

Proxy dla laików — kompleksowa konfiguracja squid, cz.2
Pierwsza część instruktażu na temat konfiguracji squid została opublikowana dawno temu. Niestety, nie miałem czasu, aby na poważniej przysiąść do tego tematu przez ostatnie miesiące. Teraz nadszedł czas, aby naprawić ten błąd.
W pierwszej części zajmowaliśmy się podstawową konfiguracją serwera proxy squid. Nauczyliśmy się, jak przepuścić przez niego ruch generowany przez sieć lokalną. I na tym skończyliśmy. Jednakże serwer pośredniczący, jak dobrze wiemy, nie służy jedynie do optymalizacji ruchu sieciowego, lecz także do wielu innych, ciekawych rzeczy. W tym momencie zakładam, że podstawowa konfiguracja serwera squid została wykonana właściwie, gdyż właśnie na niej będziemy teraz bazowali. Pobawimy się w Chińczyków i nauczymy się blokować dostęp do danych witryn niektórym lub wszystkim użytkownikom. Dowiemy się także, jak analizować, jaki ruch sieciowy generuje każdy z userów naszej sieci.
Przez ostatnie kilka miesięcy, w obozie squid nie zaszła żadna rewolucja, toteż nadal będziemy używać aplikacji z gałęzi 3.5. W pierwszej części używaliśmy 3.5.19. Obecną najnowszą wersją jest 3.5.25. Między tymi wariantami squid nie istnieje żadna znacząca różnica. Poradnik jest przygotowany dla najnowszej wersji 3.5.25, aczkolwiek wszystko powinno działać także na starszych wersjach squid (nie wiesz, jak zainstalować squid? Szczegóły znajdują się w części pierwszej).

Pora zacząć naszą eskapadę po czeluściach serwerów pośredniczących!
Filtrowanie Internetu
Blokowanie dostępu do określonych witryn wszystkim użytkownikom
W dzisiejszych czasach bardzo często słyszy się o tym, że ktoś (jakiś kraj, rząd itp.) blokuje dostęp do danych witryn (np.: ostatnio – Ukraina do VKontakte). Można to zrealizować na wiele sposobów. Jednym z takich, które może zastosować przeciętny użytkownik jest odpowiednie skonfigurowanie serwera proxy.

Na początku, zadajmy sobie pytanie, w jakim celu przeciętny użytkownik ma używać akurat takich narzędzi? Choćby po to, aby ograniczyć dostęp do niepożądanych witryn np.: swoim dzieciom. Co by nie mówić, aplikacje rodzaju „Cenzor” są bardzo proste do obejścia. Natomiast, odpowiednio skonfigurowany serwer squid oraz odpowiednio ustawione komputery klienckie stanowią już znacznie poważniejszą barierę do obalenia.
Do blokowania stron służą tzw. ACL‑listy. Samą blokadę możemy zrealizować na dwa sposoby – albo zezwolić na dostęp do wszystkich stron i zablokować wybrane (blacklista), albo zablokować dostęp do wszystkich stron i zezwolić na wybrane (whitelista). W artykule skupimy się głównie na blacklistach. Zmiana blacklisty na whitelistę jest bardzo prosta i wymaga jedynie kosmetycznej zmiany w pliku konfiguracyjnym, toteż nie będziemy się tym zajmować.
Załóżmy, że chcemy zablokować dostęp do strony www.facebook.pl wszystkim komputerom z naszej sieci domowej. Musimy odpowiednio skonfigurować plik konfiguracyjny squid.conf. (dla przypomnienia – znajduje się on w katalogu /etc/squid3/)
Otwieramy plik squid.conf. Cały plik jest nieco długi, a my będziemy operowali jedynie na jego drobnym fragmencie. Dlaczego? Bo nie możemy wpisać naszych instrukcji byle gdzie. Muszą one być dodane w ściśle określonym miejscu. Przykład takiego miejsca znajduje się w listingu poniżej (dodajemy nasze linijki pod ostatnim hashem).
# # INSERT YOUR OWN RULE(S) HERE TO ALLOW ACCESS FROM YOUR CLIENTS # http_access allow localnet http_access allow localhost http_access deny all
Plik squid.conf jest przetwarzany sekwencyjnie. Co to oznacza? Dane są przetwarzane i wykonywane linijka po linijce. Wracając do przykładu powyżej, squid najpierw się dowie, że ma zezwolić na dostęp do Internetu komputerom należącym do grupy localnet i localhost. Ostatnia linijka – http_access deny all, oznacza, że wszystkie pozostałe żądania mają być odrzucone.
