

Czkawka 4.0.0 - Czyszczenie danych, memów, zdjęć, zbędnych plików
Ostatnimi czasy wydałem kolejną wersję mojej aplikacji do czyszczenia systemu danych i systemu, która jest dostępna za darmo na Linuxa, Windowsa i MacOS.
Opisywałem ją już kiedyś na łamach portalu - wpis , ale że minęło już trochę czasu i aplikacja pozmieniała się nieco, więc postanowiłem przedstawić z grubsza zmiany począwszy w nowej wersji.
Program można pobrać tutaj(pliki są wzięte prosto z CI, ale można dla pewności samemu skompilować kod), a w przypadku wystąpienia problemów przy próbie uruchomienia należy kierować się tą instrukcją(po angielsku niestety).

Aplikacja pozwala znaleźć:
- Duplikaty plików
- Największe pliki
- Puste foldery i pliki
- Podobne wizualnie obrazy, które różnią się znakiem wodnym, rozmiarem, kolorami etc.
- Podobne pliki wideo
- Pliki tymczasowe - tylko najbardziej podstawowe, polecam BleachBit dla bardziej zaawansowanego szukania
- Muzykę z identycznymi tagami - nazwą, rokiem czy artystą
- Niepoprawnymi dowiązaniami - wykrywa linki symboliczne wskazujące np. na nieistniejące ścieżki
- Uszkodzone pliki - na chwilę obecną wspiera wyszukiwanie obrazów oraz archiwów zip
Nowe funkcje
Podobne Wideo
Jedną z głównych nowości jest opcja wyszukiwania zduplikowanych filmów.
