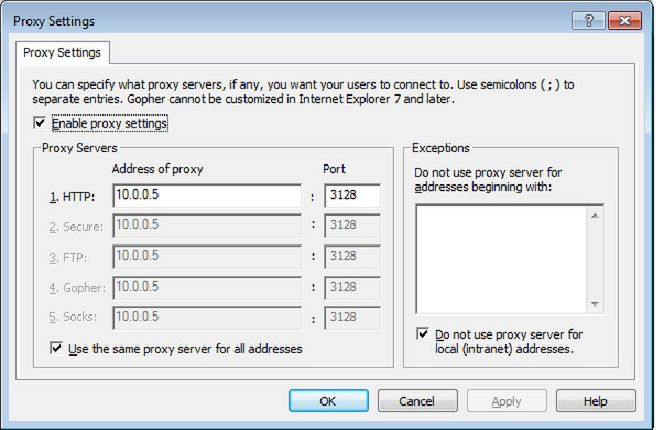
Uruchamiamy edytor lokalnych zasad grupy. Aby to zrobić, w polu wyszukiwania w menu start wpisujemy: gpedit.msc. Następnie przechodzimy drzewko katalogów w następującej kolejności: Konfiguracja użytkownika->Ustawienia systemu Windows->Internet Explorer Maintenance->Połączenia->Ustawienia serwera Proxy. W wyświetlonym okienku wpisujemy adres IP oraz port naszego serwera pośredniczącego. Nie zwracaj uwagi na to, że opcja w nazwie zawiera słowa “Internet Explorer”. Wprowadzone tutaj zmiany tyczą się każdej przeglądarki.
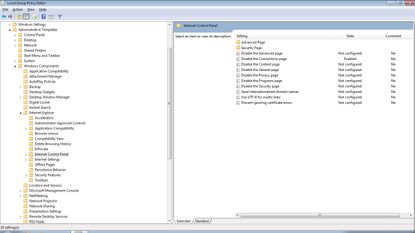
No dobra, każdy użytkownik ma ustawiony serwer pośredniczący, z którego ma korzystać. Nie mniej, dalej nie zablokowaliśmy możliwości zmiany tego ustawienia. Ten element również zmodyfikujemy za pomocą edytora lokalnych zasad grupy. Przechodzimy drzewko opcji w następującej kolejności: Konfiguracja użytkownika->Szablony administracyjne>Komponenty systemu Windows->Internet Explorer->Opcje internetowe. Wyszukujemy opcję - wyłącz zakładkę połączenia. Włączamy tę możłiwość.
W Windows 10 sytuacja nieco się komplikuje. W tym systemie nie ustawimy opcji serwera proxy z poziomu gpedit. Musimy więc na koncie każdego użytkownika ręcznie przeprowadzać tę zmianę. Następnie, podobnie jak w poprzednim wypadku, należy zablokować możliwość modyfikacji tych ustawień.
Słowem podsumowania
W tej części zajęliśmy się kompilacją, instalacją oraz konfiguracją najpopularniejszego serwera proxy squid. Omówiliśmy jedynie podstawy związane z tym zagadnieniem. W następnym epizodzie zajmiemy się m.in. skonfigurowaniem autoryzacji dostępu do serwera proxy, blokowaniem poszczególnym użytkownikom dostępu do wybranych witryn, a także wieloma innymi, ciekawymi rzeczami.





![Razer DeathAdder V3 HyperSpeed – lekka, szybka i precyzyjna [Recenzja]](https://v.wpimg.pl/Yjk1LmpwdgsKUzpeXwx7HkkLbgQZVXVIHhN2T19CYF0TAn1bXwM8CQMfOx0TEzdEG11jBB0QdgsKBSpaQkI_R1oBfl1dQ2EODRx1DEQSdFsKBXkPE0FqCAkIeUMaBz5IFg)
![Tania optyka do wideokonferencji. Kamerka Logitech Brio 100 [Recenzja]](https://v.wpimg.pl/NmE2LmpwYQwkUDpeXwxsGWcIbgQZVWJPMBB2T19Cd1o9AX1bXwMrDi0cOx0TEyBDNV5jBB0QYVUgVn9ZERR_QH0Kf15dQ3cJIR8uXRRAY11yBC5fQhR8W3NTekMaBylPOA)