Modyfikując plik konfiguracyjny, musimy pamiętać, że wszelkie żądania nadania uprawnień mają priorytet przed żądaniami odebrania uprawnień. Co to znaczy? Jeśli najpierw zezwolimy na dostęp do wszystkich stron (http_access allow localnet) to potem nie będziemy mogli odebrać uprawnień do jednej z witryn. Musimy najpierw zablokować dostęp do danej witryny, a potem zezwolić na dostęp do pozostałych. Przeanalizujmy to na naszym przykładzie.
Chcemy uniemożliwić wszystkim użytkownikom lokalnej sieci dostęp do serwisu www.facebook.pl . Stosując się do rad powyżej, odpowiednie linijki musimy dodać przed dyrektywami http_access allow. Omawiany fragment pliku konfiguracyjnego będzie wtedy wyglądał tak:
acl facebook dstdomain www.facebook.pl http_access deny facebook http_access allow localnet http_access allow localhost http_access deny all
Jak pewnie zauważyłeś, dodaliśmy dwie linijki. Pierwsza tworzy listę kontroli dostępu acl, o nazwie facebook. Parametr dstdomain oznacza, że dotyczy ona domeny. Na samym końcu podana jest owa domena. Druga linijka, natomiast, wprowadza naszą acl‑listę w życie. Aby zobaczyć efekty naszych działań, należy zapisać plik i zrestartować squid za pomocą polecenia:
systemctl restart squid3.service
Rezultat działania powyższych modyfikacji przedstawia się następująco:
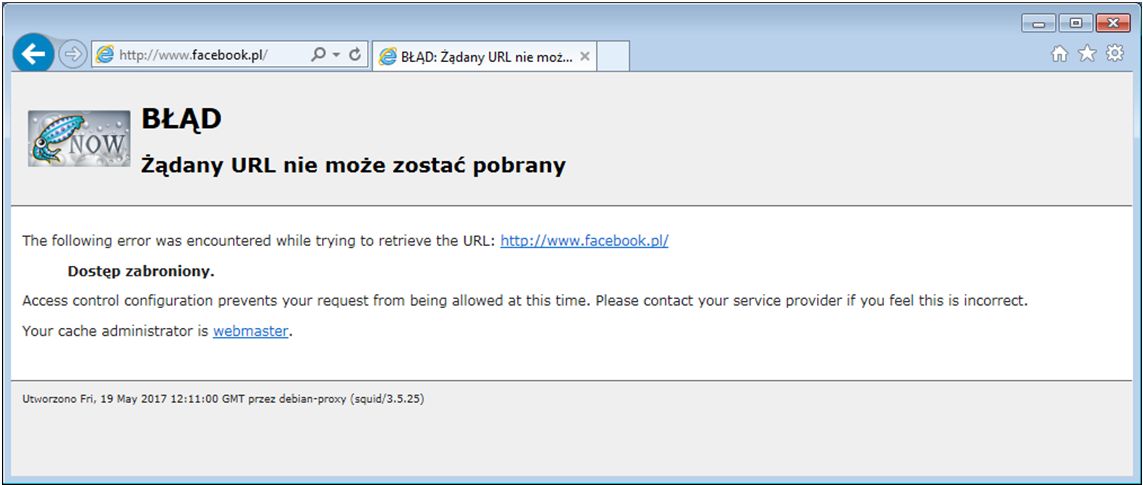
Jak widzimy, serwer proxy nie zezwolił na wejście na stronę www.facebook.pl Wszystko działa wyśmienicie, ale powstaje pytanie – jeśli lista blokowanych stron miałaby zawierać kilkaset pozycji, to czy to wszystko musi być zapisane w głównym pliku konfiguracyjnym squid? Gdyby tak było, squid.conf mógłby stać się niezwykle mało czytelny. Jak się pewnie domyślasz, musi istnieć sposób przeniesienia listy zablokowanych witryn do innego pliku. Zaraz go poznamy.