W programie wychodzę z założenia że nie warto wymyślać koła na nowo, więc wykorzystuję już obecną w ekosystemie Rusta bibliotekę.
Do działania potrzebny jest FFmpeg, lecz całe szczęście jest on opcjonalny i w razie gdyby go nie było w systemie to nie będzie działał tylko ten jeden tryb.
Jeśli dobrze rozumiem, to zasada działania algorytmu jest dość prosta, mianowicie z pierwszych 30 sekund wideo(krótsze obecnie nie są wspierane) są tworzone w identycznych interwałach czasowych obrazy tego co znajduje się na danych klatkach.
Następnie dla każdego obrazu tworzony jest hash perceptualny, który jest porównywany z innymi(dwa podobne obrazy generują podobny hash).
Jednym z ograniczeń biblioteki którą używam jest niestety to, że wideo muszą być podobnej długości +‑5%.
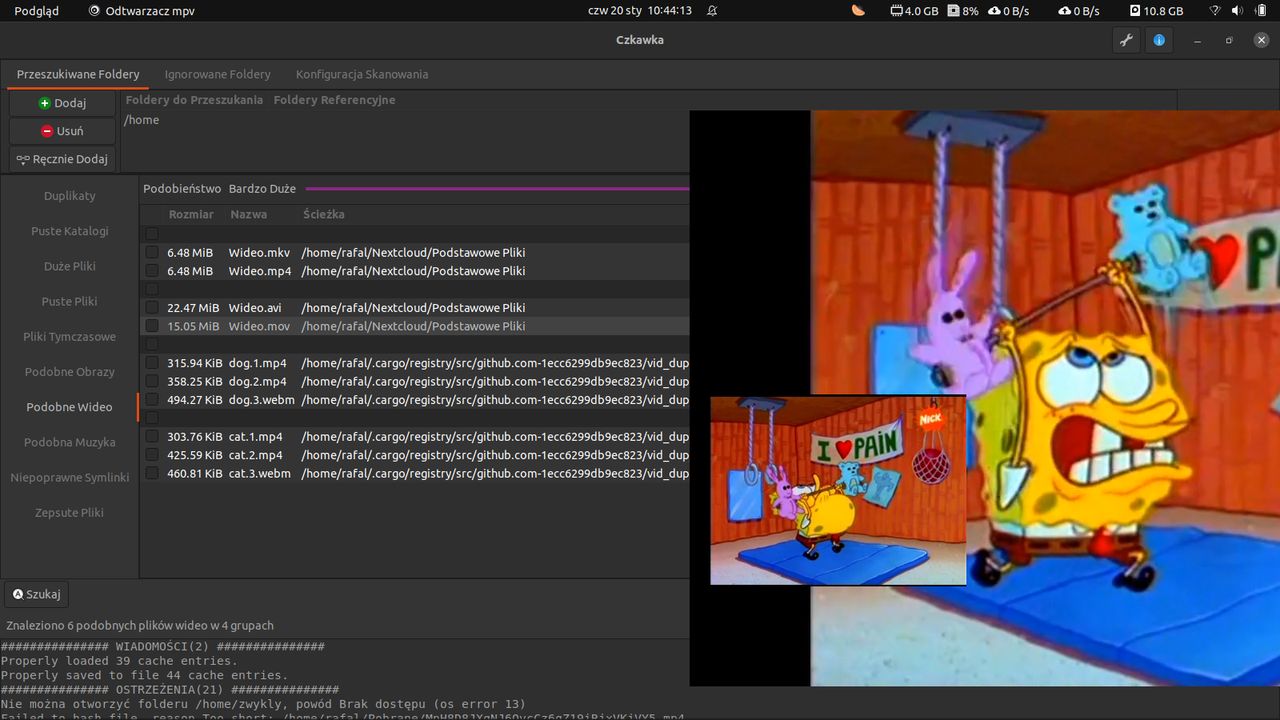
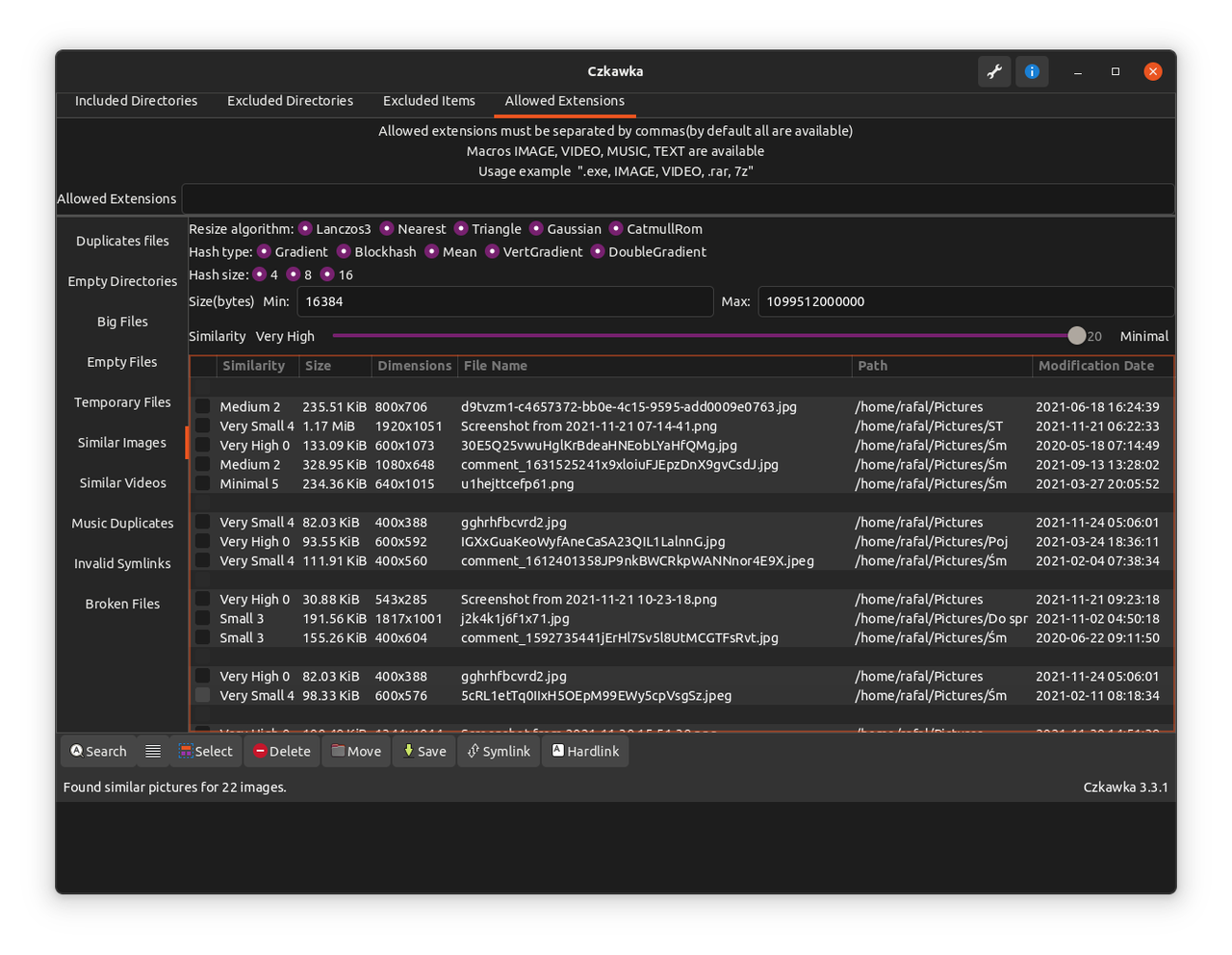
Porównywanie obrazów
Ostatnią większą funkcją którą zdążyłem zaimplementować, jest możliwość porównywania obrazów. Aby uprościć implementację, postanowiłem dodać do niej tylko najbardziej podstawowe opcje takie jak przechodzenie między grupami, obrazami czy zaznaczanie rekordów. Przy przełączaniu grup, dla każdego rekordu generowany jest pogląd(500x500 pikseli) oraz miniaturka(100x100 pikseli), przez co po początkowym ładowaniu, późniejsze przełączanie obrazów w danej grupie powinno następować natychmiast.