W tym samym katalogu, który zawiera plik squid.conf, utwórzmy plik „blokady.txt”. W pliku wypiszmy adresy stron, które chcemy zablokować. Każdy adres powinien znajdować się w oddzielnej linijce.
Plik squid.conf. zmodyfikujmy w następujący sposób:
acl web_to_block dstdomain „/etc/squid3/blokady.txt” http_access deny web_to_block http_access allow localnet http_access allow localhost http_access deny all
Co się zmieniło? Oprócz zmiany nazwy listy kontroli dostępu (z facebook na web_to_block) zmienił się także ostatni jej parametr. Zamiast wymieniać domenę w pliku konfiguracyjnym, podaliśmy ścieżkę do pliku, który zawiera wszystkie adresy, które chcemy zablokować. Jeśli chcemy zablokować konkretny adres IP, a nie nazwę domenową, zamiast dstdomain podajemy parametr dst. Wtedy w pliku umieszczamy adresy IP, do których dostęp chcemy zablokować.
Sposób na kontrolę dostępu, który poznaliśmy przed chwilą, jest dobry – aczkolwiek nie doskonały. Zablokowanie dostępu do domeny facebook.pl nie oznacza, że całkowicie odcięliśmy dostęp do tegoż serwisu naszym użytkownikom. Ci mogą skorzystać po prostu z innego adresu, np.: facebook.com lub facebook.de.
Oprócz tworzenia długaśnego pliku z listą wykluczonych domen, Istnieje inny, znacznie lepszy sposób. Opiera się on na zastosowaniu reguły blokowania do wszystkich adresów zawierających podane słowo kluczowe. Tym sposobem możemy np.: zablokować wszystkie adresy stron, które zawierają w sobie ciąg znaków „facebook”. Jak to zrobić? Bardzo prosto. Odpowiednio modyfikujemy linijkę dotyczącą tworzenia listy kontroli dostępu. Nowe ustawienia będą wyglądały następująco:
acl facebook url_regex facebook http_access deny facebook http_access allow localnet http_access allow localhost http_access deny all
Jak widzisz, dst_domain www.facebook.pl zamieniliśmy na url_regex facebook. Regex to tzw. wyrażenie regularne. Wyrażenie regularne w uproszczeniu opisuje, jak może (lub nie może) wyglądać ciąg znaków. url_regex pozwala oczywiście nie tylko na blokowanie stron zawierających określone słowa. Możemy także w bardziej skomplikowany sposób filtrować adresy stron. Ale to niestety wykracza już poza zakres omawianych przez nas działań. Blokowanie dostępu do danych witryn określonym użytkownikom
Reguły, które wykorzystaliśmy powyżej, nie będą się sprawdzać w każdym wypadku. Wszak, blokują one dostęp do witryn wszystkim użytkownikom danej sieci. Zwykle jest tak, że chcemy odciąć dostęp do danych witryn jedynie danej grupie użytkowników. Obecnie nie wiemy jeszcze, jak autoryzować użytkowników w serwerze proxy squid. Musimy więc opierać się na adresach IP i MAC. Postawmy sobie cel – zablokujmy komputerowi o adresie IP 10.0.2.4 dostęp do witryny www.tvn24.pl a komputerowi o adresie MAC 08‑00-27-B1-B6-B9 dostęp do witryny www.tvp.info. Plik konfiguracyjny będzie wyglądał tak:
acl tvn24 dstdomain www.tvn24.pl acl tvpinfo dstdomain www.tvp.info acl banned_client src 10.0.2.4 acl banned_client2 arp 08:00:27:B1:B6:B9 http_access deny tvn24 banned_client http_access deny tvpinfo banned_client2 http_access deny all
Jak zwykle, intensywnie wykorzystujemy access listy. Najpierw, podobnie jak w poprzednich przykładach, definiujemy dwie listy kontroli dostępu zawierające adresy domen. W trzeciej linijce tworzymy standardową listę kontroli dostępu zawierającą adresy IP. Nowość pojawia się w czwartej linijce – lista kontroli ma nowy parametr – arp. Po parametrze arp podajemy MAC adres kart sieciowych, które ta lista ma zawierać.
Kolejne dwie linijki to komendy http_access. Nowość to konstrukcja tej komendy. Dotychczas, po http_access deny podawaliśmy nazwę jedynie jednej access listy – tej, która zawierała listę blokowanych adresów/domen. Teraz, jako drugi parametr podajemy kolejną access listę. Zawiera ona listę komputerów, których tyczy się ta reguła. Tym oto sposobem możemy blokować dostęp do danych witryn określonym komputerom.
Wszystkie Access listy możemy przenieść do pliku zewnętrznego, podając, zamiast adresu IP czy MAC adresu, lokalizację pliku zawierającego dane ustawienia.
Blokowanie dostępu do witryn o określonej godzinie
Czasami zdarza się tak, że chcemy zablokować dostęp do danych witryn tylko w określonych godzinach. Bardzo dobrym przykładem jest środowisko szkolne. Możemy zablokować uczniom dostęp do wszystkich witryn oprócz platformy, na której mają rozwiązywać zadania, na czas przeprowadzenia sprawdzianu. Podobnie, jak w poprzednich przykładach, także i tutaj skorzystamy z dobrodziejstw list kontroli dostępu. Tym razem użyjemy parametru time.
Konstrukcję listy ACL time omówimy oddzielnie, gdyż jej budowa jest nieco bardziej skomplikowana od ACL‑i omawianych do tej pory. Przykładowa lista czasowa acl
acl lista_czasowa time S M T W H F A 6:00-21:00
Pierwsze trzy parametry są oczywiste – acl oznacza, że definiujemy listę kontroli dostępu, lista_czasowa to jej nazwa, a time – jej rodzaj. Literki, które występują dalej to dni, w których dana access-lista może zezwolić na wykonanie danego działania. Literki oznaczają kolejno:
- S – niedziela
- M – poniedziałek
- T – wtorek
- W – środka
- H – czwartek
- F – piątek
- A – sobota
Ostatni parametr, jaki przyjmuje ta lista kontroli dostępu, to zakres godzin, w jakich ma ona obowiązywać.
Dla lepszego zrozumienia przeanalizujmy następujący przykład. Zablokujmy wszystkim użytkownikom dostęp do witryny www.facebook.com w dni robocze w godzinach od 7:00 do 14:00. Przykładowy plik konfiguracyjny, będący rozwiązaniem tego problemu, znajduje się poniżej:
acl facebook dstdomain www.facebook.com acl blokuj_twarzoksiazke time M T W H F 7:00-14:00 http_access deny facebook blokuj_twarzoksiazke http_access allow localnet http_access allow localhost http_access deny all
Plik konfiguracyjny powinien być jasny. Nie zostało tu zastosowane nic ponadto, czego używaliśmy do tej pory.
Łączenie Access-list
Na zakończenie rozważań na temat blokowania stron, postawmy sobie jakieś ambitniejsze zadanie. Spróbujmy np.: zablokować dostęp do strony www.google.pl tylko komputerowi o adresie IP 10.0.2.4, tylko w godzinach od 7:00 do 21:00. Jak tego dokonać? Zacznijmy od utworzenia odpowiednich Access-list. Będą one wyglądały tak:
acl google dstdomain www.google.pl acl blokuj_wielkiego_brata time M T W H F A S 7:00-21:00 acl blocked_client src 10.0.2.4
Teraz skonstruujmy odpowiednie wywołanie http_access. Jak ono mogłoby wyglądać? Do tej pory, w każdym przykładzie przyjmowało ono maksymalnie dwa parametry. Jak wsadzić trzeci i w które miejsce? Zasada jest banalnie prosta. Najpierw spójrz na te sześć przykładów (wszystkie możliwe wariacje połączenia tych trzech parametrów)
http_access deny blocked_client google blokuj_wielkiego_brata http_access deny blocked_client blokuj_wielkiego_brata google http_access deny google blocked_client blokuj_wielkiego_brata http_access deny google blokuj_wielkiego_brata blocked_client http_access deny blokuj_wielkiego_brata google blocked_client http_access deny blokuj_wielkiego_brata blocked_client google
Wszystkie powyżej wymienione access-listy oznaczają to samo. Kolejność parametrów nie ma znaczenia. Między wszystkimi łączonymi listami występuje spójnik i. Co to znaczy? Przetłumaczmy pierwsze z wywołań http_access na ludzki język:
Zablokuj dostęp klientowi o adresie IP 10.0.2.4 (i) do witryny www.google.pl (i) o godzinach 7:00-21:00 w dni robocze
W squid istnieje więcej rodzajów list kontroli dostępu niż te, którymi zajęliśmy się tutaj. Niemniej, wszystkie w komendzie http_access łączymy właśnie w ten sposób.