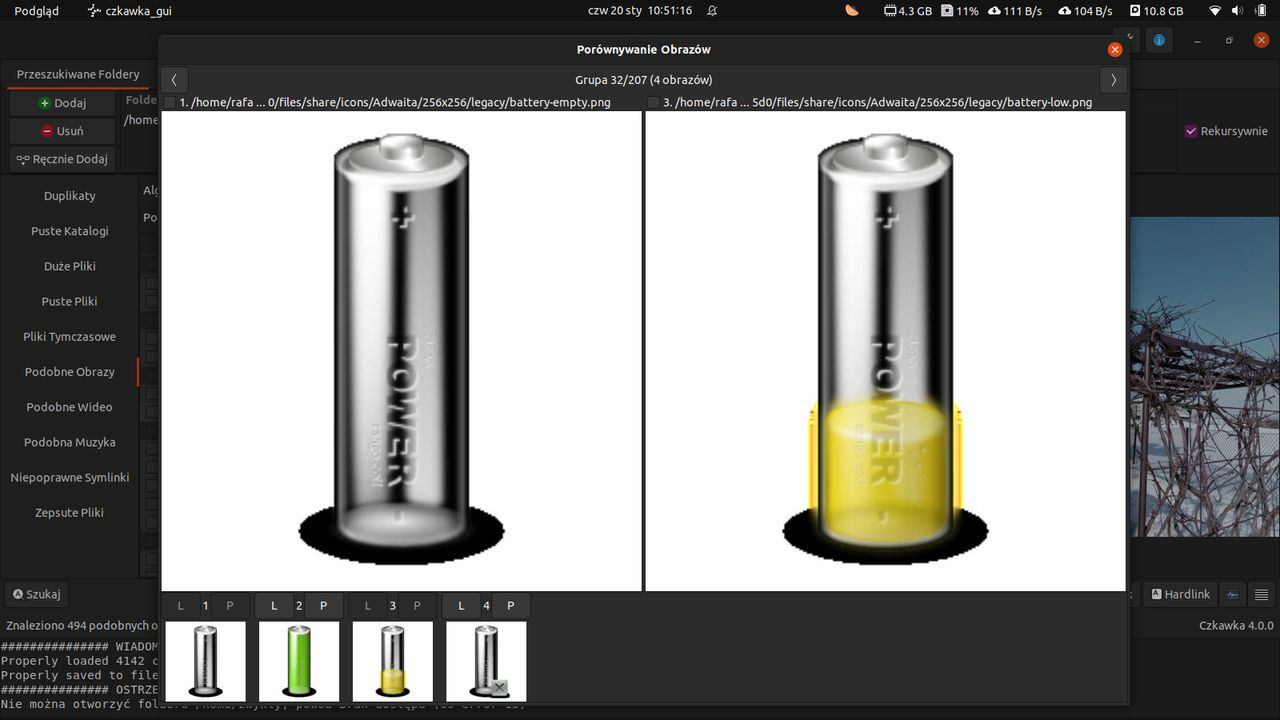
Implementacja tego narzędzia korzysta z dość specyficznych obejść problemów np. z racji braku funkcji do konwersji DynamicImage(z biblioteki Image-rs) do PixBuf lub Image(z biblioteki GTK) muszę zapisać go do pliku korzystając z typu DynamicImage a następnie wczytać go za pomocą funkcji typu Image.