Logi squid
Powoli zbliżamy się do końca naszej dzisiejszej podróży po opcjach konfiguracyjnych squid. Wiemy już, jak można pobawić się w cenzora. Warto dowiedzieć się także co nieco o logach tworzonych przez serwer pośredniczący squid. Znajdują się tam informacje na temat tego, kto, kiedy i co przeglądał.
Wszystkie logi są zapisywane w katalogu /var/log/squid3. Jeśli wejdziemy do tego folderu, zauważymy dwa pliki: access.log i cache.log. Ten pierwszy przechowuje wszystkie interesujące nas informacje i to właśnie z niego będziemy korzystali najczęściej. cache.log natomiast przechowuje informacje o „optymalizacyjnych” funkcjach serwera pośredniczącego. Dowiemy się z niego co nieco o tym, jaka ilość pamięci została przeznaczona na „cache” czy ile miejsca jest obecnie zużywane na ten cel. W tym momencie nas to nie interesuje. Skupmy się więc na pliku access.log
Zawartość pliku możemy analizować ręcznie. Aby w oknie konsoli były wyświetlane na bieżąco nowododawane pozycje, należy użyć polecenia:
sudo tail –f /var/log/squid3/access.log
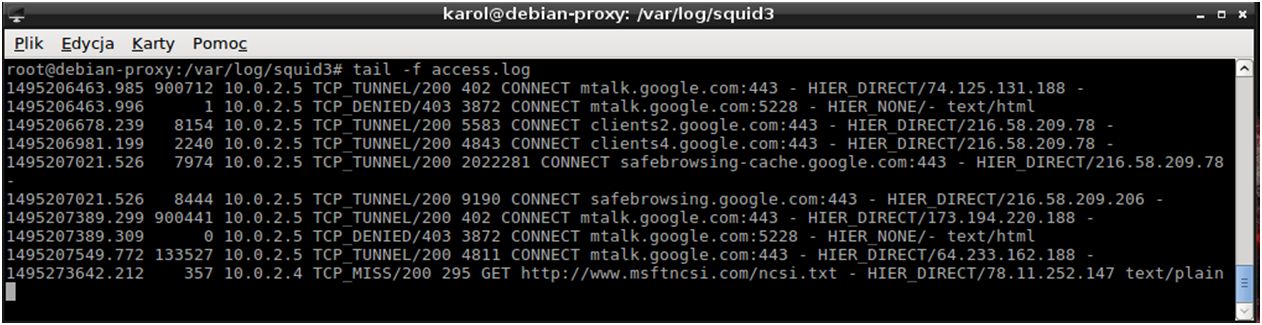
Co my tutaj mamy? Przeprowadźmy krótką analizę, kolumna po kolumnie.
[list] Pierwsza kolumna to stempel czasowy, zapisany w formacie unixowym. Wszystkie zdarzenia liczone są od momentu, kiedy squid po raz pierwszy został uruchomiony.
Kolejna kolumna to ilość czasu (ponownie w milisekundach) jaką pochłonęła realizacja danego żądania. Dla różnych typów połączeń wskazywany przedział czasu może być różny. Np.: dla protokołu http jest to czas od momentu, kiedy squid otrzyma żądania otwarcia strony do momentu, kiedy wyśle ostatni bajt odpowiedzi.
Trzecią kolumnę pewnie poznajemy. Jest to bardzo dobrze nam znany adres IP. Wskazuje on na klienta z naszej lokalnej sieci, który rozpoczął żądanie.
Następna, czwarta kolumna pokazuje rezultat i typ połączenia. Np.: TCP_DENIED oznacza odmowę dostępu do strony dla danego klienta.
Piąta kolumna to ilość bajtów dostarczonych do klienta.
Szósta kolumna to sposób „żądania”. W tym miejscu może się pojawić metoda GET, POST, ale nie tylko. Bardzo często pojawia się tutaj słówko „CONNECT”, które oznacza, że łączymy się przy użyciu tunelu SSL.
Powoli zbliżamy się do końca. Siódma kolumna to adres strony, do której chce się dostać klient. Na końcu zwykle znajduje się także numer portu.
Ostatnia kolumna to tzw. „hierarchy code”, kod hierarchii. W skrócie, mówi on o tym, jak żądanie zostało przetworzone. HIER_DIRECT oznacza, że żądanie zostało przetworzone i przekazane do klienta. Możemy tutaj zobaczyć także TIMEOUT, które oznacza, że przekroczono dopuszczalny czas na wykonanie żądania.
Jak widzimy, ręczna analiza pliku może być nieco czasochłonna. Możemy także pominąć istotne szczegóły. Dlaczego więc nie użyć programu, który zautomatyzuje analizę, a wyniki przedstawi w postaci ładnie wyglądających tabelek, które później można jeszcze bardziej upiększyć za pomocą CSS? Poznajcie SARG
SARG – Squid Analysis Report Generator – prosty sposób na logi Squid
SARG jest bardzo prostym w użyciu programikiem, który na podstawie pliku access.log pozwala generować pełne raporty HTML, zawierające dokładną interpretację danych zawartych w raportach squid. Program znajduje się w repozytoriach najpopularniejszych dystrybucji. Niestety, ta wersja jest zwykle przestarzała i nie współpracuje poprawnie z najnowszymi wersjami squid. Musimy więc pobrać najnowszą wersję generatora ze strony projektu. Na dzień dzisiejszy jest ona oznaczona numerkiem 2.3.10. Dostępna jest pod tym adresem Gdy pobieranie zostanie ukończone, przechodzimy w konsoli do folderu, w którym znajduje się pobrany plik. Rozpakowujemy archiwum, a następnie wchodzimy do utworzonego folderu:
tar –zxvf sarg-2.3.10.tar.gz cd sarg-2.3.10
Następnie wprowadzamy standardowe (jak w przypadku każdej kompilacji) polecenia:
./configure make sudo make install
Przy poleceniu make install może wystąpić błąd o następującej treści: „terror: gettext infrastructure mistmatch: using a Makefile.in.in from version 0.18 but autoconf macros are from gettext version 0.19.” Problem można rozwiązać w bardzo prosty sposób. Wystarczy przekopiować plik Makefile.in.in. z katalogu /usr/share/gettext/po/ do katalogu po w folderze źródeł sarg.
Plik konfiguracyjny sarg znajduje się w katalogu /usr/local/etc/sarg.conf. Musimy wprowadzić w nim kilka zmian, aby generator raportów działał poprawnie.

Pierwsza rzecz, którą musimy zmienić, to oczywiście lokalizacja pliku z logami squid. Musimy „odhaszować” linijkę access_log. Podaną ścieżkę zmieniamy na /var/log/squid3/access.log
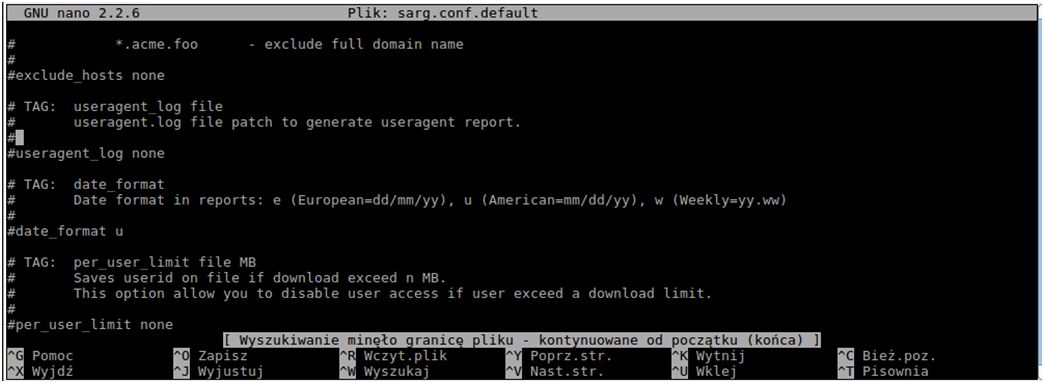
Następnie szukamy linikki date_format. Podobnie jak poprzednio, kasujemy znaczek „hash” i zmieniamy literkę u na e.