Tłumaczenie
Czymże byłaby aplikacja stworzona przez Polaka bez wsparcia dla języka polskiego?
Z racji, że program staje się coraz bardziej popularny w krajach nieanglojęzycznych, w tym również Polsce, postanowiłem pomóc nieco mniej biegłym w językach obcych użytkownikom.
Oficjalnie wspieranymi językami są język angielski oraz oczywiście polski, jednak z pomocą użytkowników również możliwy do wyboru język włoski i francuski oraz szereg języków tłumaczonych maszynowo tj. chiński czy rosyjski.
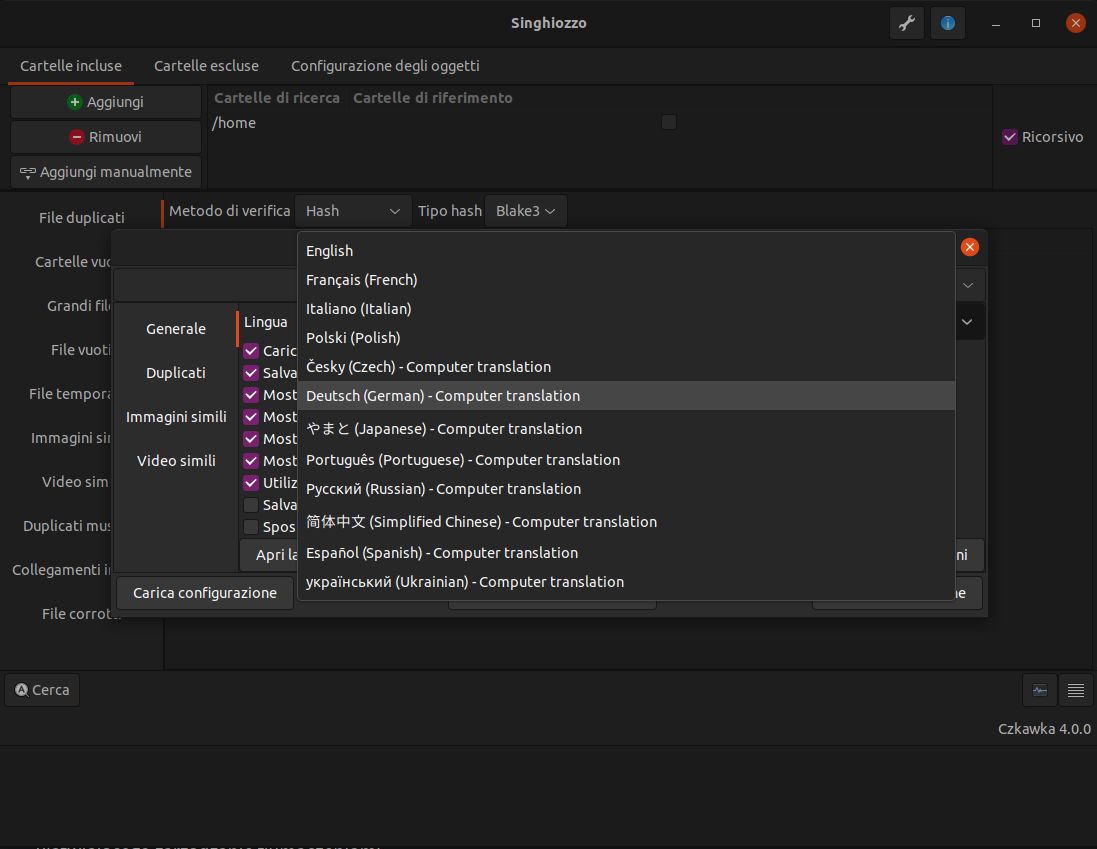
Do tłumaczenia korzystam z projektu Fluent stworzonego przez Mozillę, za pomocą którego w plikach tekstowych w formacie "klucz" = "tekst" zapisywane są dane. Umożliwia ono całkowite wbudowanie tłumaczenia do pliku binarnego.
Z racji że tworzenie, modyfikacja i utrzymanie tych plików aktualnych byłoby nie lada wyzwaniem, to postanowiłem skorzystać z całkiem przydatnego serwisu Crowdin ułatwiającego zarządzanie tłumaczeniami.
Wydajność
Projekt tworzony jest głównie przeze mnie gdyż jestem autorem ponad 90% commitów, jednak od czasu do czasu niektórzy użytkownicy postanawiają mi pomóc, tworząc sami poprawki.
W kwietniu poprzedniego roku stworzyłem podstawową wersję wyszukiwania plików do sprawdzenia wykorzystującą wiele wątków.
Działało to w następujących krokach:
- Biblioteka ignore, wyszukiwała wielowątkowo pliki
- Dla każdego wyszukanego pliku zapisywane były dane o nim do pamięci jeśli był on poprawny(np. nie był wykluczony przez użytkownika)
- Na końcu wyniki były łączone
Dzięki wykorzystaniu tego algorytmu, na 4 rdzeniach wydajność wyszukiwania plików SPADŁA o połowę XD.
Drugie podejście wykorzystujący podobny algorytm i kolejki wiadomości nie spowodowało żadnej widocznej poprawy.
I tutaj pojawił się nasz rodak, cały na biało. Stworzył implementację przy użyciu biblioteki Rayon, w której foldery były w grupach(wielkości liczby wątków w procesorze) przetwarzane w iteracjach. W każdej kolejnej iteracji, były sprawdzane foldery znajdujące się bezpośrednio pod nimi.
Dzięki temu na dyskach HDD, wyszukiwanie plików do późniejszego sprawdzenia na procesorze i7 4770(4/8 HT) zostało skrócone dwukrotnie a w przypadku SSD, przyspieszenie było w granicach 2,5‑3,5x.
GTK 4
W tej wersji przy pracy z GUI, skupiłem na uproszczeniu przyszłej aktualizacji interfejsu do GTK4.
Na początku rozwoju projekty, zwłaszcza jeśli te tworzone przez jedną osobę, przypominają luźno połączone śliną klocki i tak też było w przypadku Czkawki.
W miarę czasu odkryłem, że jeśli chcę zaktualizować aplikację do GTK 4, to muszę postępować z "dobrymi praktykami" ponieważ wszelkie odejścia od reguł, skutkowały błędami kompilacji.
Aplikacja po testowej konwersji w obecnym stanie działa w większości poprawnie, jednak występują błędy tj. puste okno ustawień.
Głównymi powodami dla których wstrzymuję się ciągle z konwersją są:
- brak CI od Githuba ze wsparciem GTK 4 - obecnie wspierane jest jedynie Ubuntu 20.04 z GTK 3, a plików stworzonych przez CI używam jako oficjalnych binarek. Jako ciekawostkę dodam że na Windowsa i MacOS jest już możliwy automatyczny eksport aplikacji z GTK4 z poziomu CI.
- brak alternatywy dla Glade - Tworzenie całego GUI za pomocą kodu jest czym czego nie mogę do końca pojąć i z tego też powodu korzystam z Glade. Cambalache, który jest jego następcą, ciągle nie jest tak łatwy w obsłudze i posiada nadal pełno błędów jednak prace nad nim idą pełną parą, dlatego myślę że w przeciągu pół roku będę mógł go użyć bez większych problemów
Pamięć podręczna dla nieobecnych plików
Domyślnie Czkawka podczas każdego skanowania usuwa z pamięci podręcznej hashe, które nie istnieją już w systemie plików. Pomaga to w utrzymaniu rozsądnego czasu ładowania i zapisywania rekordów do pamięci podręcznej. Niektórzy użytkownicy jednak dodawali, że często sprawdzają oni pliki na dyskach zewnętrznych i po odpięciu takiego dysku, Czkawka usuwa informacje na temat przeskanowanych plików.
Dla tych użytkowników przygotowałem opcję nie usuwania takich rekordów. Może to powodować powstawanie nawet kilkudziesięciu MB pamięci podręcznej która może spowolnić każde skanowanie o kilka sekund. Dostępne są też więc przyciski do ręcznego czyszczenia pamięci, gdy użytkownik przygotował się na to podpinając wszystkie potrzebne dyski do komputera.
Foldery referencyjne/źródłowe
Funkcją, która była bardzo przez użytkowników oczekiwana, jest możliwość ustawiania folderów referencyjnych/źródłowych. Jest ona znana mi np. z programu Dupeguru i działa ona na zasadzie takiej, że foldery do przeszukania dzieli się na 2 grupy - foldery źródłowe oraz zwykłe. W wynikach wyszukiwania pojawiają się rekordy z folderów źródłowych jako nagłówki niemożliwe usunięcia a jako zwykłe wyniki pojawiają się zduplikowane rekordy z reszty folderów.