Ostatnia rzecz, którą powinniśmy zmienić to miejsce, w którym mają być zapisywane już gotowe raporty sarg. Możemy wpisać dowolną ścieżkę, możemy zostawić istniejącą. W każdym bądź razie musimy usunąć znaczek „hash”. To koniec konfiguracji. Aby wygenerować raport, wystarczy wydać polecenie:
sarg –x
Gotowe pliki będą znajdowały się w folderze, którego ścieżkę podawaliśmy przed chwilą.
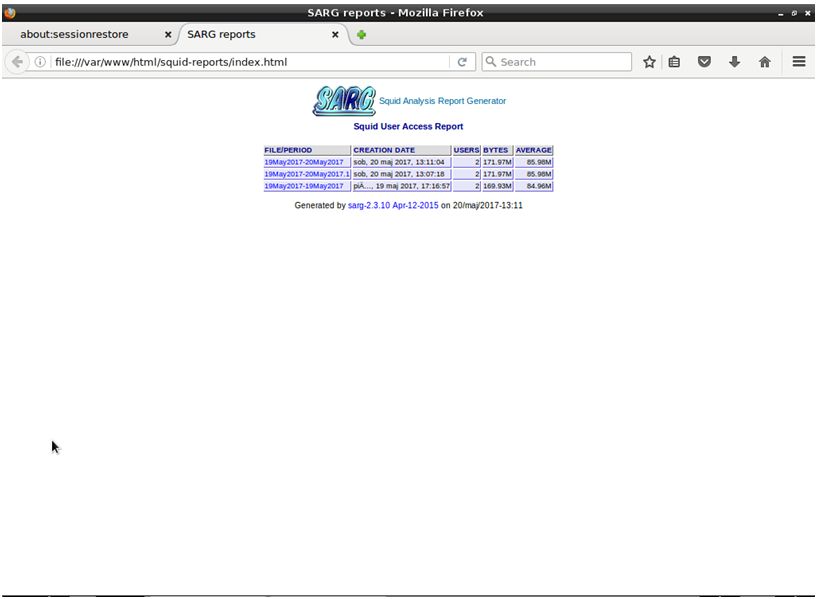
Główny plik, index.html zawiera spis wygenerowanych raportów wraz z datami ich wykonania.
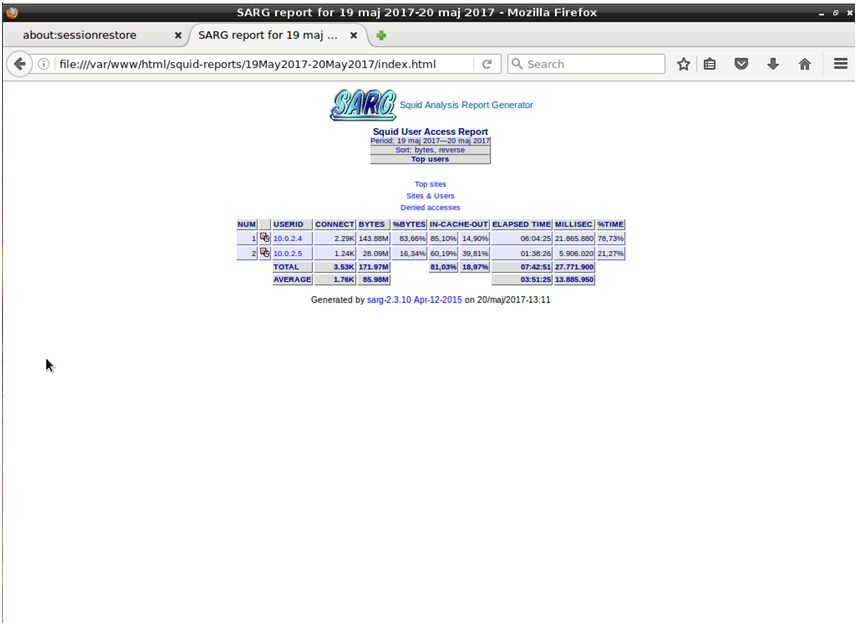
Po wybraniu konkretnego raportu widzimy podział ze względu na użytkowników (wg adresów IP). Możemy się dowiedzieć, ile transferu wykorzystał każdy z komputerów, oraz ile czasu spędził w globalnej sieci.