Inne zmiany
Z racji że akurat podczas tworzenia tej wersji miałem nieco więcej czasu to udało mi się zaimplementować więcej przydatnych rzeczy tj.
- ukrywanie górnego panelu i zmniejszenie wielkości GUI - obecnie większość ekranu może zajmować główny ekran z rekordami/podglądem obrazu
- refaktoryzacji GUI - w niektórych miejscach w aplikacji kod był zduplikowany(np. 7 bardzo podobnych funkcji) a przy jego modyfikacji czasami pojawiały się problemy spowodowane np. roztargnieniem. Obecnie większość funkcji, tam gdzie tylko możliwe, została zunifikowana i ryzyko błędu przy modyfikacji interfejsu jest teraz o wiele niższe.
- błędne pliki również są zapisywane do pamięci podręcznej - dzięki temu nie będzie trzeba w kółko przy każdym skanowaniu sprawdzać tych plików(nie były one nigdy zawarte w wynikach skanowania)
- zaznaczanie obiektów za pomocą Regexa - użytkownik może teraz zaznaczać rekordy za pomocą regexów z języka Rust
- możliwość sortowania rezultatów w niektórych trybach
Projekt w sieci
W zasadzie to już nawet rok temu mógłbym porzucić rozwój projektu, ponieważ zawierał wtedy wszystkie funkcje których brakowało mi po usunięciu FSlint z repozytoriów Ubuntu.
Jednak z racji że projekt stał się bardzo popularny(ponad 5500 gwiazdek na Githubie) to postanowiłem w dalszym ciągu się nim zajmować(jako twórcę cieszy mnie, że tyle osób uznało program za warty uwagi).
Aplikacja pojawiła się w szeregu zagranicznych artykułów tj. Xataka, Ubuntu Handbook, DesdeLinux, Ghacks, Moongift czy LinuxLinks.
Co dziwniejsze jest obecna i rekomendowana na stronie Privacy Tools mimo braku funkcji typowo zapewniających prywatność użytkownikom.
Linki
Repozytorium z kodem - https://github.com/qarmin/czkawka
Pliki do pobrania - https://github.com/qarmin/czkawka/releases
Strona z tłumaczeniami - https://github.com/qarmin/czkawka
![Kosztowna i mało wydajna drukarka mobilna do zdjęć. Canon Zoemini 2 [Recenzja]](https://v.wpimg.pl/OGYzLkpQYCY4GDpYXyptM3tAbgIZc2NlLFh2SV9kdnAhSX1dXyUqJDFUOxsTNSFpKRZjAh02YHFpSnsJEjAsajsYKQhdZS5wOlcuDhNmYiNhTi9ZSTN9I2Ecf0U6AQhlJA)


![Bezprzewodowy odkurzacz 5 w 1 z funkcją mopowania. JIMMY PW11 Pro Max [Recenzja]](https://v.wpimg.pl/NmZkLkpQYQw7CTpYXypsGXhRbgIZc2JPL0l2SV9kd1oiWH1dXyUrDjJFOxsTNSBDKgdjAh02YQloDi8JQGUoQGJceVJdZX5cb0YtDhVjY1pjWCldQTQrCGwNKEU6AQlPJw)
![Szybki i kompaktowy dysk SSD na USB-C. ADATA SC750 (2 TB) [Recenzja]](https://v.wpimg.pl/OWU5LmpwYDY0VzpeXwxtI3cPbgQZVWN1IBd2T19CdmAtBn1bXwMqND0bOx0TEyF5JVljBB0QYGJgBXhdEUYsemJXdVldQ31gNxguWENAYmIzUHQJQE4rNGxQdUMaByh1KA)


![Wytrzymały i szybki dysk SSD z USB-C. ADATA SC740 (2TB)[Recenzja]](https://v.wpimg.pl/ODRkLmpwYCUzCTpeXwxtMHBRbgQZVWNmJ0l2T19CdnMqWH1bXwMqJzpFOx0TEyFqIgdjBB0QYHI0WXpYFBYqaWBYe1tdQyknYUYtCBFBYndhXXxbQBQsfGpfKEMaByhmLw)