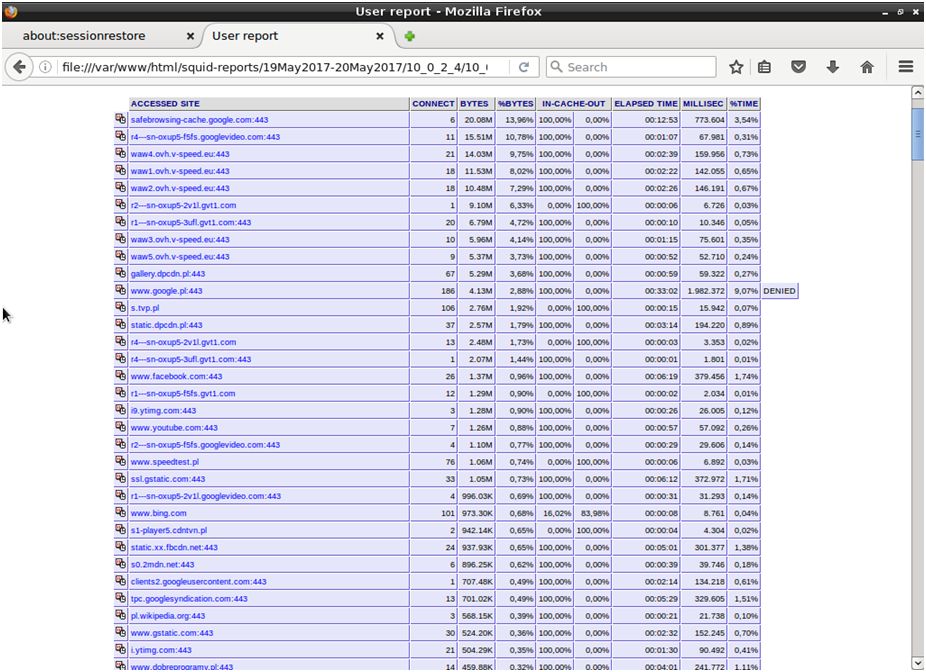
Po wybraniu konkretnego komputera możemy dowiedzieć się, jakie strony były na nim przeglądane w danym przedziale czasu. Wiemy także, ile pasma zużyła każda ze stron. Cron Jeśli chcemy, aby sarg był uruchamiany automatycznie, musimy dodać odpowiednie wpisy do crontab. Np.: aby sarg był uruchamiany codziennie, należy w katalogu /etc/cron.daily utworzyć plik sarg o następującej treści:
#!/bin/sh /usr/local/bin/sarg –d day-1
Następnie należy nadać odpowiednie uprawnienia za pomocą polecenia chmod
chmod 755 /etc/cron.daily/sarg
To już koniec
Poznaliśmy kilka szczegółów dotyczących konfiguracji squid. Dowiedzieliśmy się, jak zostać „cenzorem” naszej domowej sieci. Wiemy także, jak kontrolować, jakie strony są przeglądane przez użytkowników naszej sieci. W następnej części (która pojawi się w bliżej nieokreślonym czasie) poznamy znacznie więcej ciekawych smaczków konfiguracyjnych squid.





![Tania optyka do wideokonferencji. Kamerka Logitech Brio 100 [Recenzja]](https://v.wpimg.pl/NmE2LmpwYQwkUDpeXwxsGWcIbgQZVWJPMBB2T19Cd1o9AX1bXwMrDi0cOx0TEyBDNV5jBB0QYVUgVn9ZERR_QH0Kf15dQ3cJIR8uXRRAY11yBC5fQhR8W3NTekMaBylPOA)

![Minimalistyczna klawiatura bezprzewodowa. Logitech Pebble Keys 2 [Recenzja]](https://v.wpimg.pl/Y2Q1LmpwdlMwUzpeXwx7RnMLbgQZVXUQJBN2T19CYAUpAn1bXwM8UTkfOx0TEzccIV1jBB0QdlRpBXtdRU46H2FQLlhdQzxTYxwuVUJBdABiUi9UQxY7VjJVeUMaBz4QLA)
![Bezprzewodowe słuchawki z ANC dla graczy. HATOR Phoenix 2 [Szybki test]](https://v.wpimg.pl/ZGRkLmpwdSYzCTpeXwx4M3BRbgQZVXZlJ0l2T19CY3AqWH1bXwM_JDpFOx0TEzRpIgdjBB0QdSJrXXVaSEduamNYLghdQz5zY0YtXRVPdyFnWHVdSBU8czYPKEMaBz1lLw)